Spark |
您所在的位置:网站首页 › spark做什么用的 › Spark |
Spark
|
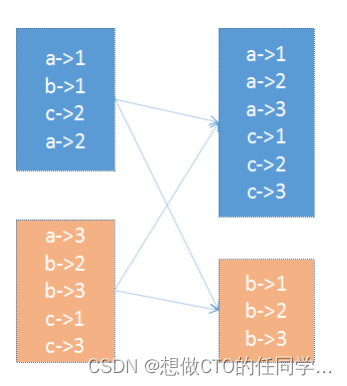
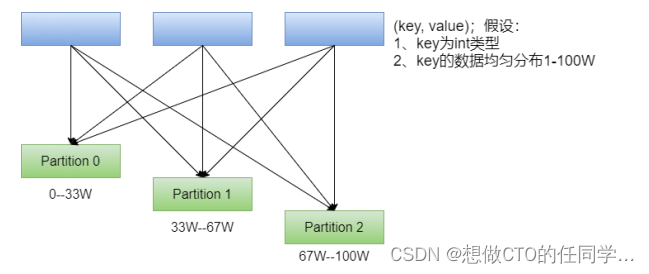
在 PairRDD(key,value) 中,很多操作都是基于key的,系统会按照key对数据进行重组,如groupbykey; 数据重组需要规则,最常见的就是基于 Hash 的分区,此外还有一种复杂的基于抽样Range 分区方法; HashPartitioner:最简单、最常用,也是默认提供的分区器。对于给定的key,计算其hashCode,并除以分区的个数取余,如果余数小于0,则用 余数+分区的个数,最后返回的值就是这个key所属的分区ID。该分区方法可以保证key相同的数据出现在同一个分区中。 可通过partitionBy主动使用分区器,通过partitions参数指定想要分区的数量。 val rdd1 = sc.makeRDD(1 to 100).map((_, 1)) rdd1.getNumPartitions // 仅仅是将数据大致平均分成了若干份;rdd并没有分区器 rdd2.glom.collect.foreach(x=>println(x.toBuffer)) rdd1.partitioner // 主动使用 HashPartitioner val rdd2 = rdd1.partitionBy(new org.apache.spark.HashPartitioner(10)) rdd2.glom.collect.foreach(x=>println(x.toBuffer)) // 主动使用 HashPartitioner val rdd3 = rdd1.partitionBy(new org.apache.spark.RangePartitioner(10, rdd1)) rdd3.glom.collect.foreach(x=>println(x.toBuffer))RangePartitioner:简单的说就是将一定范围内的数映射到某一个分区内。在实现中,分界的算法尤为重要,用到了水塘抽样算法。sortByKey会使用RangePartitioner。
在执行分区之前其实并不知道数据的分布情况,如果想知道数据分区就需要对数据进行采样;Spark中RangePartitioner在对数据采样的过程中使用了水塘采样算法。 水塘采样:从包含n个项目的集合S中选取k个样本,其中n为一很大或未知的数量,尤其适用于不能把所有n个项目都存放到主内存的情况;在采样的过程中执行了collect()操作,引发了Action操作 自定义分区器:Spark允许用户通过自定义的Partitioner对象,灵活的来控制RDD的分区方式。 |
【本文地址】
今日新闻 |
推荐新闻 |