如何确定最佳训练数据集规模? |
您所在的位置:网站首页 › spc数据取多少合适 › 如何确定最佳训练数据集规模? |
如何确定最佳训练数据集规模?
|
【导读】对于机器学习而言,获取数据的成本有时会非常昂贵,因此为模型选择一个合理的训练数据规模,对于机器学习是至关重要的。在本文中,作者针对线性回归模型和深度学习模型,分别介绍了确定训练数据集规模的方法。
数据是否会成为新时代的“原油”是人们近来常常争论的一个问题。 无论争论结果如何,可以确定的是,在机器学前期,数据获取成本可能十分高昂(人力工时、授权费、设备运行成本等)。因此,对于机器学习的一个非常关键的问题是,确定能使模型达到某个特定目标(如分类器精度)所需要的训练数据规模。 在本文中,我们将对经验性结果和研究文献中关于训练数据规模的讨论进行简明扼要的综述,涉及的机器学习模型包括回归分析等基本模型,以及复杂模型如深度学习。训练数据规模在文献中也称样本复杂度,本文将对如下内容进行介绍: 针对线性回归和计算机视觉任务,给出基于经验确定训练数据规模的限制; 讨论如何确定样本大小,以获得更好的假设检验结果。虽然这是一个统计问题,但是该问题和确定机器学习训练数据集规模的问题很相似,因此在这里一并讨论; 对影响训练数据集规模的因素,给出基于统计理论学习的结果; 探讨训练集增大对模型表现提升的影响,并着重分析深度学习中的情形; 给出一种在分类任务中确定训练数据集大小的方法; 探讨增大训练集是否是应对不平衡数据集的最好方式。基于经验确定训练集规模的限制 首先,我们依据使用的模型类型,探讨一些广泛使用的经验性方法: 回归分析:依据统计学中的“十分之一”经验法则(one-in-ten rule),每个预测器都需要使用 10 个实例训练。这种经验法则还有其他版本,例如用于解决回归系数缩减问题的“二十分之一”规则(one-in-twenty rule)。最近,《Sample Size For Binary Logistic Prediction Models: Beyond Events Per Variable Criteria》一文中还提出了一种有趣的二元逻辑回归变体。在该文中,作者通过预测器中变量的个数、总样本量,以及正样本量与总样本量的比值,对训练数据规模进行了估计。 计算机视觉:对于利用深度学习的图像分类问题,根据“经验法则”,建议每一个类别收集 1000 张图像。如果使用预训练模型,数据集的规模则可以大幅减少。通过假设检验确定样本规模 假设检验是数据科学常用的一种统计工具,一般也可以用于确定样本规模。 举个例子:某科技巨头搬去 A 城后,A 城的房价便急剧上涨,而某记者想知道现在每套公寓的均价是多少。那么问题来了,在保证 95% 的置信度,60 K 的公寓价格标准差,且价格误差在10K 以内的条件下,计算多少栋公寓的均价较为合理? 相应公式见下图,其中 N 为所需的样本规模,1.96 为标准正态分布在 95% 置信度下所对应的常数:
样本 |

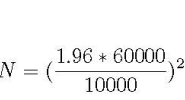
【本文地址】