基于参数化模型(MANO)的手势姿态估计 |
您所在的位置:网站首页 › shapes什么意思啊 › 基于参数化模型(MANO)的手势姿态估计 |
基于参数化模型(MANO)的手势姿态估计
|
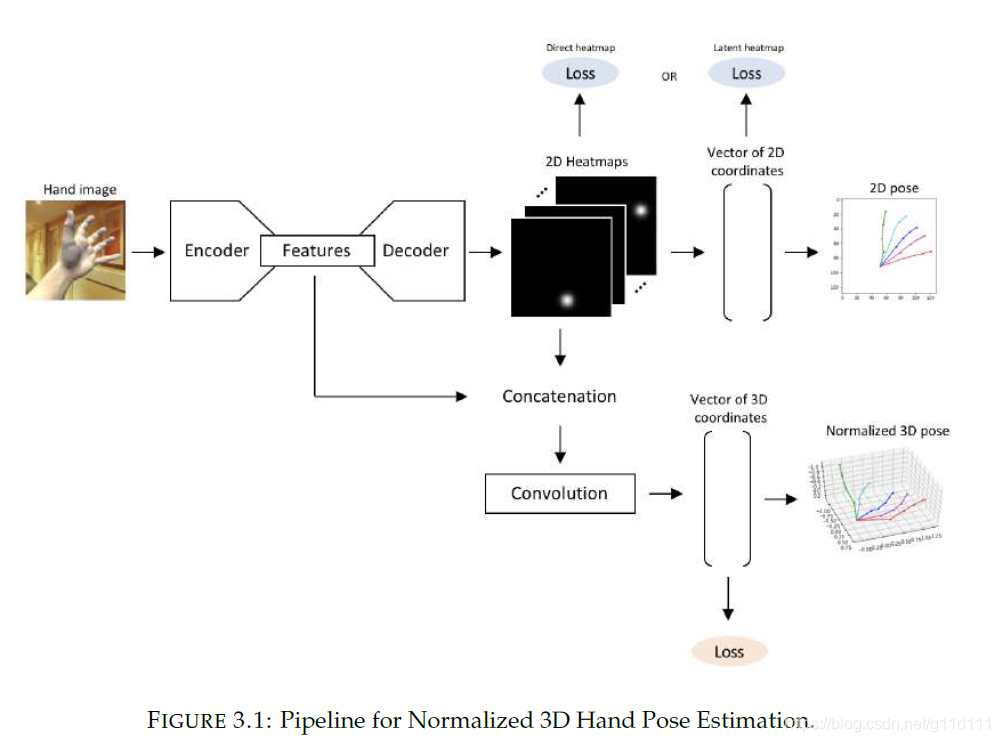
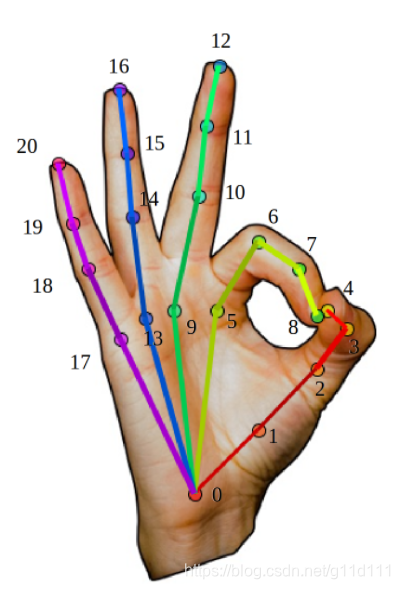
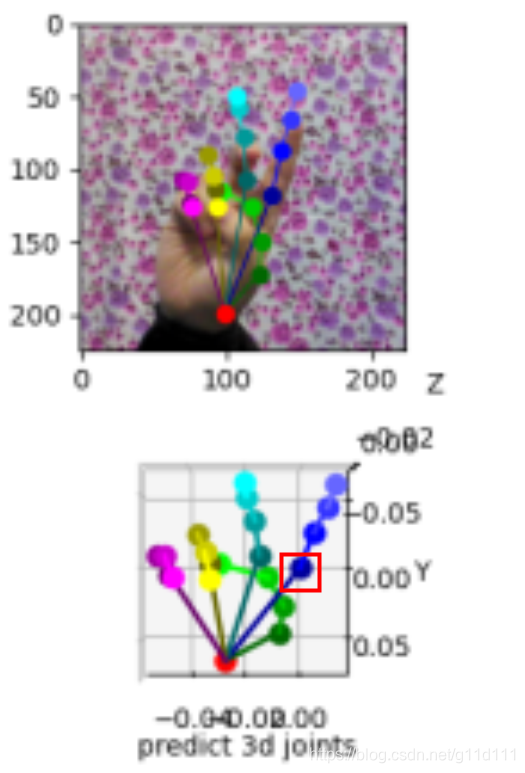
目前, 主流的手部姿态估计的技术方案是使用马普所于2017年提出的MANO参数化模型, 在此基础上回归3D坐标, 这是因为MANO有很合理的结构以及定义好的前向动力学树。本文的目的在于为大家介绍,基于MANO的手部姿态估计的流程:包括并不限于: 数据处理,MANO的推理流程(与论文对齐),手的解剖学和生物学特点。 1. 什么是手部姿态估计?我理解的 手部姿态估计(hand pose estimation) 是: 同人体姿态估计一样, 是给定一张手部特写图片,估计其姿态(2D/3D keypoint)的位置(通常是21个). 下图是一个最经典的实现(无参数化模型): 将一个手部特写图片(hand image)输入Encoder-Decoder结构中,从Decoder输出的特征图中,选取响应最大的位置,与ground truth生成2D landmark的热力图计算loss,目的是让Decoder生成的特征图在手部的不同位置有对应的响应,即从point of interest (PoI)变为构造一种regional of interest (RoI)的表示, 即让网络从关注某个确定的点,到关注一个范围, 以此扩大模型的泛化能力以及对复杂情况下的估计鲁棒性. 这种方法在参数化模型MANO/SMPL出现之前,是姿态估计领域的主流叙事. 此图来自2018年,Olha CHERNYTSKA(毕业于乌克兰天主教大学)的硕士毕业论文[3]. 其中3D keypoint的坐标一般用相对坐标系表示, 对手部来说,一般会选择手腕(下图的0)/食指和手掌连接关节(下图5)作为局部坐标系的原点(0, 0, 0). 这种做法也叫做root-relative.
下图是以上图的节点5为原点的相对3D坐标表示,以下图为例, 我们想让节点5的坐标为(0, 0, 0),在实践中,大家的做法一般很简单(伪代码): img = cv2.imread("xxx.jpg") # 1) 读取手部特写图片 img = normalize(img) # 2) 对图片进行处理(规则化等) pred_3d = Net(img) # 3) 送入网络进行预测 pred_3d -= pred_3d[5] # 4) 将预测结果变为root-relative的方式.
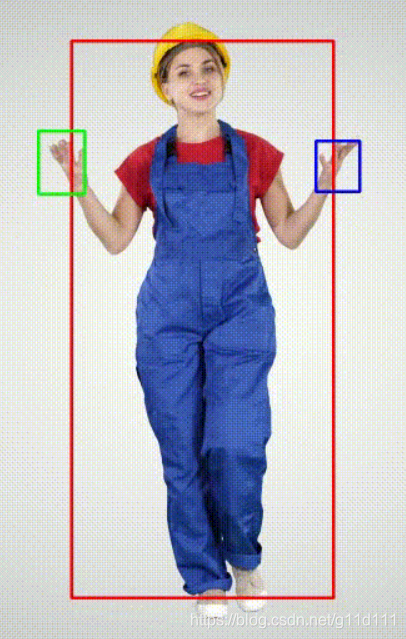
红框就是节点5,可见其坐标为(0, 0, 0). 2. MANO是什么?近年来, CVPR, ECCV, ICCV的手部姿态估计论文,基本或多或少的都是model-based, 即基于参数化模型的方案。而其中,最主流的参数化模型就是Javier Romero, Dimitrios Tzionas, Michael J. Black于2017年发表于Siggraph Asia的《Embodied Hands: Modeling and Capturing Hands and Bodies Together》[1]. 这篇文章也是在马普所和工业光魔联合提出的《SMPL: A Skinned Multi-Person Linear Model(2015)》[2]的基础上,提出了针对手部的参数化模型,其主要目的是: To cope with low-resolution, occlusion, and noise, we develop a new model called MANO (hand Model with Articulated and Non-rigid defOrmations). 我的个人感受是,由于手势姿态估计的问题是: 自遮挡: 以下图为例,中指到小指都被手背挡住了. 手抓握物体导致的遮挡: 分辨率低: 手部在整个构图中的所占像素比例非常小,对正确估计其手势增加了难度. 确实,在全身/半身的时候, 手势相比整体来说所占的像素非常小 ,所以 难 以分辨其动作 MANO这个模型,相当于在图片 ->3D pose中间加了一个过渡表示(或者说加上了强经验prior,从而能够预测遮挡和低分辨率的图像). 图来自Frankmocap仓库[4] 用不带先验信息的方法,即model-free的方法,对于这些情况的姿态估计效果通常就会失败。而自从有了参数化模型MANO,由于MANO是由 “1000 high-resolution 3D scans of hands of 31 subjects in a wide variety of hand poses.” 得到,其中包括抓握,不良光照等场景。 所以,根据18年以来的众多手部姿态分析工作表明:使用MANO参数化模型,对于估计出一个合理且准确的手部姿态,有至关重要的作用。 需要注意的是,由于手部是分段刚性的(articulated objects), 因此手部的建模还是有一定难度的,马普所用了来自美国亚特兰大的3dMD公司的扫描设备,估计花费不菲…, 至于MANO是怎么制作的,这里我不详细展开,有兴趣的朋友可以直接在文章下面问。
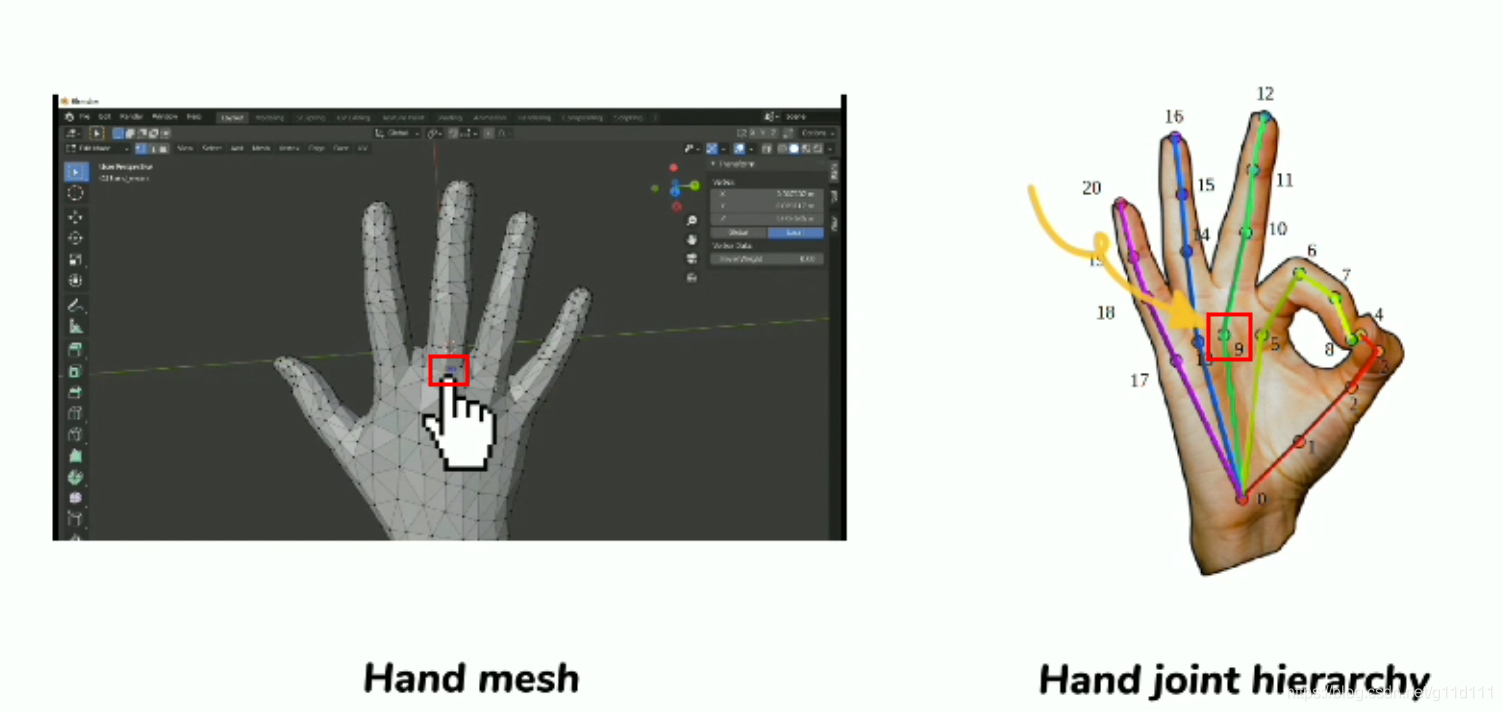
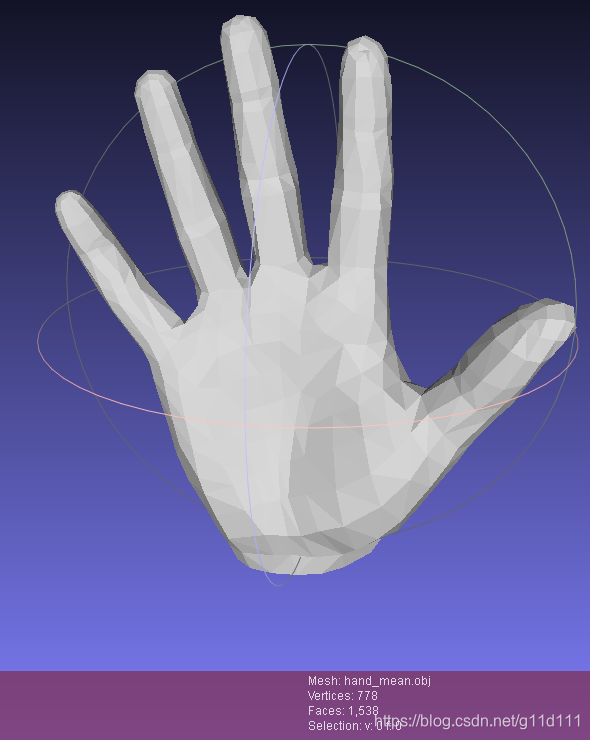
图来自中科大刘利刚老师的games102课程[5]. 那么,MANO作为一个 3D参数化模型,其参数都有哪些呢? 778个vertices 1538个faces,并根据 16个 关键点 +从顶点中获取 5个 手指指尖的点, 构成完整的手部链条,或者叫做前向动力学树 (forward kinematic tree). 下图来自牛津大学的CVPR2019论文[7]《3D Hand Shape and Pose from Images in the Wild》.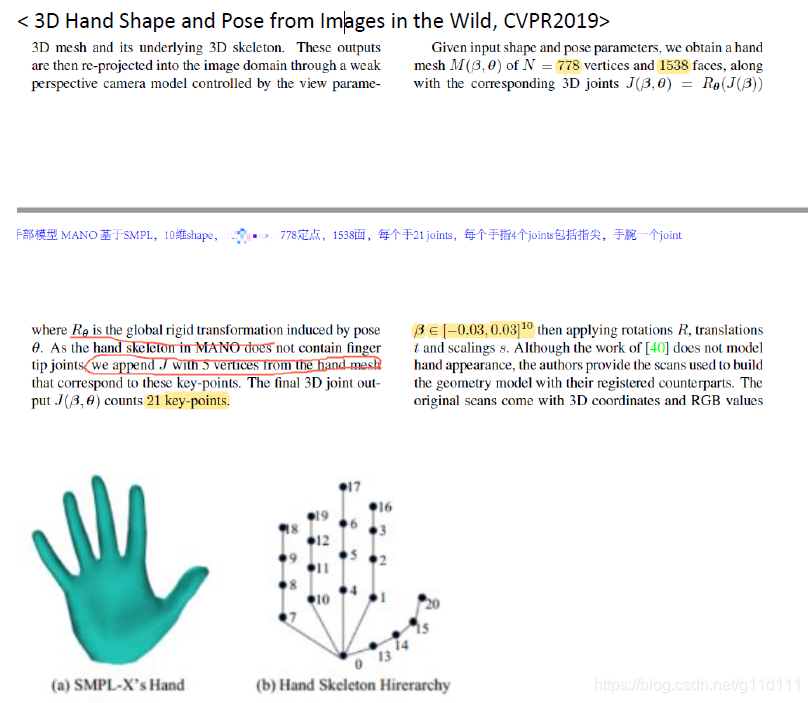
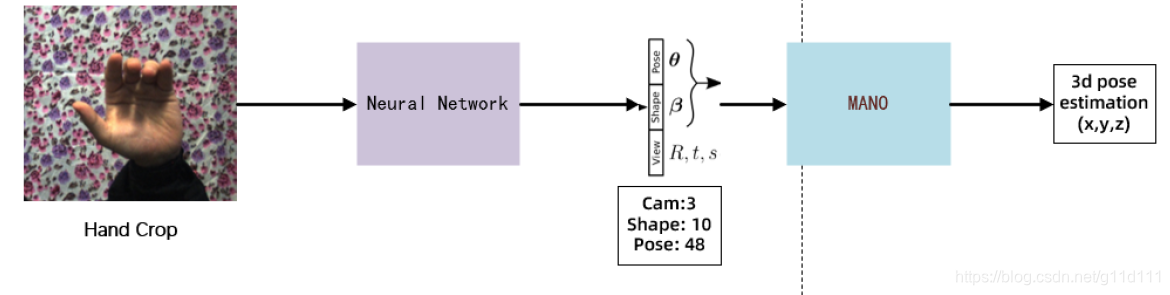
(即图中的 ,16,17,18,19,20都是由变形后的 vertex中按照规定规则取到的 , 代码. 以节点9为例,其3D坐标可以在变形后的Mesh上,根据其所在顶点(vertex)去提取。 如下图所示, 手部的crop图片送入神经网络,预测得到 MANO所需的61个参数的值,其中包含 MANO所需的相机参数 (前 3个 ), θ(3-51), β(51:61),其中θ是MANO中用于控制pose的参数,β则是 MANO中用于控制shape的参数。 其中,神经网络的设计就比较简单,只要按照输入和输出的结构设计就行, 最经典的实现方案是UCB和马普所合作的CVPR2018论文: HMR[6], 其使用了auto-regressive的方式去优化预测的MANO所需的61个系数. 输入(bs,3,224,224) 为图像处理后得到的Tensor(NCHW,图像的分辨率可以按照自己的需求调整), bs是batch size. 输出为(bs, 61) 得到MANO所需的参数, 这些参数输入MANO, 我们就可以得到3D的pose estimation结果(相对坐标系下的21个关键点的xyz位置). 3.1 MANO的计算逻辑下图来自CVPR2020的《Minimal-Hand》[8], 其把MANO的流程简单用两个公式概况了: 可以看到, MANO的
T
‾
\overline{T}
T是一个手掌摊平的姿势, 在动画领域,一般称为T型姿势(T-pose).  3.2 MANO的实际计算流程
3.2 MANO的实际计算流程
好了,在了解了MANO的基本流程后,让我们回归正题,本篇文章的目的 是分析 MANO究竟是如何处理cam, shape, pose的参数,来得到 (21, 3)的 joint rotation(axis-angle表示)的? 这里以下面的的rot_pose_beta_to_mesh函数为核心进行分析, 其中, rot_pose_beta_to_mesh接收3个入参, 拼起来正好是网络预测出来的61个参数: rots ∈ R 3 \in R^{3} ∈R3 root节点(手腕CMC)的旋转axis-angle.poses ∈ R 45 \in R^{45} ∈R45 除每个手指指尖外(除TIP这一排)和手腕外,所有的关键点的axis-angle (15*3=45), 下图来自ECCV2020 BMC[9]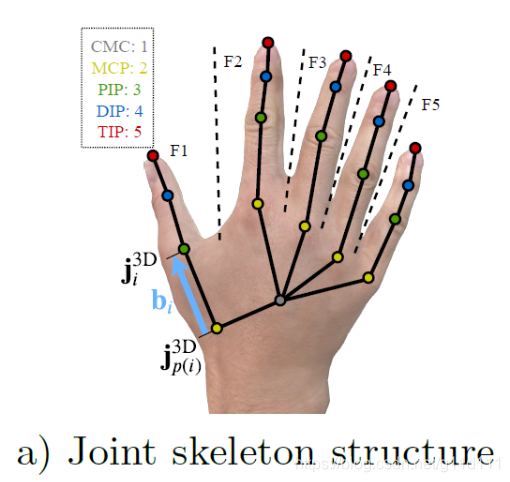
手部的骨骼分为灰色的手腕(CMC), 黄色的MCP(手掌和各个手指的交界处), 绿色的PIP, 蓝色的DIP以及表示指尖位置的骨骼TIP。 可见,骨骼是“横着”来命名的… betas ∈ R 10 \in R^{10} ∈R10 mano所需要的shape参数 3.2.1 MANO的一些参与计算的重要参数kintree_table, parent 等动力学与继承关系参数 如下图所示,parent和 kintree_table组建了手势的链条 hands_mean: 和 mesh_mu类似,这里的 hands_mean应该 是rest的手的axis-angle, 其用法是用来加上网络预测的 pose (axis-angle),再对其进行处理。 需要注意的是,这里的pose除了不包含TIP骨骼外,还不包括手腕. mesh_mu: 下图 (MANO2017[1])的公式 2的
T
‾
\overline{T}
T. 即平均 shape。 mesh_pca: 对应最大的 shape特征值的特征向量 , 因为 shape是根据pca取最大的 10维参数作为 shape的,这里的 mesh_pca根据其用法,是公式 4(MANO2017)里面的Sn。 J_regressor: 对应 (SMPL2015)的公式10, 其目的是: 将mesh上的顶点 (vertices)变为节点 (joints). root_rot: 根节点, 是指手腕的那个点 即下图的 0点 ,我理解这里应该是用这种方式来计算相对的距离。 posedirs: 根据之前的分析, posedirs就是MANO(2017)中公式3中的Pn, 表示pose的blend shape参数. weights: weights就是3.1中公式2 M ( β , θ ) = W ( T ( θ , β ) , θ , β , W , J ( θ ) ) M(\beta, \theta) = \mathbf{W}(T(\theta, \beta), \theta, \beta, W, J(\theta)) M(β,θ)=W(T(θ,β),θ,β,W,J(θ))的 W W W. 3.2.2 旋转矩阵计算(Rodrigues)这里主要分析的是rodrigues函数,此函数的目的是把轴向角(axis-angle)变为旋转矩阵(rotation matrix)[10]. 等于SMPL2015的公式 (1), S(n_)函数对应的就是上面的Skew(V). |
 图来自[1].
图来自[1].



 变形示意图:
变形示意图: 
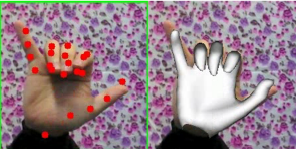
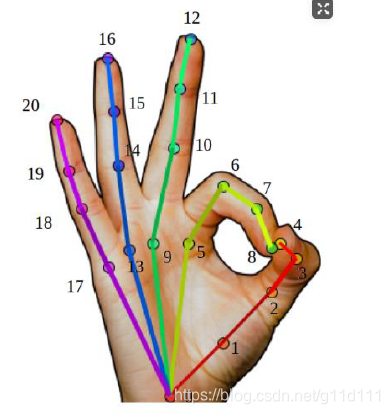
 注意,kintree_table是 不包含指尖 的 !!(只有 16个 joints 15个手指的 joints+1个 wrist joint),也符合 MANO定义的结构形式,即没有上图的(4,8,12,16,20)这5个点.
注意,kintree_table是 不包含指尖 的 !!(只有 16个 joints 15个手指的 joints+1个 wrist joint),也符合 MANO定义的结构形式,即没有上图的(4,8,12,16,20)这5个点.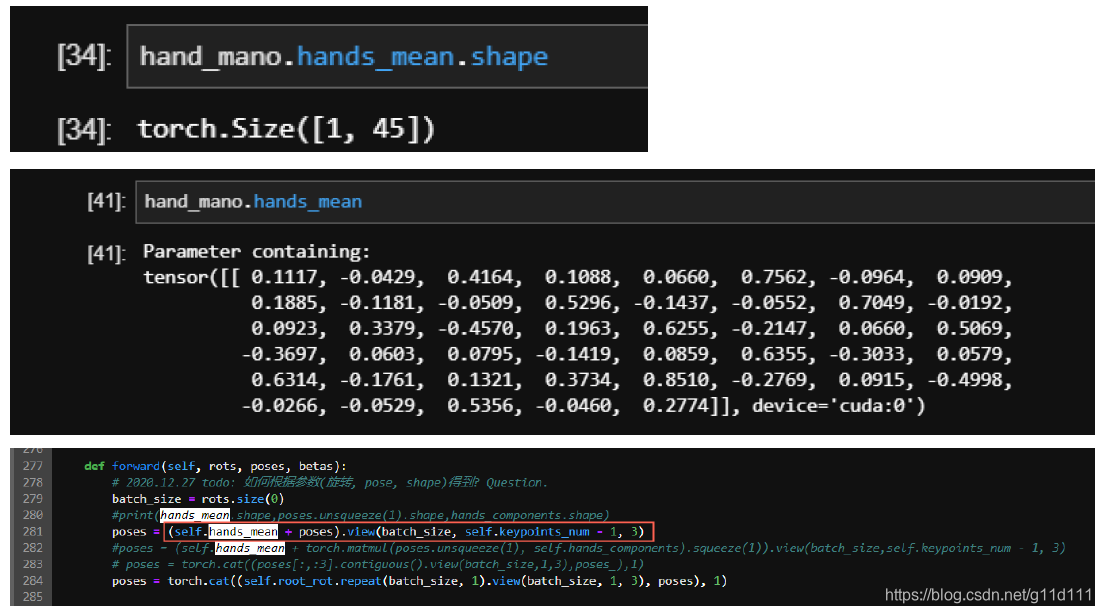
 公式2的计算得到的
T
p
T_p
Tp对应代码中的
v
p
o
s
e
d
v_{posed}
vposed:
公式2的计算得到的
T
p
T_p
Tp对应代码中的
v
p
o
s
e
d
v_{posed}
vposed: 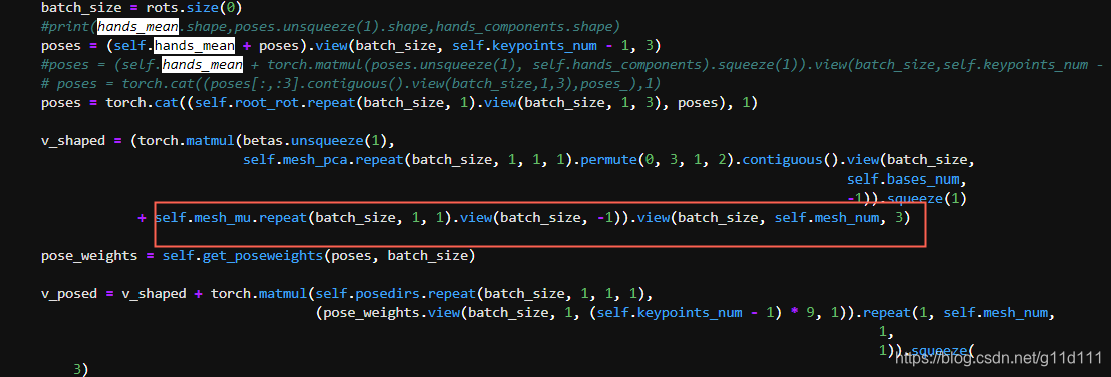
 对应代码:
对应代码: 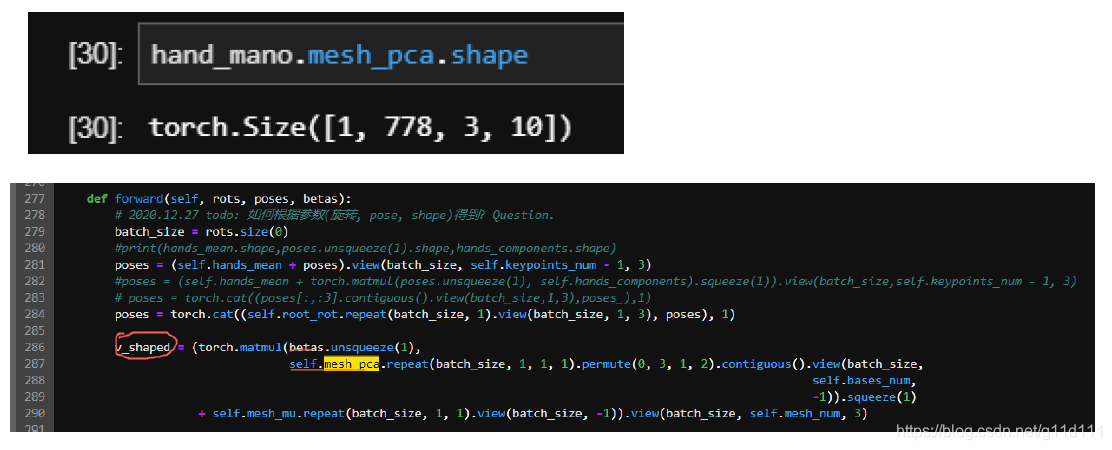

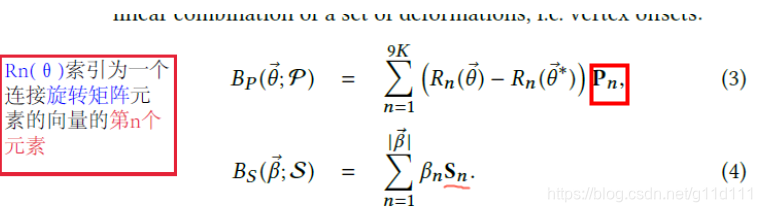
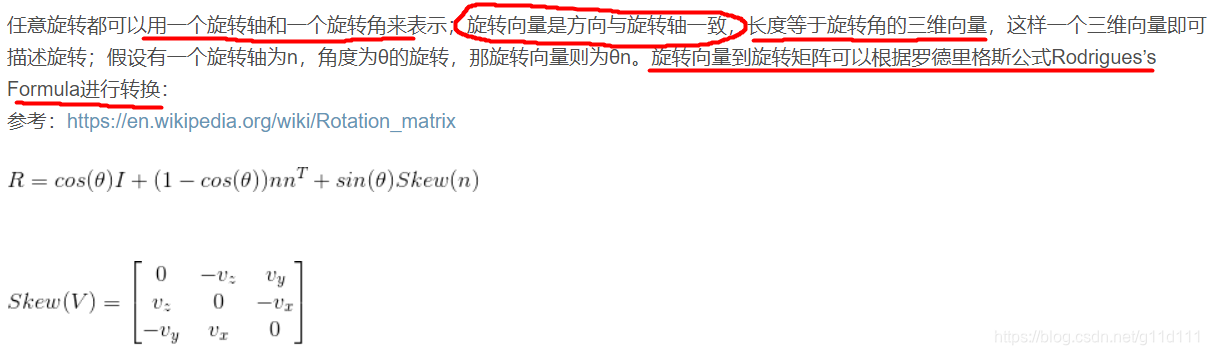 下面代码里的n等于下图(SMPL2015)的unit norm axis of rotation
w
‾
\overline{w}
w, R
下面代码里的n等于下图(SMPL2015)的unit norm axis of rotation
w
‾
\overline{w}
w, R
【本文地址】
今日新闻 |
推荐新闻 |