关于Sequence2Sequence模型/RNN/LSTM/attention机制 |
您所在的位置:网站首页 › sequence2sequence原理 › 关于Sequence2Sequence模型/RNN/LSTM/attention机制 |
关于Sequence2Sequence模型/RNN/LSTM/attention机制
|
Sequence2Sequence:
看一下RNN的构造: 因此,这种对序列的记忆方式,就可以拿来用于作为encoder或者decoder. 但是还有问题,就是RNN的特点决定了一旦序列比较长,序列前边的信息容易被序列后面的信息覆盖。(更倾向于记得刚给它的那部分了,前面的忘记了),怎么办? 用LSTM ——LSTM对比看下rnn到lstm的结构变化: 好的,现在我们知道了,sequence2sequence 是怎么回事,然后为啥他的encoder-decoder要经历了一个从RNN到LSTM的过程了。 现在还有一点小问题,就是吧,输出序列是很依赖encoder最后输出的隐藏状态决定的context vector的(HS3),但是如果要输出的是个长序列,随着decoder的time step,走到后面这个context vector已经丢失了初始的那个context vector的信息了(从HS3到HS5)。这肯定不太行。
但是,问题又来了, 1.这个新的context vector怎么用?(怎么协调使用new context vector和timestep t下的vector) 2.加权系数怎算? 第一个问题,用concate解决 生成的新向量,我们叫做attention hidden vector,这个vector代替了隐藏状态。(AHS1其实就是 attention hidden state) |
 输入:序列A 输出:序列B 黑盒子即我们说的encoder-decoder结构,用来实现序列到序列的转换。 那么encoder-decoder结构为啥用RNN呢?
输入:序列A 输出:序列B 黑盒子即我们说的encoder-decoder结构,用来实现序列到序列的转换。 那么encoder-decoder结构为啥用RNN呢? RNN设计为接受两个输入:“当前的输入”和以前所有输入的“整体记忆” cell接受了上面两个输入之后,就会吐出一个输出,更新一下整体记忆。 它把对序列的整体记忆以隐藏状态的形式呈现。
RNN设计为接受两个输入:“当前的输入”和以前所有输入的“整体记忆” cell接受了上面两个输入之后,就会吐出一个输出,更新一下整体记忆。 它把对序列的整体记忆以隐藏状态的形式呈现。
 三个门的引入(遗忘门、输入门、输出门) 第一步:从cell中决定丢弃什么信息 ----得到ft 第二步:决定cell中存储哪些新信息 ----得到c~(t) 这两步之后,我们就能成功把cell从旧状态更新到新状态 这就解决了对于长序列记不住前面信息的问题。
三个门的引入(遗忘门、输入门、输出门) 第一步:从cell中决定丢弃什么信息 ----得到ft 第二步:决定cell中存储哪些新信息 ----得到c~(t) 这两步之后,我们就能成功把cell从旧状态更新到新状态 这就解决了对于长序列记不住前面信息的问题。 那怎么办?
那怎么办? 我现在把encoder每个time step出来的隐状态都拿出来,做个加权,作为我decoder状态下新新的context vector,这样,不管输出的句子多长都没问题。 最简单就是做加权
我现在把encoder每个time step出来的隐状态都拿出来,做个加权,作为我decoder状态下新新的context vector,这样,不管输出的句子多长都没问题。 最简单就是做加权 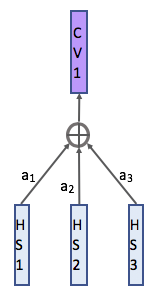
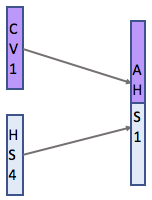 第二个,利用一个对齐模型,这个对齐模型是和sequence2sequence模型一起训练的。模型计算输入(由hidden state表示)和以前的输出(由attention hidden state表示)之间的匹配得分,然后为每一个输入和输出做好匹配。然后,将softmax应用于所有这些得分,并且得出的数字是每个输入的注意力得分。
第二个,利用一个对齐模型,这个对齐模型是和sequence2sequence模型一起训练的。模型计算输入(由hidden state表示)和以前的输出(由attention hidden state表示)之间的匹配得分,然后为每一个输入和输出做好匹配。然后,将softmax应用于所有这些得分,并且得出的数字是每个输入的注意力得分。  那么,我们已经知道了哪一部分是对预测实例最重要的了。 最后整个模型就是:
那么,我们已经知道了哪一部分是对预测实例最重要的了。 最后整个模型就是: 
【本文地址】
今日新闻 |
推荐新闻 |