Spark安装和使用 |
您所在的位置:网站首页 › spark下载安装教程 › Spark安装和使用 |
Spark安装和使用

如果你的计算机上已经安装了Hadoop,本步骤可以略过。这里假设没有安装。如果没有安装Hadoop,请访问Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04,依照教程学习安装即可。注意,在这个Hadoop安装教程中,就包含了Java的安装,所以,按照这个教程,就可以完成JDK和Hadoop这二者的安装。 二、安装 Spark访问Spark官方下载地址,按照如下图下载。
安装后,还需要修改Spark的配置文件spark-env.sh cd /usr/local/spark cp ./conf/spark-env.sh.template ./conf/spark-env.sh编辑spark-env.sh文件(vim ./conf/spark-env.sh),在第一行添加以下配置信息: export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)有了上面的配置信息以后,Spark就可以把数据存储到Hadoop分布式文件系统HDFS中,也可以从HDFS中读取数据。如果没有配置上面信息,Spark就只能读写本地数据,无法读写HDFS数据。 配置完成后就可以直接使用,不需要像Hadoop运行启动命令。 通过运行Spark自带的示例,验证Spark是否安装成功。 cd /usr/local/spark bin/run-example SparkPi执行时会输出非常多的运行信息,输出结果不容易找到,可以通过 grep 命令进行过滤(命令中的 2>&1 可以将所有的信息都输出到 stdout 中,否则由于输出日志的性质,还是会输出到屏幕中): bin/run-example SparkPi 2>&1 | grep "Pi is"这里涉及到Linux Shell中管道的知识,详情可以参考Linux Shell中的管道命令
过滤后的运行结果如下图示,可以得到π 的 5 位小数近似值:
学习Spark程序开发,建议首先通过spark-shell交互式学习,加深Spark程序开发的理解。 这里介绍Spark Shell 的基本使用。Spark shell 提供了简单的方式来学习 API,并且提供了交互的方式来分析数据。你可以输入一条语句,Spark shell会立即执行语句并返回结果,这就是我们所说的REPL(Read-Eval-Print Loop,交互式解释器),为我们提供了交互式执行环境,表达式计算完成就会输出结果,而不必等到整个程序运行完毕,因此可即时查看中间结果,并对程序进行修改,这样可以在很大程度上提升开发效率。 Spark Shell 支持 Scala 和 Python,这里使用 Scala 来进行介绍。 前面已经安装了Hadoop和Spark,如果Spark不使用HDFS和YARN,那么就不用启动Hadoop也可以正常使用Spark。如果在使用Spark的过程中需要用到 HDFS,就要首先启动 Hadoop(启动Hadoop的方法可以参考上面给出的Hadoop安装教程)。 这里假设不需要用到HDFS,因此,就没有启动Hadoop。现在我们直接开始使用Spark。 需要强调的是,这里我们采用“本地模式”(local)运行Spark,关于如何在集群模式下运行Spark,可以参考后面的“第十三章 Spark集群”的“在集群上运行Spark应用程序”。 在Spark中采用本地模式启动Spark Shell的命令主要包含以下参数: –master:这个参数表示当前的Spark Shell要连接到哪个master,如果是local[*],就是使用本地模式启动spark-shell,其中,中括号内的星号表示需要使用几个CPU核心(core); –jars: 这个参数用于把相关的JAR包添加到CLASSPATH中;如果有多个jar包,可以使用逗号分隔符连接它们; 比如,要采用本地模式,在4个CPU核心上运行spark-shell: cd /usr/local/spark ./bin/spark-shell --master local[4]或者,可以在CLASSPATH中添加code.jar,命令如下: cd /usr/local/spark ./bin/spark-shell --master local[4] --jars code.jar可以执行“spark-shell –help”命令,获取完整的选项列表,具体如下: cd /usr/local/spark ./bin/spark-shell --help上面是命令使用方法介绍,下面正式使用命令进入spark-shell环境,可以通过下面命令启动spark-shell环境: bin/spark-shell该命令省略了参数,这时,系统默认是“bin/spark-shell –master local[*]”,也就是说,是采用本地模式运行,并且使用本地所有的CPU核心。 启动spark-shell后,就会进入“scala>”命令提示符状态,如下图所示:
比如,下面在命令提示符后面输入一个表达式“8 * 2 + 5”,然后回车,就会立即得到结果: scala> 8*2+5 res0: Int = 21最后,可以使用命令“:quit”退出Spark Shell,如下所示: scala>:quit或者,也可以直接使用“Ctrl+D”组合键,退出Spark Shell。 四、Spark独立应用程序编程接着我们通过一个简单的应用程序 SimpleApp 来演示如何通过 Spark API 编写一个独立应用程序。使用 Scala 编写的程序需要使用 sbt 进行编译打包,相应的,Java 程序使用 Maven 编译打包,而 Python 程序通过 spark-submit 直接提交。 (一)编写Scala独立应用程序1.安装sbt sbt是一款Spark用来对scala编写程序进行打包的工具,这里简单介绍sbt的安装过程,感兴趣的读者可以参考官网资料了解更多关于sbt的内容。 Spark 中没有自带 sbt,这里直接给出sbt-launch.jar的下载地址,直接点击下载即可。 我们选择安装在 /usr/local/sbt 中: sudo mkdir /usr/local/sbt sudo chown -R hadoop /usr/local/sbt # 此处的 hadoop 为你的用户名 cd /usr/local/sbt下载后,执行如下命令拷贝至 /usr/local/sbt 中: cp ~/下载/sbt-launch.jar .接着在 /usr/local/sbt 中创建 sbt 脚本(vim ./sbt),添加如下内容: #!/bin/bash SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M" java $SBT_OPTS -jar `dirname $0`/sbt-launch.jar "$@"保存后,为 ./sbt 脚本增加可执行权限: chmod u+x ./sbt最后运行如下命令,检验 sbt 是否可用(请确保电脑处于联网状态,首次运行会处于 “Getting org.scala-sbt sbt 0.13.11 …” 的下载状态,请耐心等待。笔者等待了 7 分钟才出现第一条下载提示): ./sbt sbt-version只要能得到如下图的版本信息就没问题:
在 ./sparkapp/src/main/scala 下建立一个名为 SimpleApp.scala 的文件(vim ./sparkapp/src/main/scala/SimpleApp.scala),添加代码如下(目前不需要理解代码的具体含义,只需要理解如何编译运行代码就可以): /* SimpleApp.scala */ import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.SparkConf object SimpleApp { def main(args: Array[String]) { val logFile = "file:///usr/local/spark/README.md" // Should be some file on your system val conf = new SparkConf().setAppName("Simple Application") val sc = new SparkContext(conf) val logData = sc.textFile(logFile, 2).cache() val numAs = logData.filter(line => line.contains("a")).count() val numBs = logData.filter(line => line.contains("b")).count() println("Lines with a: %s, Lines with b: %s".format(numAs, numBs)) } }该程序计算 /usr/local/spark/README 文件中包含 “a” 的行数 和包含 “b” 的行数。代码第8行的 /usr/local/spark 为 Spark 的安装目录,如果不是该目录请自行修改。不同于 Spark shell,独立应用程序需要通过 val sc = new SparkContext(conf) 初始化 SparkContext,SparkContext 的参数 SparkConf 包含了应用程序的信息。 3.使用 sbt 打包 Scala 程序 该程序依赖 Spark API,因此我们需要通过 sbt 进行编译打包。 ./sparkapp 中新建文件 simple.sbt(vim ./sparkapp/simple.sbt),添加内容如下,声明该独立应用程序的信息以及与 Spark 的依赖关系: name := "Simple Project" version := "1.0" scalaVersion := "2.10.5" libraryDependencies += "org.apache.spark" %% "spark-core" % "1.6.2"文件 simple.sbt 需要指明 Spark 和 Scala 的版本。在上面的配置信息中,scalaVersion用来指定scala的版本,sparkcore用来指定spark的版本,这两个版本信息都可以在之前的启动 Spark shell 的过程中,从屏幕的显示信息中找到。下面就是笔者在启动过程当中,看到的相关版本信息(备注:屏幕显示信息会很长,需要往回滚动屏幕仔细寻找信息)。
为保证 sbt 能正常运行,先执行如下命令检查整个应用程序的文件结构: cd ~/sparkapp find .文件结构应如下图所示:
接着,我们就可以通过如下代码将整个应用程序打包成 JAR(首次运行同样需要下载依赖包 ): /usr/local/sbt/sbt package对于刚安装好的Spark和sbt而言,第一次运行上面的打包命令时,会需要几分钟的运行时间,因为系统会自动从网络上下载各种文件。后面再次运行上面命令,就会很快,因为不再需要下载相关文件。 打包成功的话,会输出如下图内容:
生成的 jar 包的位置为 ~/sparkapp/target/scala-2.10/simple-project_2.10-1.0.jar。 4.通过 spark-submit 运行程序 最后,我们就可以将生成的 jar 包通过 spark-submit 提交到 Spark 中运行了,命令如下: /usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.10/simple-project_2.10-1.0.jar # 上面命令执行后会输出太多信息,可以不使用上面命令,而使用下面命令查看想要的结果 /usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.10/simple-project_2.10-1.0.jar 2>&1 | grep "Lines with a:"最终得到的结果如下: Lines with a: 58, Lines with b: 26至此,你就完成了你的第一个 Spark 应用程序了。 (二)Java独立应用编程 安装maven ubuntu中没有自带安装maven,需要手动安装maven。可以访问maven官方下载自己下载。这里直接给出apache-maven-3.3.9-bin.zip的下载地址,直接点击下载即可。 选择安装在/usr/local/maven中: sudo unzip ~/下载/apache-maven-3.3.9-bin.zip -d /usr/local cd /usr/local sudo mv apache-maven-3.3.9/ ./maven sudo chown -R hadoop ./maven Java应用程序代码 在终端执行如下命令创建一个文件夹sparkapp2作为应用程序根目录 cd ~ #进入用户主文件夹 mkdir -p ./sparkapp2/src/main/java在 ./sparkapp2/src/main/java 下建立一个名为 SimpleApp.java 的文件(vim ./sparkapp2/src/main/java/SimpleApp.java),添加代码如下: /*** SimpleApp.java ***/ import org.apache.spark.api.java.*; import org.apache.spark.api.java.function.Function; public class SimpleApp { public static void main(String[] args) { String logFile = "file:///usr/local/spark/README.md"; // Should be some file on your system JavaSparkContext sc = new JavaSparkContext("local", "Simple App", "file:///usr/local/spark/", new String[]{"target/simple-project-1.0.jar"}); JavaRDD logData = sc.textFile(logFile).cache(); long numAs = logData.filter(new Function() { public Boolean call(String s) { return s.contains("a"); } }).count(); long numBs = logData.filter(new Function() { public Boolean call(String s) { return s.contains("b"); } }).count(); System.out.println("Lines with a: " + numAs + ", lines with b: " + numBs); } }该程序依赖Spark Java API,因此我们需要通过Maven进行编译打包。在./sparkapp2中新建文件pom.xml(vim ./sparkapp2/pom.xml),添加内容如下,声明该独立应用程序的信息以及与Spark的依赖关系: edu.berkeley simple-project 4.0.0 Simple Project jar 1.0 Akka repository http://repo.akka.io/releases org.apache.spark spark-core_2.10 1.6.2关于Spark dependency的依赖关系,可以访问The Central Repository。搜索spark-core可以找到相关依赖关系信息。
使用maven打包java程序 为了保证maven能够正常运行,先执行如下命令检查整个应用程序的文件结构: cd ~/sparkapp2 find文件结构如下图:
如出现下图,说明生成Jar包成功:
通过spark-submit 运行程序 最后,可以通过将生成的jar包通过spark-submit提交到Spark中运行,如下命令: /usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp2/target/simple-project-1.0.jar # 上面命令执行后会输出太多信息,可以不使用上面命令,而使用下面命令查看想要的结果 /usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp2/target/simple-project-1.0.jar 2>&1 | grep "Lines with a"最后得到的结果如下: Lines with a: 58, Lines with b: 26 |
 【版权声明】博客内容由厦门大学数据库实验室拥有版权,未经允许,请勿转载!
[返回Spark教程首页]
Spark可以独立安装使用,也可以和Hadoop一起安装使用。本教程中,我们采用和Hadoop一起安装使用,这样,就可以让Spark使用HDFS存取数据。需要说明的是,当安装好Spark以后,里面就自带了scala环境,不需要额外安装scala,因此,“Spark安装”这个部分的教程,假设读者的计算机上,没有安装Scala,也没有安装Java(当然了,如果已经安装Java和Scala,也没有关系,依然可以继续按照本教程进行安装),也就是说,你的计算机目前只有Linux系统,其他的软件和环境都没有安装(没有Java,没有Scala,没有Hadoop,没有Spark),需要从零开始安装所有大数据相关软件。下面,需要你在自己的Linux系统上(笔者采用的Linux系统是Ubuntu14.04),首先安装Java和Hadoop,然后再安装Spark(Spark安装好以后,里面就默认包含了Scala解释器)。本教程的具体运行环境如下:
【版权声明】博客内容由厦门大学数据库实验室拥有版权,未经允许,请勿转载!
[返回Spark教程首页]
Spark可以独立安装使用,也可以和Hadoop一起安装使用。本教程中,我们采用和Hadoop一起安装使用,这样,就可以让Spark使用HDFS存取数据。需要说明的是,当安装好Spark以后,里面就自带了scala环境,不需要额外安装scala,因此,“Spark安装”这个部分的教程,假设读者的计算机上,没有安装Scala,也没有安装Java(当然了,如果已经安装Java和Scala,也没有关系,依然可以继续按照本教程进行安装),也就是说,你的计算机目前只有Linux系统,其他的软件和环境都没有安装(没有Java,没有Scala,没有Hadoop,没有Spark),需要从零开始安装所有大数据相关软件。下面,需要你在自己的Linux系统上(笔者采用的Linux系统是Ubuntu14.04),首先安装Java和Hadoop,然后再安装Spark(Spark安装好以后,里面就默认包含了Scala解释器)。本教程的具体运行环境如下: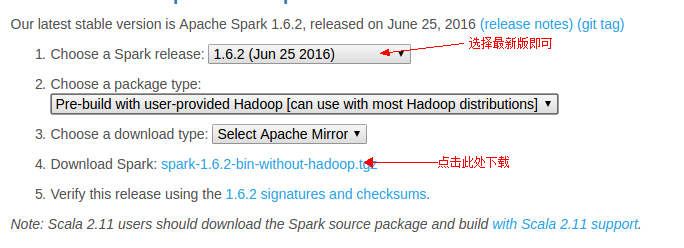 关于Spark官网下载页面中的“Choose a package type”,这里补充说明如下:
Source code: Spark 源码,需要编译才能使用;
Pre-build with user-provided Hadoop: 属于“Hadoop free”版,可应用到任意Hadoop 版本;
Pre-build for Hadoop 2.6 and later: 基于Hadoop 2.6的预先编译版,需要与本机安装的Hadoop版本对应,可选的还有Hadoop 2.6、Hadoop 2.4、Hadoop 2.3、Hadoop1.x、CDH4。
由于我们已经自己安装了Hadoop,所以,在“Choose a package type”后面需要选择“Pre-build with user-provided Hadoop [can use with most Hadoop distributions]”,因为这个选项的Spark可以应用于任意Hadoop版本,所以,就可以应用到我们已经安装的Hadoop版本。然后,点击“Download Spark”后面的“spark-1.6.2-bin-without-hadoop.tgz”下载即可。
Spark部署模式主要有四种:Local模式(单机模式)、Standalone模式(使用Spark自带的简单集群管理器)、YARN模式(使用YARN作为集群管理器)和Mesos模式(使用Mesos作为集群管理器)。
这里介绍Local模式(单机模式)的 Spark安装。我们选择Spark 1.6.2版本,并且假设当前使用用户名hadoop登录了Linux操作系统。
关于Spark官网下载页面中的“Choose a package type”,这里补充说明如下:
Source code: Spark 源码,需要编译才能使用;
Pre-build with user-provided Hadoop: 属于“Hadoop free”版,可应用到任意Hadoop 版本;
Pre-build for Hadoop 2.6 and later: 基于Hadoop 2.6的预先编译版,需要与本机安装的Hadoop版本对应,可选的还有Hadoop 2.6、Hadoop 2.4、Hadoop 2.3、Hadoop1.x、CDH4。
由于我们已经自己安装了Hadoop,所以,在“Choose a package type”后面需要选择“Pre-build with user-provided Hadoop [can use with most Hadoop distributions]”,因为这个选项的Spark可以应用于任意Hadoop版本,所以,就可以应用到我们已经安装的Hadoop版本。然后,点击“Download Spark”后面的“spark-1.6.2-bin-without-hadoop.tgz”下载即可。
Spark部署模式主要有四种:Local模式(单机模式)、Standalone模式(使用Spark自带的简单集群管理器)、YARN模式(使用YARN作为集群管理器)和Mesos模式(使用Mesos作为集群管理器)。
这里介绍Local模式(单机模式)的 Spark安装。我们选择Spark 1.6.2版本,并且假设当前使用用户名hadoop登录了Linux操作系统。
 现在,你就可以在里面输入scala代码进行调试了。启动进入Spark Shell以后,系统自动为你创建了一个专有的SparkContext,变量名叫做sc,可以直接使用(后面章节的RDD编程中,就会用到sc变量)。
现在,你就可以在里面输入scala代码进行调试了。启动进入Spark Shell以后,系统自动为你创建了一个专有的SparkContext,变量名叫做sc,可以直接使用(后面章节的RDD编程中,就会用到sc变量)。 2.编写Scala应用程序
在终端中执行如下命令创建一个文件夹 sparkapp 作为应用程序根目录:
2.编写Scala应用程序
在终端中执行如下命令创建一个文件夹 sparkapp 作为应用程序根目录: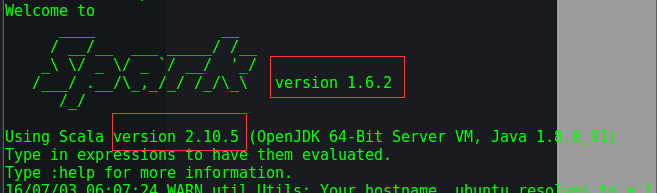 3
3 SimpleApp的文件结构
SimpleApp的文件结构 SimpleApp的文件结构
SimpleApp的文件结构
 接着,我们可以通过如下代码将这整个应用程序打包成Jar(注意:电脑需要保持连接网络的状态,而且首次运行mvn package命令时,系统会自动从网络下载相关的依赖包,同样消耗几分钟的时间,后面再次运行mvn package命令,速度就会快很多):
接着,我们可以通过如下代码将这整个应用程序打包成Jar(注意:电脑需要保持连接网络的状态,而且首次运行mvn package命令时,系统会自动从网络下载相关的依赖包,同样消耗几分钟的时间,后面再次运行mvn package命令,速度就会快很多):
【本文地址】