spark |
您所在的位置:网站首页 › spark安装csdn › spark |
spark
|
前言
在安装后hadoop之后,接下来需要安装的就是Spark。 scala-2.11.7下载与安装具体步骤参见上一篇博文 Spark下载为了方便,我直接是进入到了/usr/local文件夹下面进行下载spark-2.2.0 wget https://d3kbcqa49mib13.cloudfront.net/spark-2.2.0-bin-hadoop2.7.tgz Spark安装之前的准备文件的解压与改名 tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz rm -rf spark-2.2.0-bin-hadoop2.7.tgz为了我后面方便配置spark,在这里我把文件夹的名字给改了 mv spark-2.2.0-bin-hadoop2.7 spark-2.2.0 配置环境变量 vi /etc/profile在最尾巴加入 export SPARK_HOME=/usr/local/spark-2.2.0 export PATH=$PATH:$SPARK_HOME/bin
打开spark-2.2.0文件夹 cd spark-2.2.0此处需要配置的文件为两个 spark-env.sh和slaves
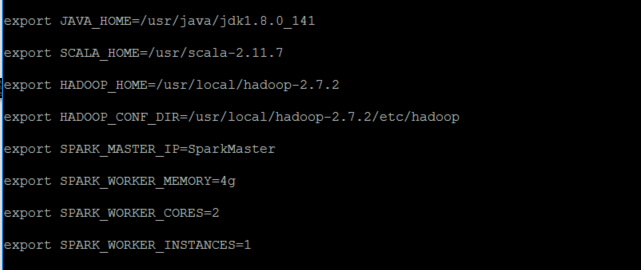
首先我们把缓存的文件spark-env.sh.template改为spark识别的文件spark-env.sh cp conf/spark-env.sh.template conf /spark-env.sh 修改spark-env.sh文件 vi conf/spark-env.sh在最尾巴加入 export JAVA_HOME=/usr/java/jdk1.8.0_141 export SCALA_HOME=/usr/scala-2.11.7 export HADOOP_HOME=/usr/local/hadoop-2.7.2 export HADOOP_CONF_DIR=/usr/local/hadoop-2.7.2/etc/hadoop export SPARK_MASTER_IP=SparkMaster export SPARK_WORKER_MEMORY=4g export SPARK_WORKER_CORES=2 export SPARK_WORKER_INSTANCES=1变量说明 JAVA_HOME:Java安装目录 SCALA_HOME:Scala安装目录 HADOOP_HOME:hadoop安装目录 HADOOP_CONF_DIR:hadoop集群的配置文件的目录 SPARK_MASTER_IP:spark集群的Master节点的ip地址 SPARK_WORKER_MEMORY:每个worker节点能够最大分配给exectors的内存大小 SPARK_WORKER_CORES:每个worker节点所占有的CPU核数目 SPARK_WORKER_INSTANCES:每台机器上开启的worker节点的数目
在最后面修成为 SparkWorker1 SparkWorker2
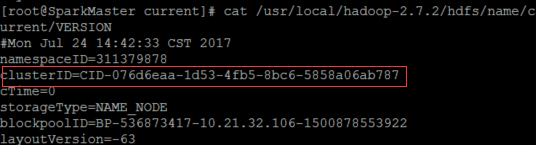
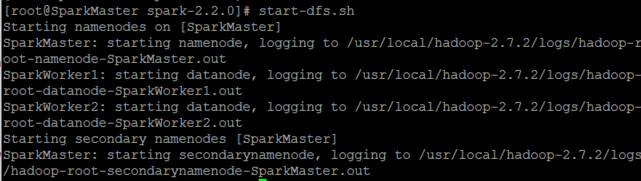
在此我们使用rsync命令 rsync -av /usr/local/spark-2.2.0/ SparkWorker1:/usr/local/spark-2.2.0/ rsync -av /usr/local/spark-2.2.0/ SparkWorker2:/usr/local/spark-2.2.0/ 启动Spark集群因为我们只需要使用hadoop的HDFS文件系统,所以我们并不用把hadoop全部功能都启动。 启动hadoop的HDFS文件系统 start-dfs.sh但是在此会遇到一个情况,就是使用start-dfs.sh,启动之后,在SparkMaster已经启动了namenode,但在SparkWorker1和SparkWorker2都没有启动了datanode,这里的原因是:datanode的clusterID和namenode的clusterID不匹配。是因为SparkMaster多次使用了hadoop namenode -format格式化了。 解决的办法: 在SparkMaster使用 cat /usr/local/hadoop-2.7.2/hdfs/name/current/VERSION查看clusterID,并将其复制。
在SparkWorker1和SparkWorker2上使用 vi /usr/local/hadoop-2.7.2/hdfs/name/current/VERSION将里面的clusterID,更改成为SparkMasterVERSION里面的clusterID
做了以上两步之后,便可重新使用start-dfs.sh开启HDFS文件系统。
启动之后使用jps命令可以查看到SparkMaster已经启动了namenode,SparkWorker1和SparkWorker2都启动了datanode,说明hadoop的HDFS文件系统已经启动了。
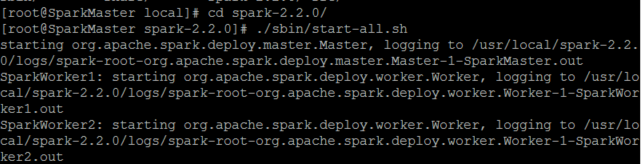
因为hadoop/sbin以及spark/sbin均配置到了系统的环境中,它们同一个文件夹下存在同样的start-all.sh文件。最好是打开spark-2.2.0,在文件夹下面打开该文件。 ./sbin/start-all.sh
成功打开之后使用jps在SparkMaster、parkWorker1和SparkWorker2节点上分别可以看到新开启的Master和Worker进程。
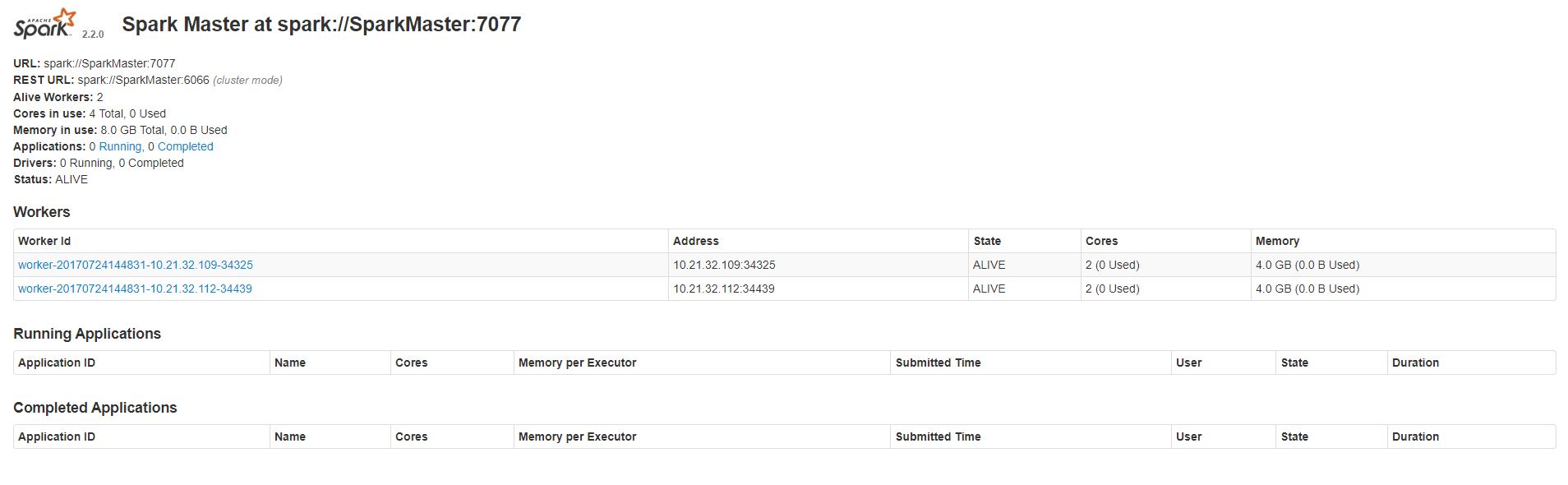
成功打开Spark集群之后可以进入Spark的WebUI界面,可以通过 SparkMaster_IP:8080访问,可见有两个正在运行的Worker节点。
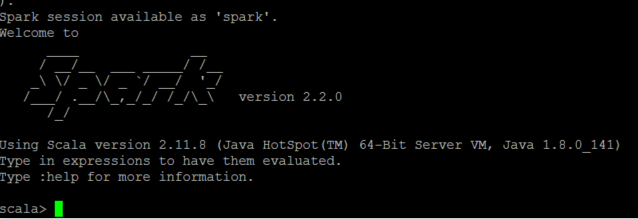
使用 spark-shell
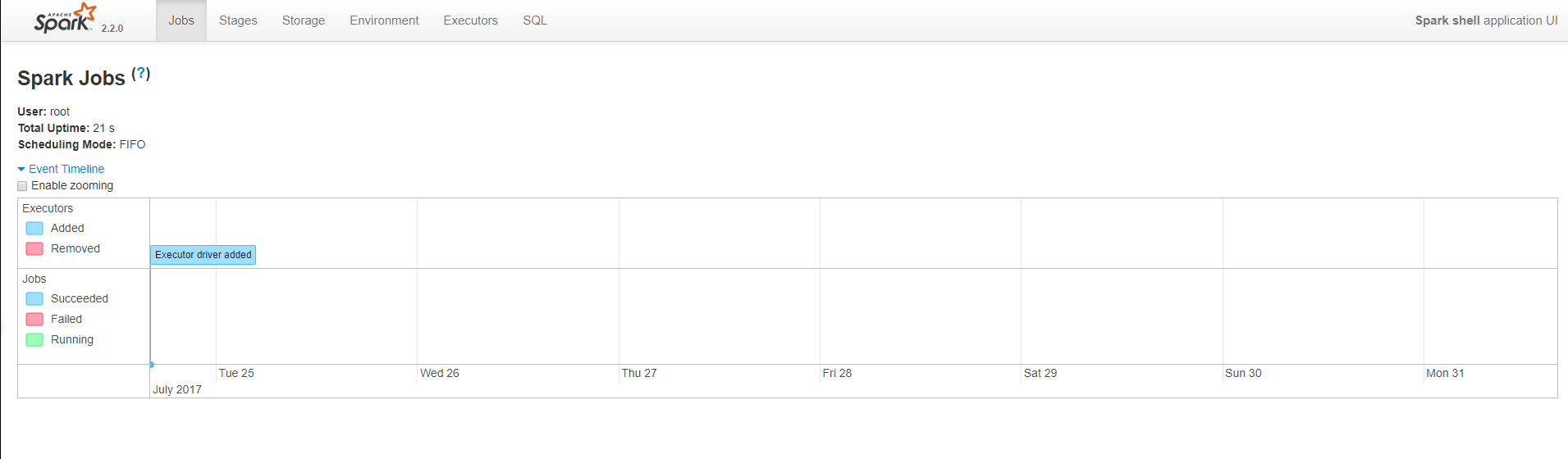
便可打开Spark的shell 同时,因为shell在运行,我们也可以通过 SparkMaster_IP:4040访问WebUI查看当前执行的任务。
到此我们的Spark集群就搭建完毕了。搭建spark集群原来知识网络是挺庞大的,涉及到Linux基本操作,设计到ssh,设计到hadoop、Scala以及真正的Spark。在此也遇到不少问题,通过翻阅书籍以及查看别人的blog得到了解决。在此感谢分享知识的人。 参见 王家林/王雁军/王家虎的《Spark 核心源码分析与开发实战》 文章出自kwongtai'blog,转载请标明出处! |









【本文地址】
今日新闻 |
推荐新闻 |