特征重要度和SHAP值 |
您所在的位置:网站首页 › sharp的翻译 › 特征重要度和SHAP值 |
特征重要度和SHAP值
|
引子: 在模型的训练过程中,往往会要求更加优异的模型性能指标如准确率、召回等,但在实际生产中,随着模型上线使用产生衰减,又需要快速定位问题进行修复,因此了解模型如何运作、哪些特征起到了关键作用有着重要意义。同时,可解释的模型能够让业务方也就是模型使用者,能够更加信任和熟悉模型的决策过程。尤其在风控领域,基于金融机构的监管层要求以及信贷业务的稳健发展方面,都需要在信贷业务流程中部署的风控模型具有良好的解释性。 背景机器学习效果往往会优于传统的评分卡模型,相对于可以对每个入模变量赋予权重的逻辑回归方法来说,机器学习的训练和部署,相当于封装在一个黑匣子里,输入变量得出预测概率值。因此我们想要保留机器学习的优越性能,尝试赋予模型可解释性,以寻求一个平衡点。Xgboost是最我们最常使用的机器学习模型,训练完模型到底是哪些变量起到了重要的作用,又是怎么影响预测结果的呢?尝试从变量重要性,结合shap值去进行解释。 xgboost可以通过get_fscore获取特征重要性,可以查看官网上的API使用方法: get_score(fmap='', importance_type='weight') Get feature importance of each feature. Importance type can be defined as: ‘weight’: the number of times a feature is used to split the data across all trees.‘gain’: the average gain across all splits the feature is used in.‘cover’: the average coverage across all splits the feature is used in.‘total_gain’: the total gain across all splits the feature is used in.‘total_cover’: the total coverage across all splits the feature is used in.# 计算变量的所有特征重要性 importance_all = pd.DataFrame() for importance_type in ('weight', 'gain', 'cover', 'total_gain', 'total_cover'): importance = trained_xgb.get_booster().get_score(importance_type=importance_type) keys = list(importance.keys()) values = list(importance.values()) df_importance = pd.DataFrame(data=values, index=keys, columns=['importance_'+importance_type]) importance_all = pd.concat([importance_all, df_importance],axis=1) importance_all weight:在所有树中,某特征被用来分裂节点的次数;total_cover:total_cover表示在所有树中,某特征在每次分裂节点时处理(覆盖)的所有样例的数量;cover:cover = total_cover / weight,某特征平均每次分裂覆盖的样本数;total_gain:在所有树中,某特征在每次分裂节点时带来的总增益,即用熵或基尼不纯衡量分裂前后的信息量之差。gain:gain = total_gain / weight,每次分裂的增益均值; weight:在所有树中,某特征被用来分裂节点的次数;total_cover:total_cover表示在所有树中,某特征在每次分裂节点时处理(覆盖)的所有样例的数量;cover:cover = total_cover / weight,某特征平均每次分裂覆盖的样本数;total_gain:在所有树中,某特征在每次分裂节点时带来的总增益,即用熵或基尼不纯衡量分裂前后的信息量之差。gain:gain = total_gain / weight,每次分裂的增益均值;选择不同的重要性指标,特征重要性排序会不太一样,但通过重要性排序可以大致看出在模型中起到重要作用的变量维度。可以看到本例中用户历史近6个月最大逾期天数是最重要的变量,按照业务经验来看历史最大逾期天数越大,预测坏的可能性越大。但实际上特征重要性仅给出了重要变量是什么,并没有给出上述影响的正负性的判断。和feature importance相比,shap值弥补了这一不足,不仅给出变量的重要性程度还给出了影响的正负性。 shap值Shap是Shapley Additive explanations的缩写,即沙普利加和解释,对于每个样本模型都产生一个预测值,Shap value就是该样本中每个特征所分配到的数值。与线性模型的加和方法类似, 假设模型基准分(通常是所有样本的目标变量的均值)为ybase,第i个样本为xi,第i个样本的第j个特征为xi,j,该特征的Shap value为 f(x_i,j) ,则模型对样本 x_i 的预测值为  当 f(x_i,j) >0,说明该特征对目标值的预测起到了正向作用;反之,该特征与目标预测值有相反作用。因此Shap不仅给出特征影响力的大小,也反映出每一个样本中的特征的影响力的正负性。 基于上述训练的xgboost模型,计算变量的shap值。import shapexplainer = shap.TreeExplainer(trained_xgb) # 引用package并且获得解释器 explainershap_values = explainer.shap_values(data[cols]) # 获取训练集data各个样本各个特征的SHAP值 y_base = explainer.expected_value # 模型的基线值ybase就是训练集的目标变量的拟合值的均值单个样本的Shap值j = 25 player_explainer = pd.DataFrame() player_explainer['feature'] = cols player_explainer['feature_value'] = data[cols].iloc[j].values player_explainer['shap_value'] = shap_values[j] player_explainer 对于单个样本的Shap分析,还可以用可视化功能,下图是对上面计算出的shap value的可视化表示,蓝色表示该特征的贡献是负数,红色则表示该特征的贡献是正数。 shap.initjs() shap.force_plot(explainer.expected_value, shap_values[j], data[cols].iloc[j],link='logit') 对特征的总体分析 对特征的总体分析在整体样本上,进行不同特征shap值的分布展示,下图中每一行代表一个特征,横坐标为Shap值。一个点代表一个样本,颜色越红说明特征本身数值越大,颜色越蓝说明特征本身数值越小。可以直观地看pre_max_overdue_m6是一个很重要的特征,而且基本上是与target成正相关的(target为1代表逾期),即历史近6个月最大逾期天数越大,则逾期概率越大。 shap.summary_plot(shap_values, data[cols]) 与feature importance类似,需要在整体样本上来评估变量的重要性,每个特征在整体样本上的Shap绝对值取平均值来代表该特征的重要性,因此shap均值越大,则特征越重要。 shap.summary_plot(shap_values, data[cols], plot_type="bar") 部分依赖图 部分依赖图Shap提供了部分依赖图的功能,纵坐标为Shap值,横坐标为变量分布。可以看到历史逾期天数越大,对target预测为1的影响越大,当逾期天数大到一定阈值,Shap达到峰值不变,也就是基本可以判断为逾期样本。 shap.dependence_plot('pre_max_overdue_m6', shap_values, data[cols], interaction_index=None, show=False)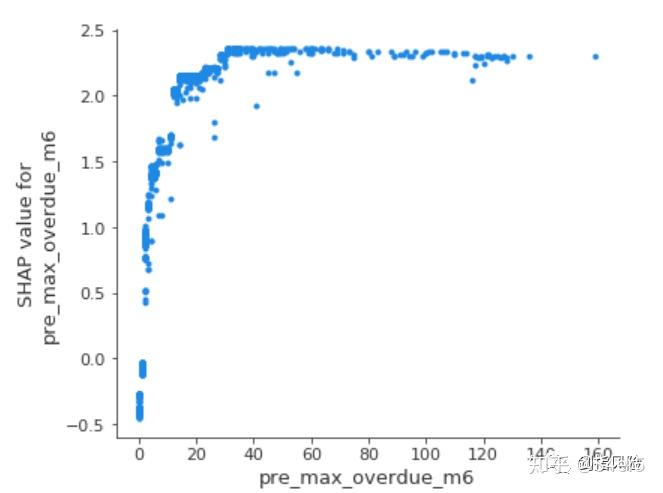 小结 小结以上基于风控信贷样本简单对几个变量进行了xgboost特征重要性、shap value的实现,对可解释性的探索对机器学习应用于风控模型有着重要的实践意义,欢迎探讨更多关于模型可解释性方法~ |
【本文地址】
今日新闻 |
推荐新闻 |