聚类分析(K |
您所在的位置:网站首页 › spss聚类怎么做 › 聚类分析(K |
聚类分析(K
|
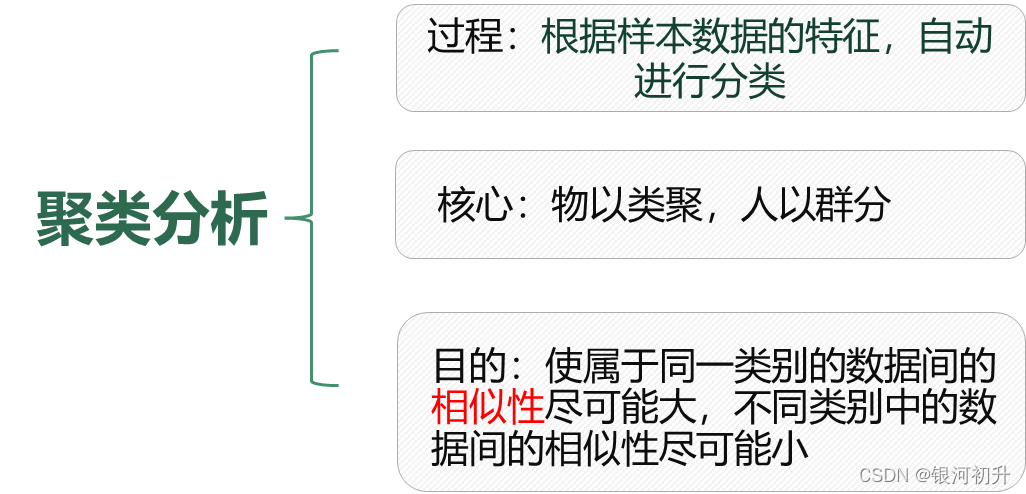
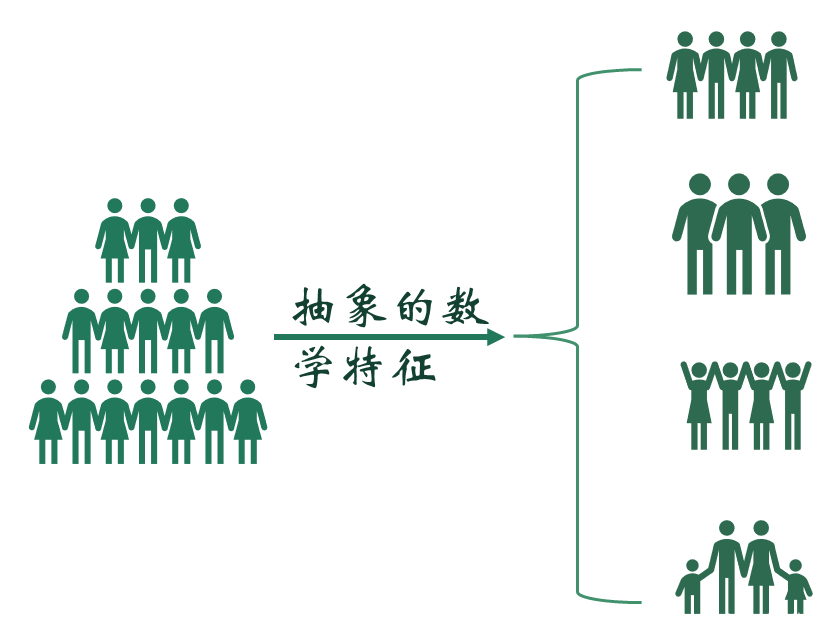
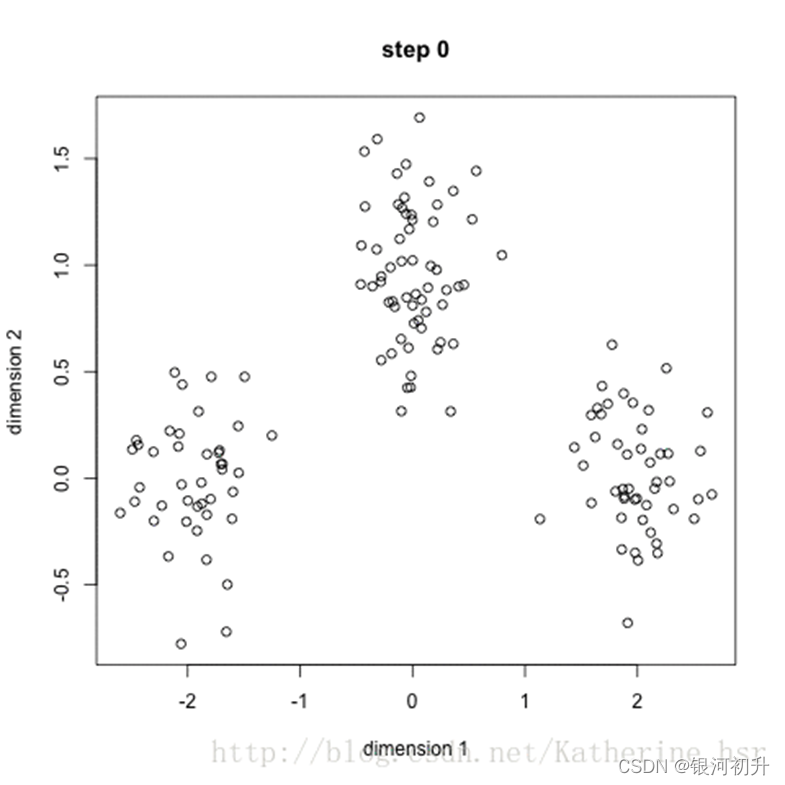
目录 聚类分析的定义及原理 聚类方法及其在SPSS中的实现 总结及拓展 聚类分析的定义及原理 1.定义所谓物以类聚、人以群分。聚类分析,即是基于研究对象的特征,将他们分门别类,以让同类别的个体之间差异相对小、相似度相对大,不同类别之间的个体差异大、相似度小。 聚类分析是一种探索性分析方法,与判别分析不同,聚类分析事先并不知道分类的标准,甚至不知道应该分成几类,而是会根据样本数据的特征,自动进行分类。 聚类与分类的不同在于,聚类所要求划分的类是未知的 假定研究对象均用所谓的“点”来表示。 在聚类分析中,一般的规则是将“距离”较小的点归为同一类,将“距离”较大的点归为不同的类。 常见的是对个案分类,也可以对变量分类,但对于变量分类此时一般使用相似系数作为“距离”测量指标。 一般的规则:
聚类方法及其在SPSS中的实现 1.主要的聚类方法:
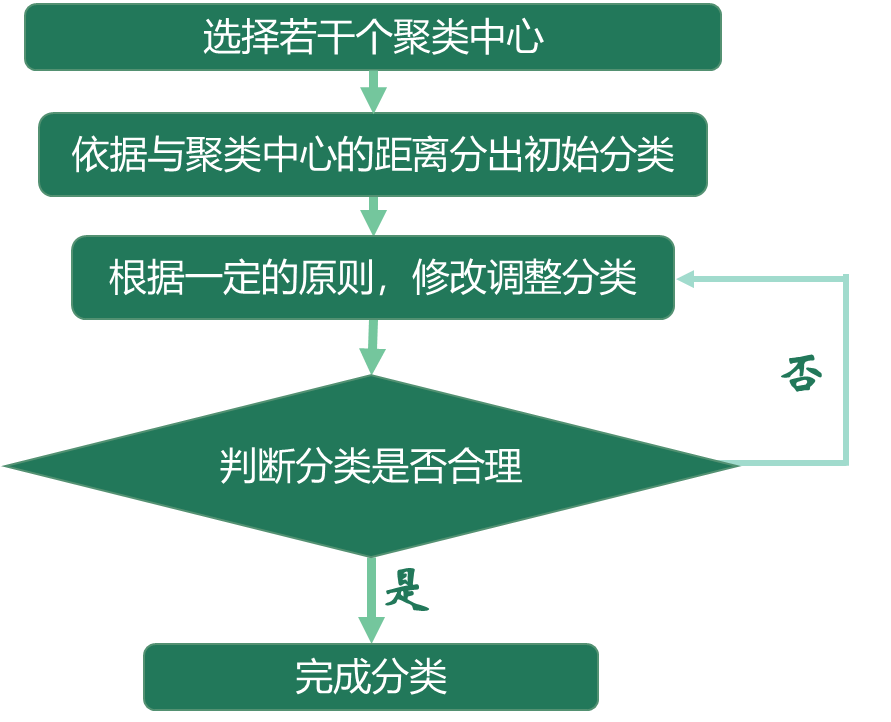
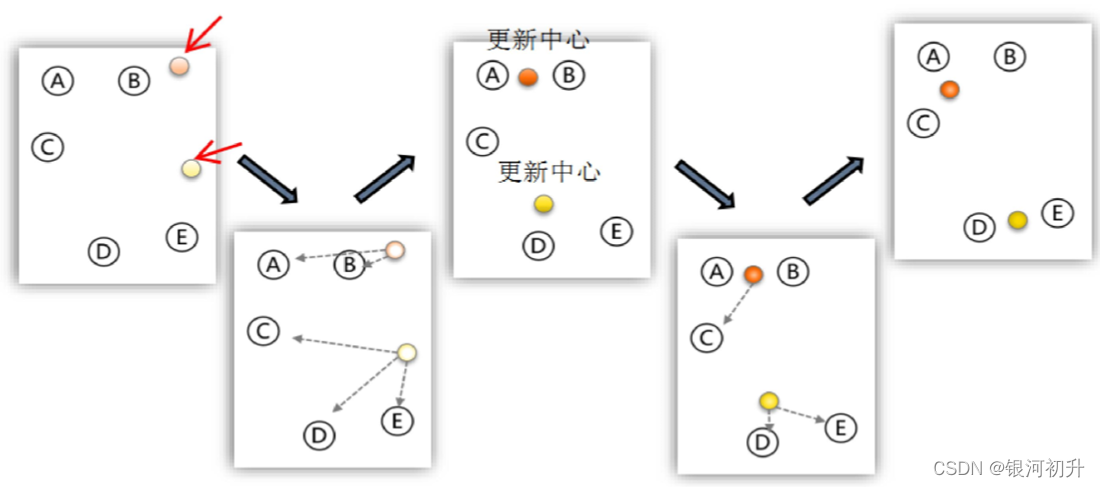
又称为快速聚类(K-Means Cluster),是在聚类的类别数已确定的情况下,快速将其他个案归类到相应的类别,适合大样本数据的聚类。 具体步骤如下:
距离计算规则(欧几里得距离公式):
图解:
K-means的优缺点: 优势: (1)原理比较简单,实现也很容易,收敛速度快。 (2)在对大规模数据集进行聚类分析时,算法聚类较高效且聚类效果较好。 (3)簇与簇之间区别明显时,它的聚类效果很好。
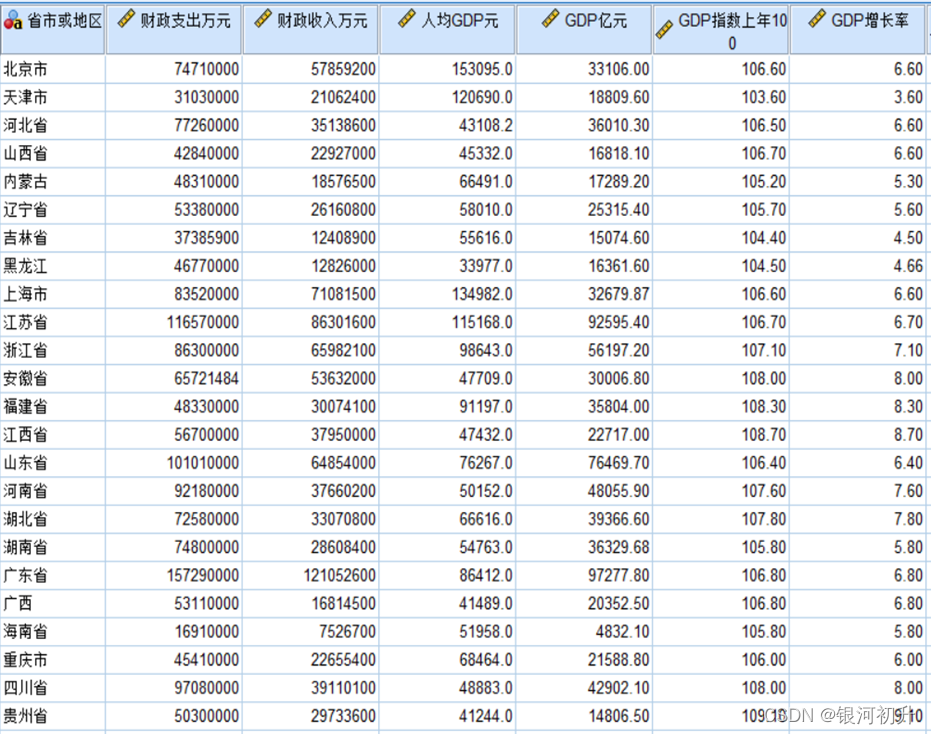
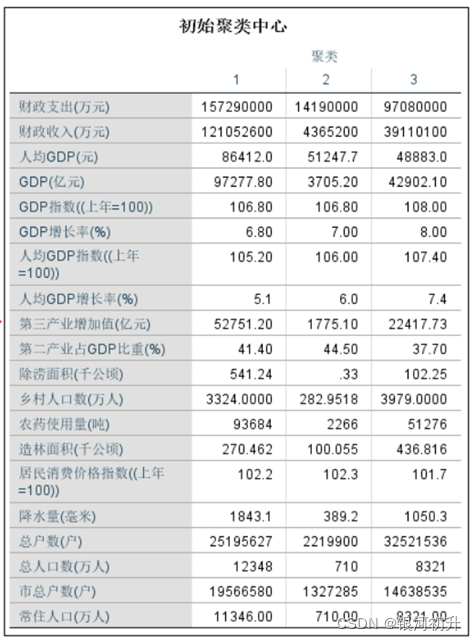
不足: (1)分类数从初始分类开始就确定不变了,所以要求事先要对样本有足够的了解。 (2)仅限于个案间的聚类(Q型聚类),不能对变量进行聚类。 (3)个案间的距离的测量方法使用的是欧式距离的平方,因此只能对连续变量进行聚类。 案例分析(SPSS): 通过查询整理出了2018年我国各省份的20项基本情况,根据这些指标把这31个省市或地区分成3类。
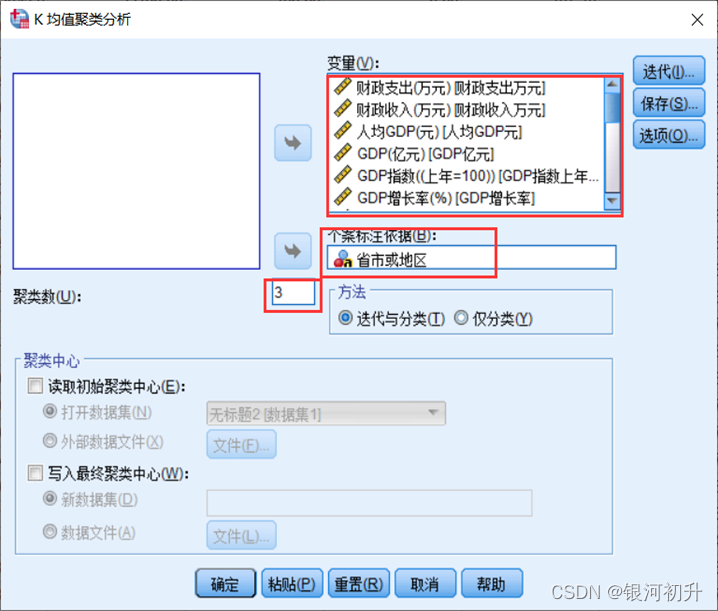
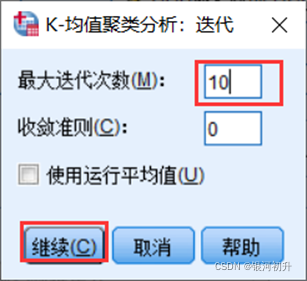
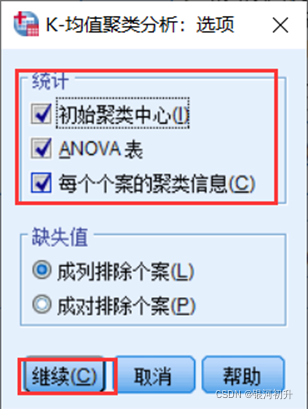
分析步骤:分析>>分类>>K-均值聚类>>迭代>>次数>>选项>>勾选统计>>确认
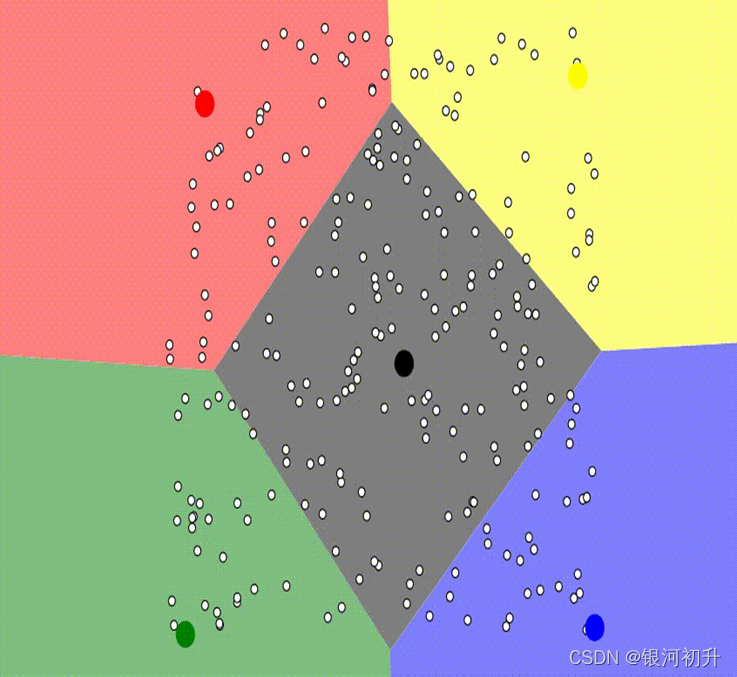
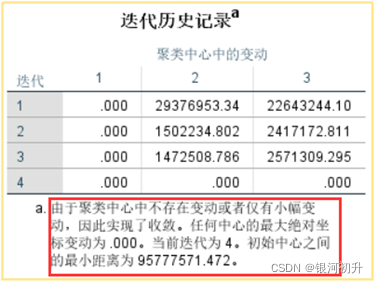
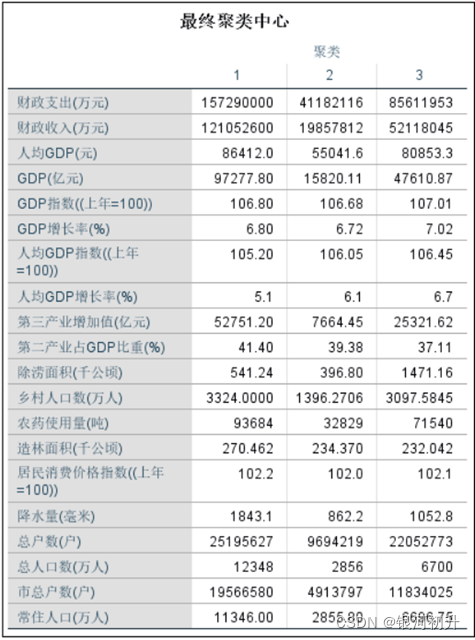
结果分析:
若不收敛则调大迭代次数
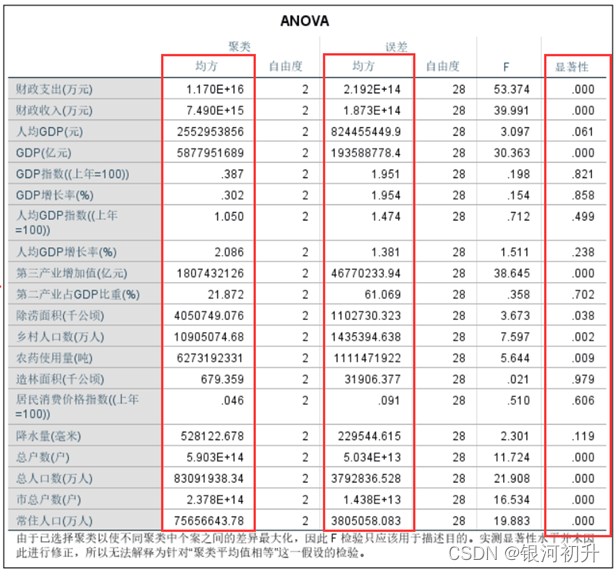
方差分析表:
其中聚类均方对应组间均方差,误差均方对应组内均方差,显著性p |





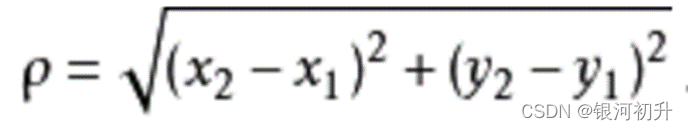
【本文地址】