Spark核心 |
您所在的位置:网站首页 › spark的从节点叫什么 › Spark核心 |
Spark核心
|
Spark核心-集群及优化
集群管理器选择合适的集群管理器网页用户界面HBase关键性能指标并行度
调优并行度:
集群管理器
Spark应用通过集群管理器Cluster Manager的外部服务在集群中机器上启动,Spark自带的集群管理器称为独立集群管理器,也能运行在Hadoop Yarn和Apache Mesos两个开源集群管理器上。 Spark依赖于集群管理器来启动执行器节点,集群管理器在Spark中是可插拔式的 如:Hadoop YARN 会启动一个叫作资源管理器(Resource Manager)的主节点守护进程,以及一系列叫作节点管理器(Node Manager)的工作节点守护进程。 选择合适的集群管理器 如果从零开始,可以先选择独立集群管理器,如果只使用Spark的话,独立集群管理器与其他一样如果同时使用其他应用,需要用更丰富的资源调度功能如队列,Yarn或Mesos可以满足在任何时候,最好将Spark运行在运行HDFS的节点上,这样能快速访问HDFS存储,Yarn默认将HDFS装好了。 网页用户界面
Spark可以通过org.apache.hadoop.hbase.mapreduce.TableInputFormat访问Hbase,返回键值对数据,其中key为org.apache.hadoop.hbase.io.ImmutableBytesWritable,而Value的类型为org.apache.hadoop.hbase.client.Result。 TableInputFormat 包含多个可以用来优化对HBase 的读取的设置项,比如将扫描限制到一部分列中,以及限制扫描的时间范围。 关键性能指标 并行度RDD会被分为一系列分分区,每个分区都是数据的子集。当Spark调度并执行任务时,Spark会为每个分区中的数据创建一个任务,该任务需要集群中的一个cpu来执行,Spark会自动推测出合适的并行度,对于大多数应用是足够了。 并行度会从两方面影响程序的性能。 当并行度过低时,Spark 集群会出现资源闲置的情况。比如,假设你的应用有1000 个可使用的计算核心,但所运行的步骤只有30 个任务,你就应该提高并行度来充分利用更多的计算核心而当并行度过高时,每个分区产生的间接开销累计起来就会更大。评判并行度是否过高的标准包括任务是否是几乎在瞬间(毫秒级)完成的,或者是否观察到任务没有读写任何数据。 调优并行度: 数据混洗是,使用参数的方式为混洗后的RDD指定并行度重新分区当前当前的RDD获取更小或更大的分区Spark快速大数据分析 |
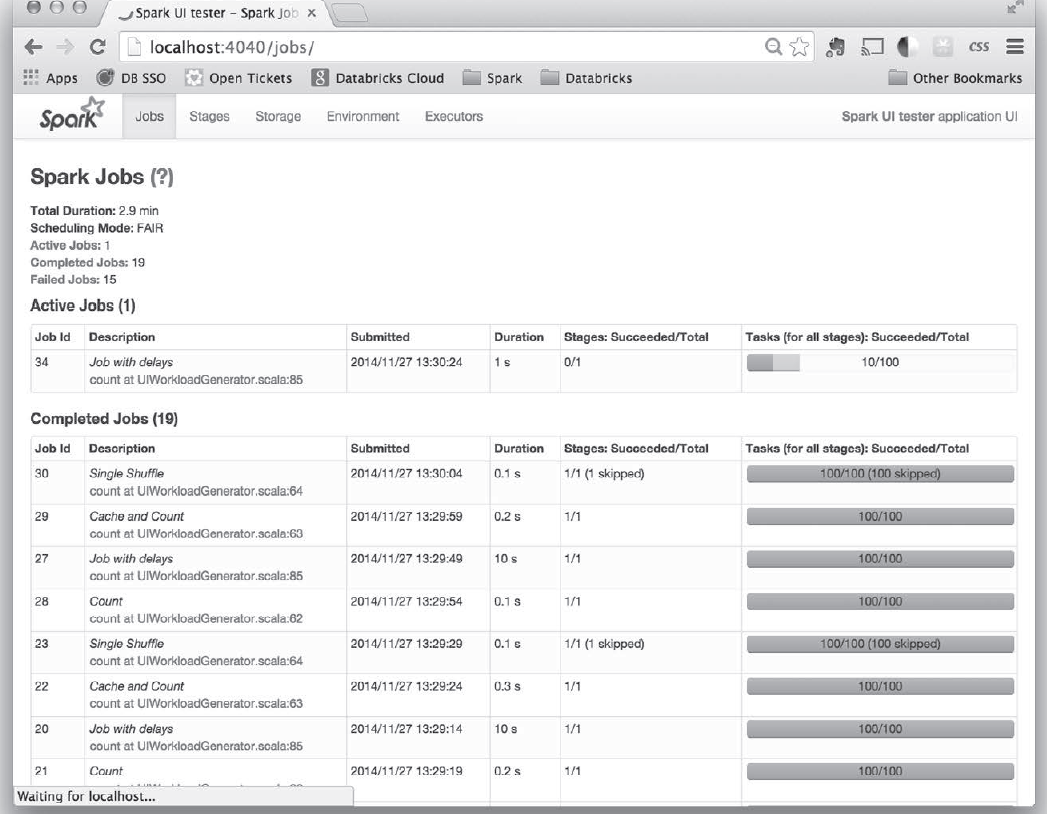 组成task的所有步骤,是不是有一些步骤特别慢,或者多次运行某作业响应时间差距很大,可以点击进去看看具体是那块的代码问题。
组成task的所有步骤,是不是有一些步骤特别慢,或者多次运行某作业响应时间差距很大,可以点击进去看看具体是那块的代码问题。 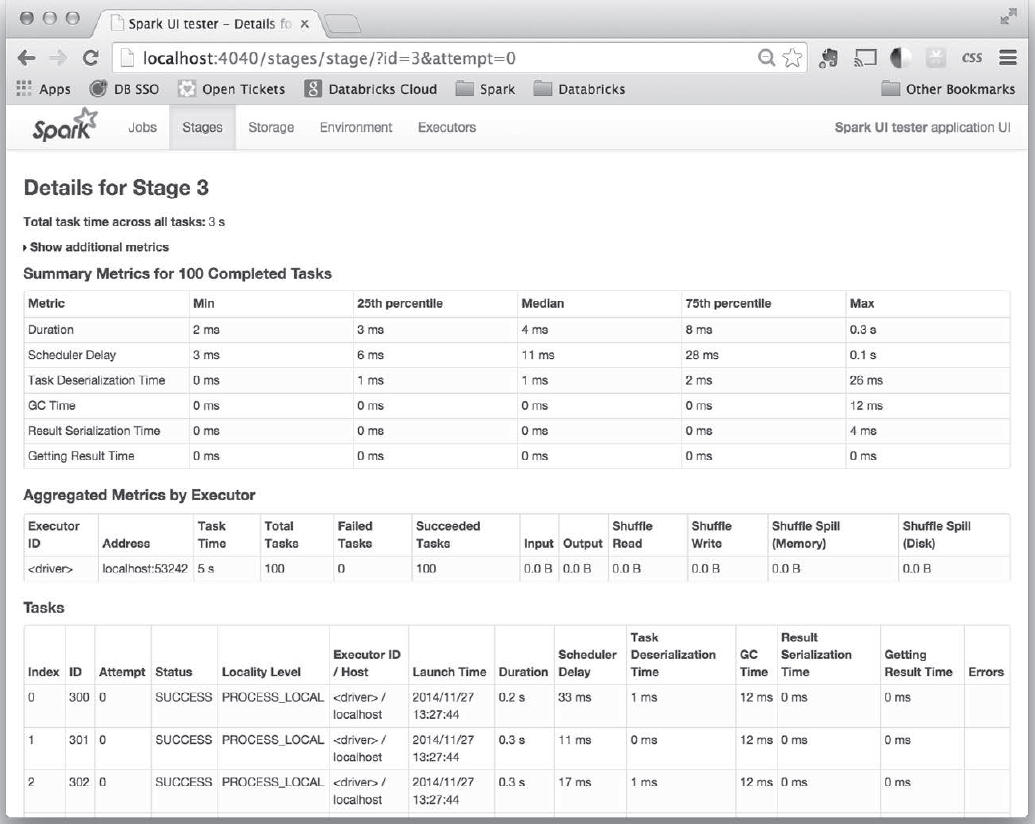
【本文地址】
今日新闻 |
推荐新闻 |