sonar |
您所在的位置:网站首页 › sonar检查 › sonar |
sonar
|
前言
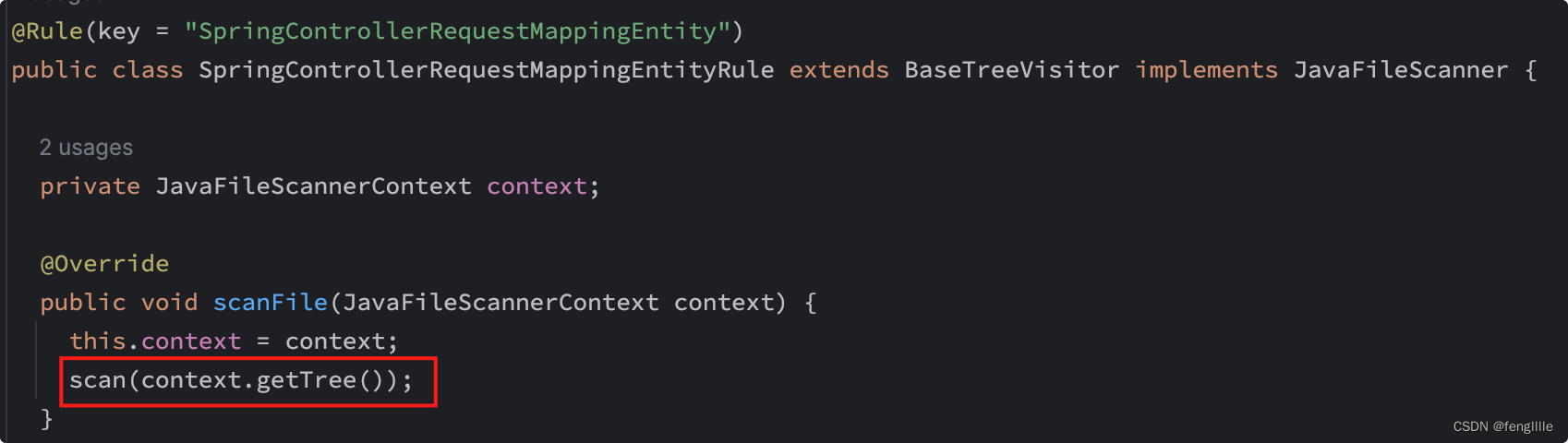
最近做项目,定制sonar规则,提高Java代码质量,在编写的sonar规则,做验证时,使用单元测试有一些简单的心得感悟,分享出来。 自定义规则模式sonar的自定义规则很简单,一般而言有2种模式可以使用: 1. 自定义扫描代码逻辑,并对分类的Tree的结构处理 2. 使用已扫描的分类,对分好类的Tree进行分析 BaseTreeVisitor&JavaFileScanner extends BaseTreeVisitor implements JavaFileScanner继承Tree的访问器,实现Java文件扫描器
TreeVisitor定义了很多Tree的读取过程,当然我们也可以扩展这个过程,Tree是哪里来的呢,scan的接口实现的
继承发布订阅访问器,意思是sonar的sdk默认扫描出来,我们需要定义那些是我们需要的,就订阅处理相关的Tree处理,推荐使用这种方式,开发便捷,性能可以得到保障,毕竟扫描文件的算法,如果写的性能差,扫描会很久。 比如我们写一个扫描检查Java代码里的SQL的drop table语句 @Rule(key = "DropTableSQLCheck") public class DropTableSQLCheck extends IssuableSubscriptionVisitor { private static final String RECOMMENDATION_DROP_MESSAGE = "Make sure that drop table \"%s\" is expected here instead of sql platform."; private static final String DROP_TABLE_STR = "DROP TABLE"; //告诉sonar插件,我需要访问这个,这里定义了字符串,插件定义了很多,如果不符合要求就需要自定义扩展,同时需要扩展扫描器 @Override public List nodesToVisit() { return Collections.singletonList(Tree.Kind.STRING_LITERAL); } // 访问我们刚刚要求的类型,已经安装Kind过滤了,扫描文件,归类的逻辑,已经sonar的API实现了,如果不符合要求才需要扩展 @Override public void visitNode(Tree tree) { if (!tree.is(Tree.Kind.STRING_LITERAL)) return; SyntaxToken syntaxToken = tree.firstToken(); if (syntaxToken == null) return; String str = syntaxToken.text(); if (StringUtils.isBlank(str)) return; String originStr = str; str = str.trim().toUpperCase(); if (str.contains(DROP_TABLE_STR)) { reportIssue(tree, String.format(RECOMMENDATION_DROP_MESSAGE, originStr)); } } }这里没有考虑xml的SQL,包括字符串多个空格的考虑,理论上应该按照分析drop,然后为index逐个字符读取,如果是空格就读取下一个,如果是非t就return,如果下一个是非a就return,当然也可以使用正则。这里使用简化算法,做一个Demo
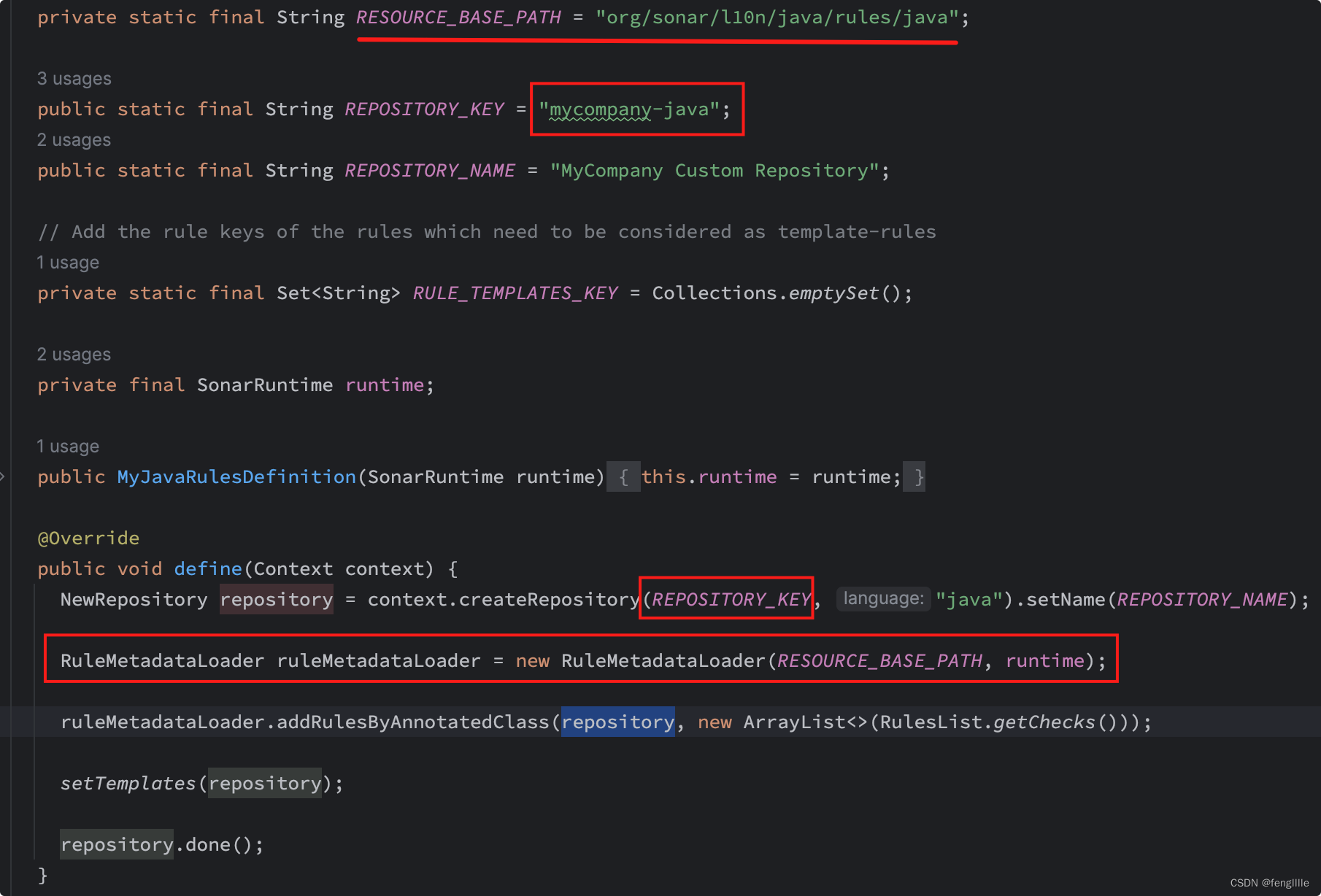
加上规则类,仿造写sonarqube的元数据
到此规则编写完成,后面分析单元测试逻辑 源码分析简单分析下,代码执行逻辑,类似Java agent插件
从main的class执行
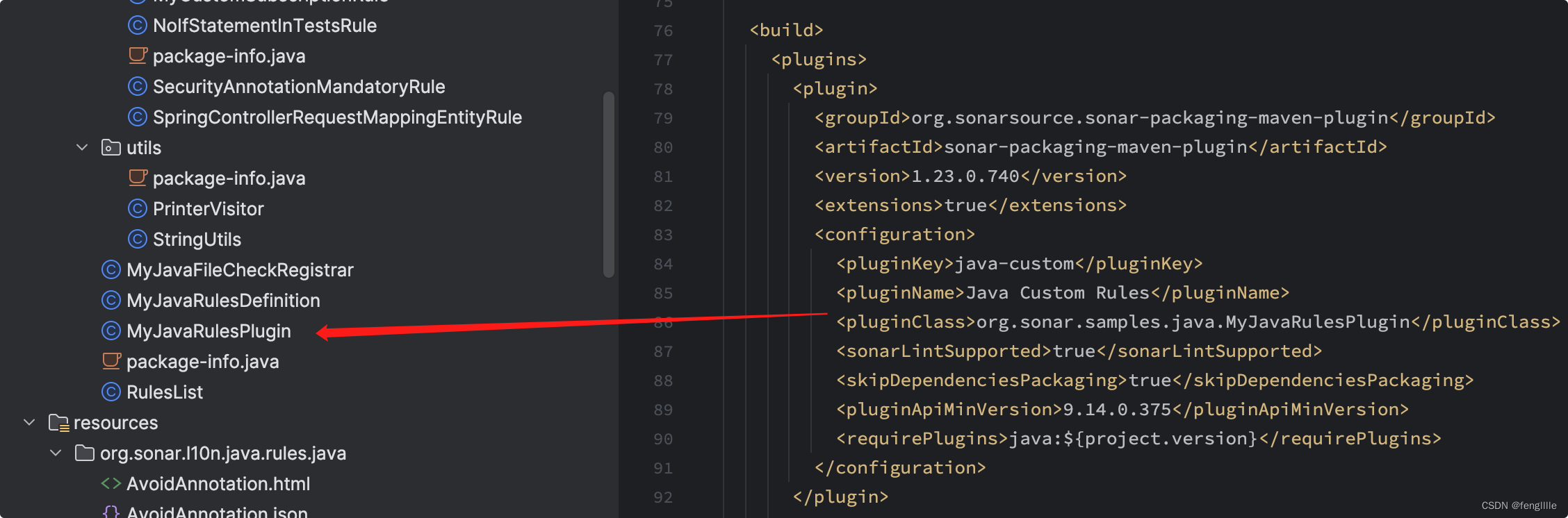
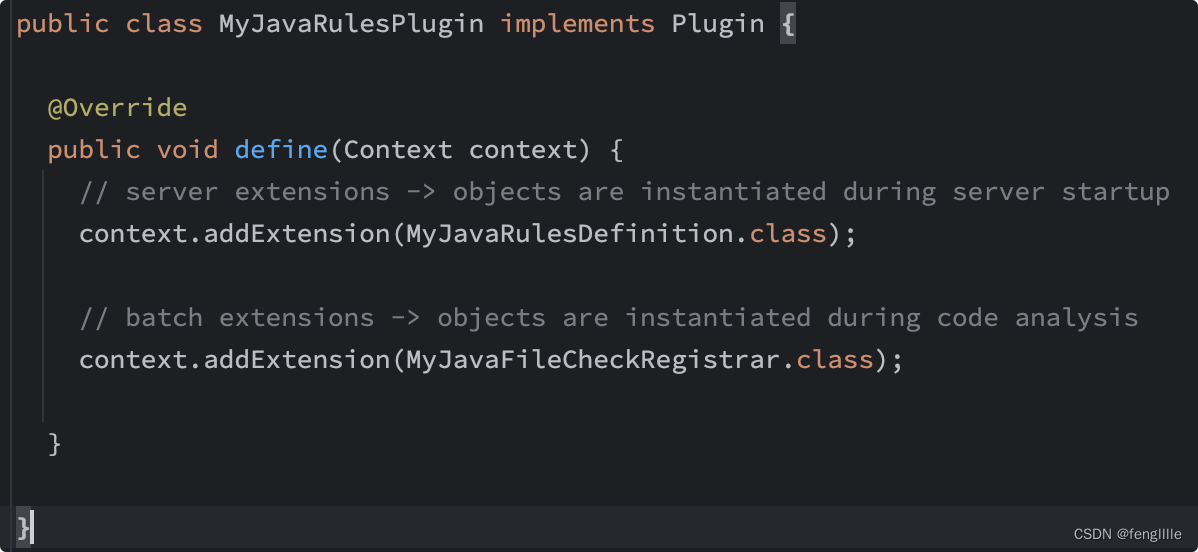
上下文加扩展,这里是一个注册扫描规则,一个注册扫描元数据,当然也可以合二为一,架构建议分离,所以Demo是分离的 元数据规则是sonarqube server启动实例化,启动就可以看到检查类别,检查类规则是代码分析时实例化
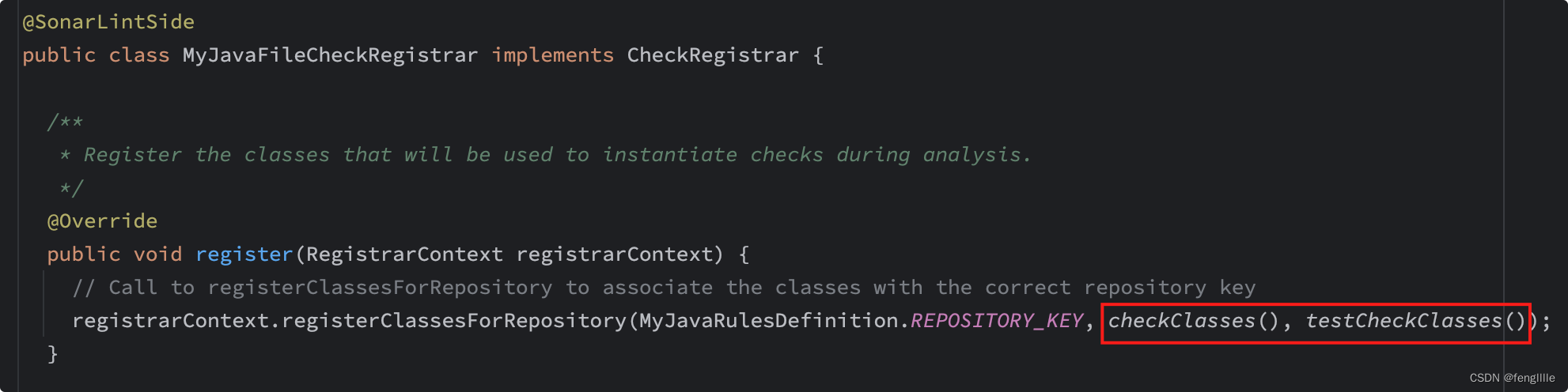
注册规则类,这里又分了是否用于test,上面的手写规则需要注入这个里面
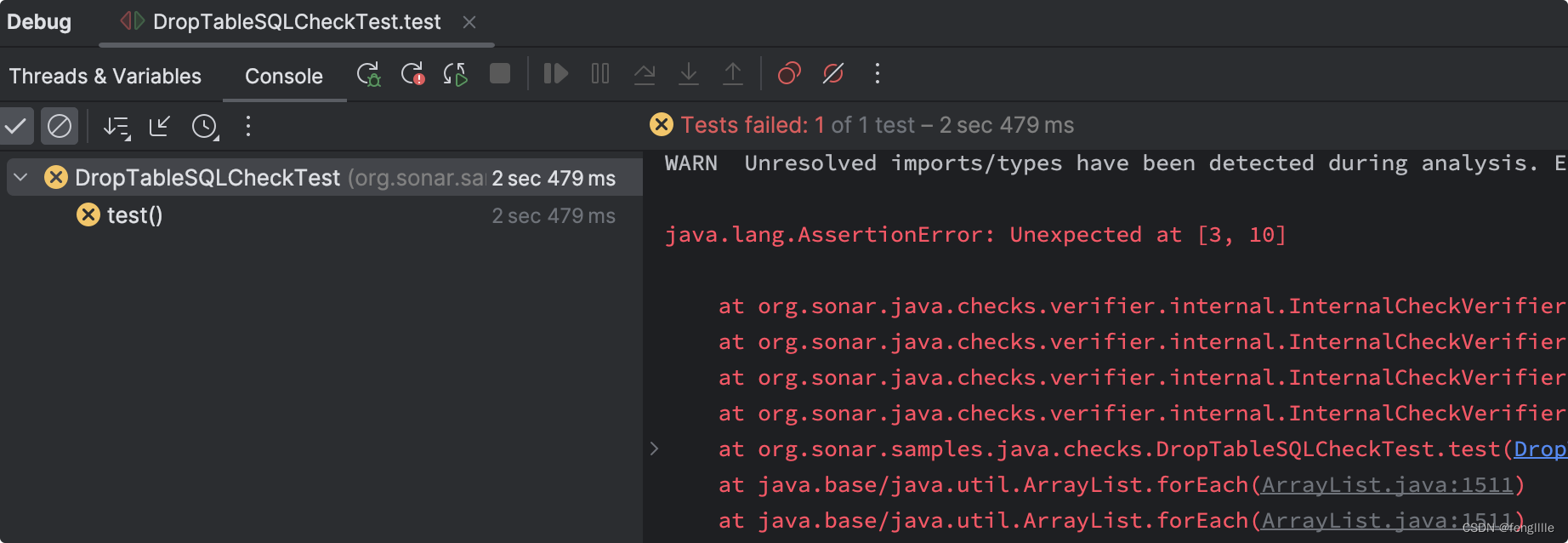
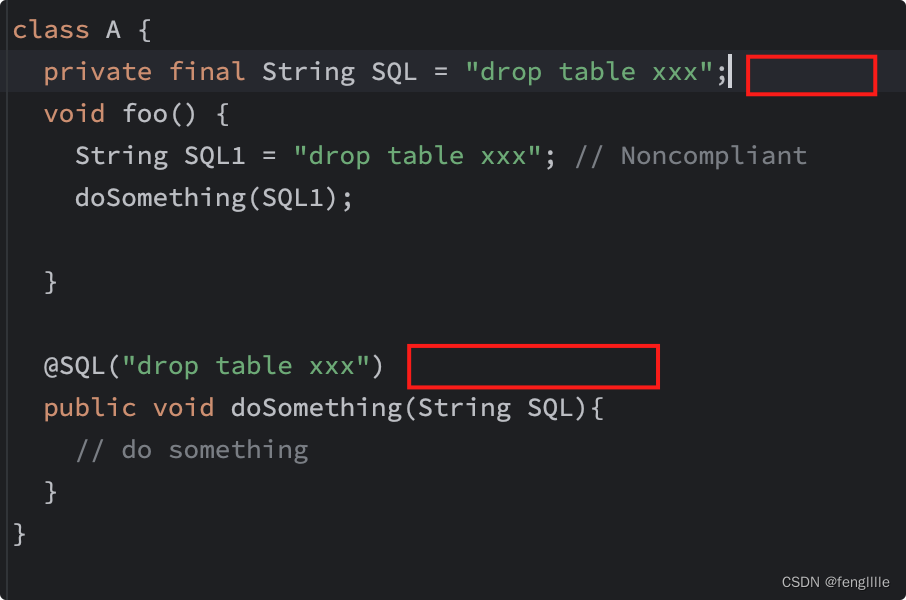
元数据信息是路径扫描读取的,所以只要放在那个路径就行,通过@Rule的名称匹配文件名 这里的repository_key是sonarqube显式的规则名称,同时这里也可以扫描其他语言,比如xml 这里写好后,如果需要本地验证,则需要单元测试。 单元测试编写单元测试代码,即使是不能编译的代码也可以扫描 class A { private final String SQL = "drop table xxx"; void foo() { String SQL1 = "drop table xxx"; // Noncompliant doSomething(SQL1); } @SQL("drop table xxx") public void doSomething(String SQL){ // do something } }编写test public class DropTableSQLCheckTest { @Test void test() { ((InternalCheckVerifier) CheckVerifier.newVerifier()) .onFile("src/test/files/DropTableSQLCheck.java") .withCheck(new DropTableSQLCheck()) .withQuickFixes() .verifyIssues(); } }载入需要扫描的文件和使用那个规则类检查 单元测试分析单元测试写好后,出现这个错误
这并不是规则写的有问题或者规则没命中,而是一种断言,sonar的单元测试jar定义
如果扫描出问题,那么需要对有问题的行打上 // Noncompliant开头的注释,否则断言不通过 规则来源于org.sonar.java.checks.verifier.internal.Expectations的 collectExpectedIssues方法中 private static final String NONCOMPLIANT_FLAG = "Noncompliant"; private final Set visitedComments = new HashSet(); private Pattern nonCompliantComment = Pattern.compile("//\\s+" + NONCOMPLIANT_FLAG); private void collectExpectedIssues(String comment, int line) { // 此处断言,收集断言有问题的代码行 if (nonCompliantComment.matcher(comment).find()) { ParsedComment parsedComment = parseIssue(comment, line); if (parsedComment.issue.get(QUICK_FIXES) != null && !collectQuickFixes) { throw new AssertionError("Add \".withQuickFixes()\" to the verifier. Quick fixes are expected but the verifier is not configured to test them."); } // 放进预估 issues.computeIfAbsent(LINE.get(parsedComment.issue), k -> new ArrayList()).add(parsedComment.issue); parsedComment.flows.forEach(f -> flows.computeIfAbsent(f.id, k -> newFlowSet()).add(f)); } if (FLOW_COMMENT.matcher(comment).find()) { parseFlows(comment, line).forEach(f -> flows.computeIfAbsent(f.id, k -> newFlowSet()).add(f)); } if (collectQuickFixes) { parseQuickFix(comment, line); } }同理,如果一个问题都没用,那么验证不了规则,直接断言失败 org.sonar.java.checks.verifier.internal.InternalCheckVerifier private void assertMultipleIssues(Set issues, Map quickFixes) throws AssertionError { if (issues.isEmpty()) { // 没有错误示例,就断言失败 throw new AssertionError("No issue raised. At least one issue expected"); } List unexpectedLines = new LinkedList(); Expectations.RemediationFunction remediationFunction = Expectations.remediationFunction(issues.iterator().next()); Map expected = expectations.issues; for (AnalyzerMessage issue : issues) { validateIssue(expected, unexpectedLines, issue, remediationFunction); } // expected就是我们通过注释断言的sonar需要扫描出来的问题,如果有部分没有预计断言出来就会 if (!expected.isEmpty() || !unexpectedLines.isEmpty()) { Collections.sort(unexpectedLines); List expectedLines = expected.keySet().stream().sorted().collect(Collectors.toList()); throw new AssertionError(new StringBuilder() //这里抛出断言缺失的错误或者错误断言的错误 .append(expectedLines.isEmpty() ? "" : String.format("Expected at %s", expectedLines)) .append(expectedLines.isEmpty() || unexpectedLines.isEmpty() ? "" : ", ") .append(unexpectedLines.isEmpty() ? "" : String.format("Unexpected at %s", unexpectedLines)) .toString()); } assertSuperfluousFlows(); if (collectQuickFixes) { new QuickFixesVerifier(expectations.quickFixes(), quickFixes).accept(issues); } } 总结sonar扫描实际上现在已经非常完善了,尤其是新API的提供,很大程度不需要我们写什么东西,专注核心的扫描算法与Tree的解析,甚至大部分扫描算法都不需要写了,使用发布订阅即可,得益于新API的提供,目前使用的很多API还是@Beta注解,但是开发效率极大的提升了,毕竟以前旧的sonar版本,需要我们自己写各种扫描与分析逻辑。不过sonar的单元测试与传统的单元测试是有一定区别的,sonar的测试逻辑是必须有一个问题测试案例,且需要打上 // Noncompliant注释,注释的行既是命中的行,sonar使用行号作为map的key,这样sonar才认为是命中规则的。如果断言错误,或者断言的数量不对,那么也一样会单元测试失败。 |



【本文地址】
今日新闻 |
推荐新闻 |