【Spark编程基础】实验一Spark编程初级实践(附源代码) |
您所在的位置:网站首页 › spark编程基础scala › 【Spark编程基础】实验一Spark编程初级实践(附源代码) |
【Spark编程基础】实验一Spark编程初级实践(附源代码)
|
文章目录
一、实验目的二、实验平台三、实验内容和要求1. 计算级数2. 模拟图形绘制3.统计学生成绩
一、实验目的
1.掌握 Scala 语言的基本语法、数据结构和控制结构; 2.掌握面向对象编程的基础知识,能够编写自定义类和特质; 3.掌握函数式编程的基础知识,能够熟练定义匿名函数。熟悉 Scala 的容器类库的基本 层次结构,熟练使用常用的容器类进行数据; 4.熟练掌握 Scala 的 REPL 运行模式和编译运行方法。 二、实验平台操作系统:Ubuntu16.04; Spark 版本:2.1.0; Hadoop 版本:2.7.1。 三、实验内容和要求 1. 计算级数请用脚本的方式编程计算并输出下列级数的前 n 项之和 Sn,直到 Sn 刚好大于或等于 q 为止,其中 q 为大于 0 的整数,其值通过键盘输入。 学生的成绩清单格式如下所示,第一行为表头,各字段意思分别为学号、性别、课程名 1、课程名 2 等,后面每一行代表一个学生的信息,各字段之间用空白符隔开 Id gender Math English Physics 301610 male 80 64 78 301611 famale 65 87 58 给定任何一个如上格式的清单(不同清单里课程数量可能不一样),要求尽可能采用函 数式编程,统计出各门课程的平均成绩,最低成绩,和最高成绩;另外还需按男女同学分开,分别统计各门课程的平均成绩,最低成绩,和最高成绩。 object scoreReport{ def main(args: Array[String]) { val inputFile = scala.io.Source.fromFile("test.txt") val originalData = inputFile.getLines.map{_.split("\\s+")} .toList val courseNames = originalData.head.drop(2) //获取第一行中的课程名 val allStudents = originalData.tail // 去除第一行剩下的数据 val courseNum = courseNames.length def statistc(lines:List[Array[String]])= { (for(ielem=>elem(i).toDouble} (temp.sum,temp.min,temp.max) }) map {case (total,min,max) => (total/lines.length,min,max) } // 最后一个 map 对 for 的结果进行修改,将总分转为平均分 } // 输出结果函数 def printResult(theresult:Seq[(Double,Double,Double)]){ // 遍历前调用 zip 方法将课程名容器和结果容器合并,合并结果为二元组容器 (courseNames zip theresult) foreach { case (course,result)=> println(f"${course+":"}%-10s${result._1}%5.2f${result._2}%8.2f${result._3}%8.2f") } } // 分别调用两个函数统计全体学生并输出结果 val allResult = statistc(allStudents) println("course average min max") printResult(allResult) //按性别划分为两个容器 val (maleLines,femaleLines) = allStudents partition {_(1)=="male"} // 分别调用两个函数统计男学生并输出结果 val maleResult = statistc(maleLines) println("course average min max") printResult(maleResult) // 分别调用两个函数统计男学生并输出结果 val femaleResult = statistc(femaleLines) println("course average min max") printResult(femaleResult) } }注意:这里应提前创建一个test.txt文件(默认在当前目录下创建) |
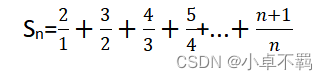 例 如 ,若 q 的 值 为 50.0 , 则输出应为:Sn=50.416695请将源文 件保存为 exercise2-1.scala,在REPL模式下测试运行,测试样例:q=1时,Sn=2;q=30时,Sn=30.891459; q=50 时,Sn=50.416695。
例 如 ,若 q 的 值 为 50.0 , 则输出应为:Sn=50.416695请将源文 件保存为 exercise2-1.scala,在REPL模式下测试运行,测试样例:q=1时,Sn=2;q=30时,Sn=30.891459; q=50 时,Sn=50.416695。【本文地址】