Linux命令:sed |
您所在的位置:网站首页 › sed的命令psd的功能 › Linux命令:sed |
Linux命令:sed
|
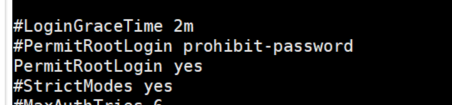
sed 是一个比较古老的,功能十分强大的用于文本处理的流编辑器,加上正则表达式的支持,可以进行大量的复杂的文本编辑操作。sed 本身是一个非常复杂的工具,有专门的书籍讲解 sed 的具体用法,但是个人觉得没有必要去学习它的每个细节,那样没有特别大的实际意义。我们经常在 Dockerfile 文件中看到 sed -i 之类的语句,故此研究了解一些 sed 命令。 一、sed 简介1、sed 是什么 sed 全名为 stream editor,流编辑器,用程序的方式来编辑文本,功能相当的强大,可以在大多数操作系统中使用。 sed 的出现作为 grep 的继任者,与vim等编辑器不同,sed 是一种非交互式编辑器(即用户不必参与编辑过程),它使用预先设定好的编辑指令对输入的文本进行编辑,完成之后再输出编辑结构。sed 基本上就是在玩正则模式匹配,所以,玩sed的人,正则表达式一般都比较强。 2、sed 工作原理 sed 会一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,成为"模式空间",接着用 sed 命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。 3、正则表达式的匹配过程 简单描述一下正则表达式的匹配过程,就是拿正则表达式所表示的字符串去和原文字符串内容去匹配,直到匹配到原文内容字符串中的一个完整子串就表示匹配成功。举个例子,有一行文件内容 "this is better desk",这里用"esk"去匹配,匹配过程是这样的:首先拿e去匹配文件行内容,从this开始,直到better的e,第一个字符匹配成功,接着s去匹配better字符e后边的t字符,没有匹配成功;然后重新拿esk中的e去和better的第二个t去匹配,没有成功,接着原始内容的下一个字符,直到desk中的e字符,逐个匹配s,k字符,到此为止,esk成功匹配,正则表达式匹配完毕。整个过程就是这样,即使再复杂的正则表达式的匹配过程也是按照此过程来进行的。 二、sed 基本语法 # sed [-nefr] [动作] 选项与参数: -n :使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN 的数据一般都会被列出到终端上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来。 -e :直接在命令列模式上进行 sed 的动作编辑; -f :直接将 sed 的动作写在一个文件内, -f filename 则可以运行 filename 内的 sed 动作; -r :sed 的动作支持的是延伸型正规表示法的语法。(默认是基础正规表示法语法) -i :直接修改读取的文件内容,而不是输出到终端。 动作说明: [n1[,n2]]function n1, n2 :不见得会存在,一般代表『选择进行动作的行数』,举例来说,如果我的动作是需要在 10 到 20 行之间进行的,则『 10,20[动作行为] 』 function: a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~ c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行! d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚; i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行); p :列印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~ s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦!sed -i 就是直接对文本文件进行操作的 sed -i 's/原字符串/新字符串/' /home/1.txt sed -i 's/原字符串/新字符串/g' /home/1.txt这两条命令的区别就是和正则表达式一样,加了 g 就是每行都全局替换。没有 g 就是每行只替换第一个匹配的。比如: #cat 1.txt d ddd #ff sed -i 's/d/7523/' /home/1.txt 执行结果 7523 7523dd #ff // 只替换每行的第一个 sed -i 's/d/7523/g' /home/1.txt 执行结果 7523 752375237523 #ff // 每行全部替换其他命令例子 // 去掉 “行首” 带“@”的首字母@ sed -i 's/^@//' file // 特定字符串的行前插入新行 sed -i '/特定字符串/i 新行字符串' file // 特定字符串的行后插入新行 sed -i '/特定字符串/a 新行字符串' file // 特定字符串的删除 sed -i '/字符串/d' file1、选项 -e:如果需要用sed对文本内容进行多种操作,则需要执行多条子命令来进行操作 // 例子1: echo -e 'hello world' | sed -e 's/hello/A/' -e 's/world/B/' // 结果:A B // 例子2: echo -e 'hello world' | sed 's/hello/A/;s/world/B/' // 结果:A B说明:例子1和例子2的写法的作用完全等同,可以根据喜好来选择,如果需要的子命令操作比较多的时候,无论是选择-e选项方式,还是选择分号的方式,都会使命令显得臃肿不堪,此时使用-f选项来指定脚本文件来执行各种操作会比较清晰明了。 2、选项-i:sed默认会把输入行读取到模式空间,简单理解就是一个内存缓冲区,sed子命令处理的内容是模式空间中的内容,而非直接处理文件内容。因此在sed修改模式空间内容之后,并非直接写入修改输入文件,而是打印输出到标准输出。如果需要修改输入文件,那么就可以指定-i选项。 // 例子1:不加 -i,原文件没变,只是输出 cat file.txt hello world [root@localhost]# sed 's/hello/A/' file.txt A world [root@localhost]# cat file.txt hello world // 例子2:加上 -i,不输出,但是修改了原文件 [root@localhost]# sed -i 's/hello/A/' file.txt [root@localhost]# cat file.txt A world // 例子3: [root@localhost]# sed –i.bak 's/hello/A/' file.txt说明:最后一个例子会把修改内容保存到file.txt,同时会以file.txt.bak文件备份原来未修改文件内容,以确保原始文件内容安全性,防止错误操作而无法恢复原来内容。 3、选项-f:还记得 -e 选项可以来执行多个子命令操作,用分号分隔多个命令操作也是可以的,如果命令操作比较多的时候就会比较麻烦,这时候把多个子命令操作写入脚本文件,然后使用 -f 选项来指定该脚本。 // 例子1: echo "hello world" | sed -f sed.script // 结果:A B // sed.script脚本内容: s/hello/A/ s/world/B/ // 说明:在脚本文件中的子命令串就不需要输入单引号了。4、选项-r:sed命令的匹配模式支持正则表达式的,默认只能支持基本正则表达式,如果需要支持扩展正则表达式,那么需要添加-r选项。 echo "hello world" | sed -r 's/(hello)|(world)/A/g' // A A 三、数字定址和正则定址1、关于定址的概念 默认情况下sed会对每一行内容进行匹配、处理、输出,某些情况不需要对处理的文本全部编辑,只需要其中的一部分,比如1-10行,偶数行,或者是包含"hello"字符串的行,这种情况下就需要我们去定位特定的行来处理,而不是全部内容,这里把这个定位指定的行叫做"定址"。 2、数字定址 数字定址其实就是通过数字去指定具体要操作编辑的行,数字定址有几种方式,每种方式都有不同的应用场景,下边以举例的方式来描述每种数字定址的用法。 // 例子1:将第4行中hello字符串替换为A,其它行如果有hello也不会被替换。 sed –n ‘4s/hello/A/’ message // 例子2:将第2-4行中hello字符串替换为A,其它行如果有hello也不会被替换。 sed –n ‘2,4s/hello/A/’ message // 例子3:从第2行开始,再接着往下数4行,也就是2-6行,这些行会把hello字符替换为A sed –n ‘2,+4s/hello/A/’ message // 例子4:第4行开始,到第6行。解释6的由来,"4,~3"表示从4行开始到下一个3的倍数,这里从4开始算,那就是6了,当然9就不是了,因为是要求3的第一个超过前边数字4的倍数,感觉这种适用场景不会太多。 sed –n ‘4,~3s/hello/A/’ message // 例子5:从第4行开始,每隔3行就把hello替换为A。比如从4行开始,7行,10行等依次+3行。这个比较常用,比如3替换为2的时候,也就是每隔2行的步调,可以实现奇数和偶数行的操作。 sed –n ‘4~3s/hello/A/’ message // 例子6:$符号表示最后一行,和正则中的$符号类似,但是第1行不用^表示,直接1就行了。 sed –n ‘$s/hello/A/’ message // 例子7:!符号表示取反,该命令是将除了第1行,其它行hello替换为A,上述定址方式也可以使用!符号。 sed -n ‘1!s/hello/A/’ message3、正则定址:正则定址使用目的和数字定址完全一样,使用方式上有所不同,是通过正则表达式的匹配来确定需要处理编辑哪些行,其它行就不需要额外处理。 // 例子1:将匹配到nihao的行执行删除操作。 sed -n ‘/nihao/d’ message // 例子2:删除空行 sed -n ‘/^$/d’ message // 例子3:匹配以TS开头的行到TE开头的行之间的行,把匹配到的这些行删除 sed -n ‘/^TS/,/^TE/d’ message4、数字定址和正则定址混用 sed -n ‘1,/^TS/d’ message // 说明:匹配从第1行到TS开头的行,把匹配的行删除。5、关于定址的分组命令 // 例子1:该命令表示将从TS开头的行到TE开头的行之间范围的行内容中CN替换为China,并且把Beijing替换为BJ,类似于多命令之间用分号的那种方式,不过这样定址代码只写了一遍,相当于执行了一条子命令。 /^TS/,/^TE/{ s/CN/China/ s/Beijing/BJ/ } // 例子2:效果类似例子1 sed -n ‘2,3s{/cn/china/;/a/b/}’ message6、sed定址的总结 sed 默认的命令执行范围是全局编辑的,如果不明确指定行的话,命令会在所有输入行上执行。 如果想仅对其中部分行执行命令,可以使用地址限制。 如果给了 2 个地址,即地址对(地址范围),则命令匹配的这个地址范围内执行,但是需要注意的是:对于像 "addr1,addr2" 这种形式的地址匹配,如果addr1 匹配,则匹配成功,"开关"打开,在该行上执行命令,此时不管 addr2 是否匹配,即使 addr2 在 addr1 这一行之前;接下来读入下一行,如果addr2 匹配,则执行命令,同样开关"关闭";如果 addr2 在 addr1 之后,则一直处理到匹配为止,换句话说,如果 addr2 一直不匹配,则开关一直不关闭,因此会持续执行命令到最后一行。 四、基本子命令1、子命令 a:表示在指定行下边插入指定行的内容。 // 例子1:将message文件中每一行下边都插入添加一行内容是A sed ‘a A’ message // 例子2:将message文件中1-2行的下边插入添加一行内容是A sed ‘1,2a A’ message // 例子3:将message文件中1-2行的下边分别添加3行,3行内容分别是A、B、C,这里使用了\n,插入多行内容都可以按照这种方式来实现。 sed ‘1,2a A\nB\nC’ message这里有个应用实例:修改 ssh 的配置 —— sed -i '/#PermitRootLogin prohibit-password/a PermitRootLogin yes' /etc/ssh/sshd_config
2、子命令 i:和 a 使用上基本上一样,只不过是在指定行上边插入指定行的内容。 3、子命令 c:表示把指定的行内容替换为自己需要的行内容。 // 例子1:将message文件中所有的行内容都分别替换为A行内容。 sed ‘c A’ message // 例子2:将message文件中1-2行的内容替换为A // 注意这里说的是将1-2行所有的内容只替换为一个A内容,也就是1-2行内容编程了一行,定址如果连续就是这种情况。如果想把1-2行分别替换为A,可以参考下个例子的方式。 sed ‘1,2c A’ message // 例子3:将message中1-2行内容分别替换为了A,需要在替换内容上手动加换行\n,这样当然也可以将一行内容替换为多行内容。 sed ‘1,2c A\nA’ message4、子命令 d:表示删除指定的行内容,比较简单,更容易理解。 // 例子1:将message所有行全部删除,因为没有加定址表达式,所以平时如果需要删除指定行内容,需要在子命令前加定址表达式。 sed ‘d’ message // 例子2:将message文件中1-3行内容删除 sed ‘1,3d’ message5、子命令 y:表示字符替换,可以替换多个字符,只能替换字符不能替换字符串,且不支持正则表达式,具体使用方法看例子。 // 把message中所有a字符替换为A符号,所有b字符替换为B符号 sed ‘y/ab/AB/’ message // 强调一下,这里的替换源字符个数和目的字符个数必须相等;字符不支持正则表达式;源字符和目标字符每个字符需要一一对应。6、子命令 =:可以将行号打印出来。 sed ‘1,2=’ message // 结果 1 nihao 2 hello world 说明:将指定行的上边显示行号。7、子命令 r:类似于a,也是将内容追加到指定行的后边,只不过 r 是将指定文件内容读取并追加到指定行下边 sed ‘2r a.txt’ message // 将a.txt文件内容读取并插入到message文件第2行的下边。 五、子命令 s:为替换子命令,是平时sed使用的最多的子命令,没有之一。因为支持正则表达式,功能变得强大无比,下边来详细地说说子命令s的使用方法。 1、基本语法:[address]s/pattern/replacement/flags s 字符串替换,替换的时候可以把 / 换成其它的符号,比如=。 // replacement部分用下列字符会有特殊含义: >>> &:用正则表达式匹配的内容进行替换 >>> \n:回调参数 >>> \(\):保存被匹配的字符以备反向引用\n时使用,最多9个标签,标签书序从左到右 // Flags >>> n:可以是1-512,表示第n次出现的情况进行替换 >>> g:全局更改 >>> p:打印模式空间的内容 >>> w file:写入到一个文件file中2、实例用法 // 测试文件: # cat message hello 123 world // 例子1:将message每行包含的第一个hello的字符串替换为HELLO,这是最基本的用法 sed ‘s/hello/HELLO/’ message // 例子2:使用了扩展正则表达式,需要加-r选项 sed -r ‘s/[a-z]+ [0-9]+ [a-z]+/A/’ message // 替换结果:A // 例子3: sed -r ‘s/([a-z]+)( [0-9]+ )([a-z]+)/\1\2\3/’ message //结果:hello 123 world //说明:再看下一个例子就明白了。 //例子4: sed -r ‘s/([a-z]+)( [0-9]+ )([a-z]+)/\3\2\1/’ message //结果:world 123 hello //说明:\1表示正则第一个分组结果,\2表示正则匹配第二个分组结果,\3表示正则匹配第三个分组结果。 //例子5: sed -r ‘s/([a-z]+)( [0-9]+ )([a-z]+)/&/’ message //结果:hello 123 world //说明:&表示正则表达式匹配的整个结果集。 //例子6: sed -r ‘s/([a-z]+)( [0-9]+ )([a-z]+)/111&222/’ message //结果:111hello 123 world222 //说明:在匹配结果前后分别加了111、222。 //例子7: sed -r ‘s/.*/111&222/’ message //说明:在message文件中每行的首尾分别加上111、222。 //例子8: sed ‘s/i/A/g’ message //说明:把message文件中每行的所有i字符替换为A,默认不加g标记时只替换每行的第一个字符。 //例子9: sed ‘s/i/A/2’ message //说明:把message文件中每行的第2个i字符替换为A。 //例子10: sed -n ‘s/i/A/p’ message //说明:加-p标记会把被替换的行打印出来,再加上-n选项会关闭模式空间打印模式,因此该命令的效果就是只显示被替换修改的行。 //例子11: sed -n ‘s/i/A/w b.txt’ message //说明:把message文件中内容的每行第一个字符i替换为A,然后把修改内容另存为b.txt文件。 //例子12: sed -n ‘s/i/A/i’ message //说明:把message文件中每一行的第一个i或I字符替换为A字符,也即是忽略大小写更多详细用法可以看这篇文章:https://blog.csdn.net/qq_33468857/article/details/84324609 |
【本文地址】
今日新闻 |
推荐新闻 |