SPSS 期末复习(未完成) |
您所在的位置:网站首页 › spss导出sav数据集 › SPSS 期末复习(未完成) |
SPSS 期末复习(未完成)
|
考试范围
SPSS 数据管理 数据的基本统计分析
数据的描述性分析(描述指标、统计图表)定量数据的基本统计推断(t 检验、方差分析)定性数据的基本统计推断(卡方检验、Fisher 确切概率法、OR/RR 及其置信区间)非参数检验简单回归与相关分析
多元统计分析
多重线性回归分析Logistic 回归分析生存分析、Cox 回归分析
实例应用
复习重点
t 检验方差分析卡方检验非参数检验简单回归与相关分析多重线性回归分析Logistic 回归分析生存分析Cox 回归分析实例应用
复习办法
遍历 PPT网课资源重难点追个突破总结一份操作指南
遍历 PPT
IBM SPSS Statistics 软件简介和应用入门
数据集的结构和创建方式:变量名、变量类型、标签、值标签、缺失值、测度类型数据文件的合并和拆分纵向数据宽型结构和长型结构之间的相互转换
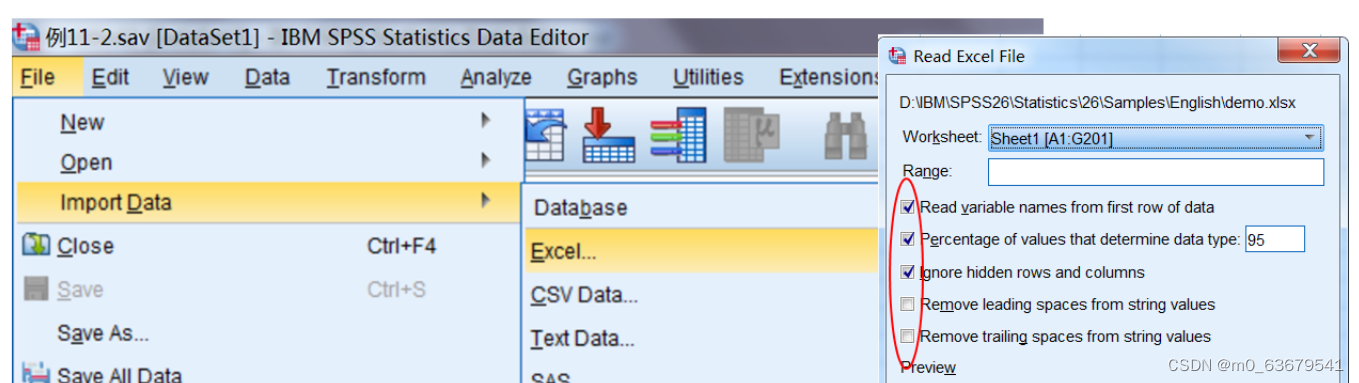
常用统计软件:SPSS SAS STATA R Epi-Info SPSS:全称 社会科学统计软件包 或 统计产品与服务解决方案 界面与菜单: 界面上有菜单栏、工具栏、状态栏(变量视图和数据视图); 新建文件有四个主要窗口,分别是数据编辑窗口(Data)、语法编辑窗口(Syntax)、结果输出窗口(Output)(结果文件为 *.spv)、脚本编辑窗口(Scripts) 数据文件创建的四种方法: 新建数据文件直接打开已有数据文件:*.sav *.sys *.xls *.sas7bdat *.txt 等使用数据库查询:与大型数据库进行数据交换,如 SQL,Oracle,也适用于 Excel从文本向导导入数据文件从 Excel 中导入文件:
注释:从表的第一行读取变量名、确定数据类型的值的百分比(95%)、忽略表中隐藏的行和列。 SPSS 数据文件是一种有结构的数据文件,包括文件结构和数据。在软件中创建好数据后,首先应该进行 数据文件的属性定义 或者 结构定义。 变量名 中英文字母不区分大小写,首字符为 $ 的为系统变量名,总长度不能超过 64 个字符(或 32 个汉字) 变量类型 分为数值型、字符型和日期型 缺失值 系统缺失值指没有明确数值的变量,对数值型变量,系统用 “.” 表示,系统缺失值不参与统计分析。用户缺失值是用户自定义的,如调查问卷中年龄不详用 999 表示,分析时需要将其定义为缺失值,否则会引入计算错误。 变量测度 分为尺度变量(Scale)、名义变量(Norminal)、有序变量(Ordinal)。其定义会对以下分析产生影响:某些统计分析时对话框内的变量列表;统计制表和制图,以及描述指标的选择,名义变量和有序变量按照分类变量处理;决策树分析。 变量角色(Role)某些对话框支持可用于预先选择分析变量的预定义角色。当打卡其中一个对话框时,满足要求的变量将自动显示在目标列表中。包括 输入、目标、两者、无、分区(变量将用于将数据划分为单独的训练、检验和验证样本)和拆分。缺省情况下,SPSS 为所有变量分配输入角色。 创建数据集的注意事项: 数据应整理为二维表研究对象必须有唯一编号,便于索引、标记和数据核查分类变量应事先统一编码,录入数据时以编码录入,将变量定义为数值型,测度类型为名义型操作1——定义变量标签和值标签 变量视图下 Values 列找到变量,点击打开值标签窗口,逐个填入相应的值和标签,添加即可。 操作2——为变量重新赋值(例如把 female 赋值为 1, male 赋值为 2) 菜单栏 转换 > 重新编码为相同变量 给 “性别” 重新赋值后,可将变量类型更改为 “数值型”,并添加值标签。 数据结构可以复制粘贴: 按照变量及赋值列表,在 SPSS 中创建数据集的结构用 SPSS 打开 Excel 数据表,产生新数据文件。该文件的变量名为 Excel 里的第一行变量名或 SPSS 自动生成的 Var0001、Var0002……,且无变量标签和值标签将第一步创建的数据集结构(变量视图中选中全部内容)复制,至新数据文件中选中变量视图中相应的位置,粘贴操作3——关于日期变量的运算——可用于生存分析 1、转换 > 计算变量 日期函数 DATEDIFF(datetime2, datetime1, "unit"),计算 datetime2 - datetime1 产生一个数值变量,"unit" 有多种选择(年月日时分秒、周、季度)。 2、转换 > Date and Time Wizard Calculate with dates and times > next > Calculate the number of time units between two dates > next > 导入日期变量,选择 “unit”,下方的结果处理栏中可以选中截断为整数 > next > 为生成的结果变量创建变量名和标签 数据文件的合并和拆分 合并: 1、纵向合并,追加记录 Data -- Merge Files -- Add cases Unpaired variables 中显示两个数据文件中不一致的变量 2、横向合并,追加变量 Data -- Merage Files -- Add variables 拆分: Data -- Split into files(拆分为文件) Options 里可以选上 “使用文本作为文件名的第一部分” ,Prefix test 例如可以填写 Gender SPSS 数据的核查与分析准备 隐私保护数据核查离群值的识别统计分析的数据准备数据核查 1、检查变量的类型和性质 2、核查变量值范围,识别非法值或异常值 (1)对每个变量逐一进行描述 对字符型、数值型(名义、有序)变量,汇总频数,列频数表,观察频数分布 连续型数值变量(Scale),找出最大、最小值,计算均数、标准差;划分组段,编制频数表,观察频数分布。 (2)根据各变量的频数分布及范围,判断有无非法变量值或异常值,对其进行修正和整理。 SPSS 实现:光标放在所在该变量列的任意位置,点击鼠标右键 > 选择 Variable Information 或 Descriptive Statictics 3、一致性检查——对变量间的关系进行逻辑检错 SPSS 实现:交叉列联表、逻辑运算等,具体情况具体分析 4、唯一性检查——识别重复观测 SPSS 实现:Data -- Identify duplicate Cases 5、完整性检查——数据缺失比例 SPSS 实现: Analyze -- Missing Value Analysis 6、多个数据文件的交叉检查 SPS 实现:通过两个文件的合并,若同一观测信息不一致,合并后则保留两条记录,再通过查重进行对比 离群值或异常值的识别 目测法:频数表、直方图、箱式图z 值法(标准化):z 为该值 减均数除以标准差 的结果,z 绝对值大于 3 可视为异常值四分位数间距法:小于下四分位数(Q1)减 1.5 倍四分位距(IQR,上下四分位数之差 Q3 - Q1)或大于 Q3 + 1.5 IQR统计学检验法:Grubbs 检验、Tietjen-Moore 检验、Dixon 检验等等数据文件的其他基本操作 增删变量和观测检查离群值:Data -- Identify Unusual Cases定义新变量:转换 > 计算变量产生哑变量:转换 > 创建哑变量 SPSS统计描述为什么?背景信息,帮助理解数据。 数据集的特征:研究设计、数据来源、 数据代表性、相关知识 变量分布:图表 > 指标 > 函数(密度函数、分布函数)> 数字特征 统计分析常犯错误: 进行统计分析前不对数据进行整理和归纳乱用各类统计方法(应注意各类方法的使用条件)对分析结果输出的图表不知道其统计意义和实际意义描述性统计分析 统计分析的目的:研究总体的数量特征 首先需要了解数据的整体情况,两种方式实现 1、数值计算,计算常用的基本统计量的值,准确反映数据的基本统计特征 2、图形绘制,展现数分布特点 数据的基本统计指标: 定量数据:均数、标准差、标准误等;计数或分类数据:频率、比率等 分析 -- 描述统计,频率:产生频率表;描述:一般性统计描述;探索:对数据概况不清时的探索性分析;交叉表:分类变量的一般描述和检验 在探索分析中,分别利用 Kolmogorov-Smimov 检验和 Shapiro-Wilk 检验两种方法来确定变量是否服从正态分布,Sig. > 0.05 代表接受零假设,即接受变量服从正态分布的假设。S-W 适用于小样本,推荐样本量为 7~50,K-S 适用于大样本,推荐样本量 > 50。 Q-Q 图(分位数图示法,Quantile-Quantile plot): 以样本分位数为横坐标,以按照标准正态分布计算的相应分位点为纵坐标绘制的散点图。 趋降标准 Q-Q 图: 以样本的实际分位数作为横坐标,分位数残差作为纵坐标绘制的散点图。 反应数据原始分布特征的 5 个统计量: 数据分布中心位置、分布、偏度、变异范围、异常值 操作4——描述性统计资料 透视表 的构建 图表范围内,单击鼠标右键后调出菜单选择 “编辑内容 -- 在单独窗口中” ,出现 “透视表”。双击鼠标左键直接打开 “透视表”。上方菜单 “透视 -- 透视托盘” 。 交叉表 在分析变量之间的关系时,通常分析变量之间的相关程度。对于数值型变量,分析其相关性通常计算相关系数或进行回归分析;对于定类型变量,则通常采用交叉列联表进行分析。 交叉列联表分析主要用于研究离散变量的定类型有无相关性,给出了多个变量在不同取值下的数据分布。在分析中,可对二维和多位列联表(RC表)资料进行统计描述和检验,并计算相应的百分数指标,另外,还可计算 四格表确切概率(Fisher's Exact Test)且有单双侧、对数似然比检验(One-tail、Two-tail)以及线性关系的 Mantel-Haenszel 检验。 分析 -- 描述统计 -- 交叉表 统计描述只需选择 “单元格” 选项,如果需要假设检验,可选择 “精确” 或 “Statistics” 统计表(三线表) Analyze -- Reports -- Case Summaries,右上方按钮 Statistics 。 编辑菜单,options,透视表(Pivot tables), academic 。 双击输出的统计表,单击鼠标右键,表格属性 -- Borders 定义表格线格式,定义完成后,双击输出的统计表,单击鼠标右键,表格外观 -- save look 统计图 观测量分类描述模式——个案组摘要 变量描述模式——各个变量的摘要 观测值模式——个案值(Values of individual cases) 分组条图,Clustered,Summery of separate variables(各个变量的摘要) 分段条图,Stacked,Summery of groups of cases(个案组摘要) 图形 -- 图表构建器 元素属性,设置参数,每个 x 轴类别总量 复式线图 同一变量按照另一变量分类的复式线图: 图形 -- 旧对话框 -- 折线图,图表中的数据为 个案组摘要 多个变量的复式线图: 图表中的数据为 各个变量的摘要 面积图 简单:个案组摘要;堆积:各个变量的摘要 饼图:个案组摘要 P-P 图:以实际观测值的积累频率(X)对被检验分布的理论或期望积累频率(Y)作图。 P-P 图和 Q-Q 图都是用来检验数据是否服从某种分布。 ROC 曲线,检验方向:较小的检验结果表示更明确的检验 t 检验中心极限定理:当样本含量很大时,无论原始测量变量服从什么分布,均数的抽样分布均近似服从正态分布。 t 分布的特征:以 0 位中心,左右对称的单峰分布。t 分布曲线的形态变化与自由度的大小有关,t 曲线为一簇曲线。自由度越小,t 曲线的中间部分越低平,两端越伸展;随自由度增大,t 曲线逐渐逼近正态曲线;t 趋于无穷大,t 曲线为正态曲线。 总体均数的估计(点估计和区间估计)。 假设检验的目的:判断均数差别引起的原因(样本是否来自同一总体) 假设检验的基本步骤: (单/双侧?)建立假设和确定检验水准 > 选定检验方法和确定统计量 > 确定 P 值,作出推断结论 H0:无效假设(均数相等);H1:备择假设 P 值是指 从 H0 所规定的总体中随机抽样时,获得等于及大于(负值时等于及小于)现有样本统计量的概率。所得概率 P > α 时,认为现有样本所代表的总体与已知总体的差别是由抽样误差造成的,不拒绝 H0;……小概率事件发生……,拒绝 H0,接受 H1 假设检验须根据 研究目的、设计类型、资料类型及分布特征 选用适当的统计检验方法,并计算出相应的检验统计量 选用样本均数与总体均数比较的 t 检验的场景: 样本与总体均数的比较;样本是按完全随机设计抽取的数值型变量资料;样本含量较小,总体标准差未知 t 检验适用范围: 样本均数与总体均数比较成组(完全随机)设计的两样本均数比较配对设计的两样本均数比较单样本 t 检验: 样本含量较小(n > 50)时,要求样本来自正态分布总体;n >= 50 时,运用正态分布规律进行参数统计推断。 配对 t 检验: 用于配对设计的两样本均数比较时,n < 50 时,要求差值来自正态分布总体,n >= 50 时,运用正态分布规律进行参数统计推断 两样本 t 检验: 用于成组设计的两样本均数的比较时,n1 < 50 或 n2 < 50,要求两样本分别来自正态分布总体,且两总体方差相等。若两样本量均大于 50,运用正态分布规律进行参数统计推断 正态性检验(小样本): 图示法,P-P 图或 Q-Q 图; 矩法,检验偏度系数和峰度系数; W 检验(Shapiro-Wilk 检验,小样本采用) D 检验(Kolmogorov-Smirnov 检验,通常大样本用(n > 50)用 K-S 检验) 频数分布拟合优度的卡方检验 无效假设 H0:样本来自正态分布总体 操作5——正态性检验 分析 -- 描述统计 -- 探索 “统计” 菜单勾选上 “描述统计”;“图” 菜单勾选上 “按因子级别分组”,带检验的正态图 两独立样本 t 检验(应用条件:正态性、方差齐): 将受试对象随机分配到两组中,每组对象分别接受不同的处理,分析比较两组的处理效应 操作6——两独立样本 t 检验、配对样本 t 检验 分析 -- 比较平均值 -- 独立样本 t 检验(定义组) 分析 -- 比较平均值 -- 配对样本 t 检验(成对变量) Ⅰ类错误,弃真,拒绝实际上成立的 H0,概率 α;Ⅱ类错误,存伪,概率β 1 - β 称为检验效能或把握度,即两总体确有差别时,按 α 水准能识别该差别的能力 方差分析为有效控制 Ⅰ型错误,多个样本均数比较时不应采用 t 检验和正态性检验,而宜用方差分析。 方差分析(ANalysis Of VAriance,ANOVA),以 F 命名其统计量,故方差分析又称 F 检验 三种变异: 1、总变异及自由度 总变异:各样本值不尽相同 原因:处理因素、个体差异和随机测量误差 总变异的离均差平方和(sum of squares,SS)为各变量值与总均数差值的平方和 自由度为 n-1 2、组间变异及自由度 组间变异:各组均数各不相同 原因:处理因素、个体差异和随机测量误差 各组样本均数与总均数差值的平方和,反映各组均数间变异程度;自由度 k-1 3、组内变异及自由度 组内变异:组内各样本数值各不相同 原因:个体差异和随机测量误差 各处理组内观察值与其均数差值的平方和之和;自由度 n-k 总变异等于组间变异加组内变异 F 值为均方之比: F = MS组间 / MS组内;F 值接近 1,没有理由拒绝 H0(各样本总体均数相等) H0 成立时,F 统计量服从 F 分布 方差分析的应用条件: 各样本是相互独立的随机样本各样本来自正态分布总体各总体方差齐方差分析的用途: 两个或多个样本均数间的比较分析两个或多个因素间的交互作用回归方程的线性假设检验多元线性回归分析中偏回归系数的假设检验完全随机设计的方差分析 亦称单因素方差分析(one-way ANOVA),用于完全随机设计的多个样本均数比较的资料,分析不同处理因素间或某处理因素不同水平间有无差异,不考虑个体差异的影响。 先进行多个样本的方差齐性检验和正态性检验。若不满足,可变量变换使数据呈正态或方差齐;仍达不到应用条件,可选用成组设计的多样本比较的秩和检验。 操作7——完全随机设计的方差分析 分析 -- 比较均值 -- 单因素 ANOVA 选项:选上 “方差同质性检验” ,缺失值 “按分析顺序排除个案” 事后多重比较:假定方差齐性栏选上 “LSD,SNK” 随机区组设计的方差分析 (randomized block design),又称配伍组设计,先将受试对象按条件相同或相近组成 m 个区组(或称配伍组),每个区组中有 k 个受试对象,再将其随机分到 k 个处理组中。 随机区组设计的方差分析又称两因素方差分析,是配对设计的扩展,用于随机区组设计的多个样本均数比较的资料,分析不同处理因素间或某处理因素不同水平间有无差异,考虑个体差异的影响。 配对设计与配伍组设计: 通常以影响实验效应的主要非处理因素为配对或配伍条件,该类设计考虑了个体差异的影响,比完全随机设计检验效率高。 操作8——随机区组设计的方差分析 分析 -- 一般线性模型 -- 单变量 模型,主效应 事后多重比较,事后检验,S-N-K 多个样本均数的两两比较 经方差分析,若拒绝 H0,接受 H1,则可以推断 k 组均数不全相同,需进一步明确哪些组间有差异。当基于观察数据同时进行一系列统计学推断或推断多个参数时,会出现多重推断的问题。典型 的问题是多个处理组之间的两两比较。 多重比较方法: 1、证实性研究 Dunnett-t 检验:多个实验组与一个对照组均数差别的比较 LSD-t 检验:多个组中,根据专业,仅进行某一对或某几对在专业上有特殊探索价值的均数间的两两比较 2、探索性研究 SNK-q 检验:任意两两组间均数均进行比较,各比较组样本含量可不相等;对同一样本数据有可能与方差分析的结果并不一致 Tukey 检验:任意两两组间均数均进行比较,要求各样本组间含量相同 Scheffe 检验:既可进行因素水平的平均效应的比较,还可比较因素水平平均效应的线性组合,多用于对比组样本含量不等的资料。整体检验效果与方差分析相同。 3、证实性研究与探索性研究 Sidak t 检验,又称 q 检验,适用于多组样本均数之间两两全面比较,实际中常用 Bonferroni t 检验 交叉设计的方差分析 交叉设计(cross-over design) 在自身配对设计基础上发展起来,考虑一个处理因素(A, B 两水平),两个与处理因素无交互作用的非处理因素(试验阶段和受试对象)对试验结果的影响 操作9——交叉设计的方差分析 分析 -- 一般线性模型 -- 单变量 固定因子(例如阶段和治疗方案): 该因素在样本中所有可能水平都出现了。 随机因子(例如个体编号): 该因素的所有可能取值在样本中没有都出现,或不可能都出现。 模型,定制,主效应 拉丁方设计的方差分析 拉丁方设计 三因素相同水平的设计,同时考虑三个因素对试验结果的影响 要求三因素且水平相等;三因素相互独立且无交互作用;各行、列、字母所得的试验数据的方差齐 操作10——拉丁方设计的方差分析 同操作9,无随机因子 析因实验设计的方差分析 析因实验设计 将两个或多个因素的各水平交叉分组,总的实验组数等于各因素水平数乘积。一般因素不超过 4,水平数不超过 3,常见 2x2,2x2x2,2x2x3x2 不仅可检验各因素内部不同水平间有无差异,还可检验两个或多个因素间是否存在交互作用 2x2 析因设计 两因素析因实验设计用于研究 A, B 两个因素不同内部水平间有无差异,特别是研究两因素间是否存在交互作用的情况 2x2 析因实验设计的方差分析 总处理间变异分解成 A 间、B 间、AxB 三部分 操作11——2x2 析因实验设计的方差分析 分析 -- 一般线性模型 -- 单变量 固定因子: A, B 卡方检验卡方分布只有一个参数 自由度,自由度趋于无穷,卡方分布趋于正态分布 卡方分布用途: 1、直接应用:检验某一分布的实际频数与理论频数是否符合
A 为实际频数,T 为理论频数 2、有些统计量的分布可用卡方分布做近似处理 3、t 分布、F 分布是在卡方分布基础上推到出来的 卡方值反映了实际频数与理论频数的吻合程度 卡方检验的自由度取决于可以自由取值的格子数目,而不是样本含量。 卡方检验可用于两个或多个样本率(或构成比)的比较、关联性检验和频数分布拟合优度检验。对于四格表资料和 行x列 表资料还有专用公式。
上表为两样本率的比较,表内只有四个基本数据,称为四格表资料。 四格表资料的卡方检验 1、当 n >= 40 且所有的 T >= 5 时,用卡方检验的基本公式;当 P 约等于 α 时,改用四格表资料的 Fisher 确切概率法。 2、当 n >= 40 但有 1 |


【本文地址】
今日新闻 |
推荐新闻 |