Scrapy爬虫框架 |
您所在的位置:网站首页 › scrap文件夹 › Scrapy爬虫框架 |
Scrapy爬虫框架
|
安装scrapy爬虫框架
可以使用镜像安装,安装速度比较快 pip install -i https://pypi.douban.com/simple/ scrapy 一般的安装方法 pip install scrapy 在安装过程中会遇到很多问题 error: Microsoft Visual C++ 14.0 is required. Get it with “Microsoft Visual C++ Build Tools”: http://landinghub.visualstudio.com/visual-cpp-build-tools 遇到上述错误,去安装 Microsoft Visual C++ Build Tools 即可,点击下载 (下载链接:https://go.microsoft.com/fwlink/?LinkId=691126) 有时也会因为 Twisted 安装失败出现此问题,如果有则下载安装, https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
进入下载目录,安装.whl文件 pip install xxx.whl 安装成功后再执行 pip install -i https://pypi.douban.com/simple/ scrapy 安装成功,如果还没成功根据错误进行百度,不再累赘 创建爬虫scrapy项目,IDE使用的是pycharm 创建命令 scrapy startproject 项目名称
其中有个文件夹 spiders 里边存放各种应用,如爬取知乎、链家、豆瓣等都放在里边就可以了, 如何创建一个spider 应用文件呢 还是看这张图,图上已经告诉我们了,你可以使用下边的命令开始你的第一个spider项目了 scrapy genspider example example.com scrapy genspider 是固定写法 example 是 spider 名称 example.com 是爬取的网站的域名 如创建伯乐在线的一个 spider ,首先进入项目aaaaa cd aaaaa scrapy genspider jobbole blog.jobbole.com
此时我们创建一个启动函数 main.py 用来启动整个项目,放在项目的根目录下 from scrapy.cmdline import execute import sys import os sys.path.append(os.path.dirname(os.path.abspath(__file__))) execute(['scrapy', 'crawl', 'jobbole']) # 设置可在命令行执行配置一下settings ROBOTSTXT_OBEY = False # 默认为True,过滤不规范的url在命令行内执行 scrapy crawl spider名称 scrapy crawl jobbole 在windows下执行此命令会报一个错,缺失win32api模块,可以先安装,再执行 pip install -i https://pypi.douban.com/simple pypiwin32 现在在jobbole.py中打一个断点,看一下是否执行成功 |
 cp37表示python3.7版本,amd64表示windows系统是64位的,不过一般安装上边的32位的就可以了
cp37表示python3.7版本,amd64表示windows系统是64位的,不过一般安装上边的32位的就可以了 在当前路径下创建了一个名叫 aaaaa 的项目
在当前路径下创建了一个名叫 aaaaa 的项目 

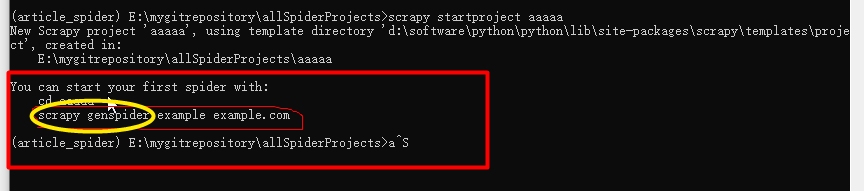
 创建成功
创建成功  bole.py 文件默认会生成如下片段(由模板生成)
bole.py 文件默认会生成如下片段(由模板生成) Debug 一个main文件
Debug 一个main文件  待执行完后,成功的话会自动执行到断点处,看下边的图片,url 已经拿到了,body是 url 对应的源代码
待执行完后,成功的话会自动执行到断点处,看下边的图片,url 已经拿到了,body是 url 对应的源代码  说明:我用的是Eclipse风格,settings->keymap->Eclipse
说明:我用的是Eclipse风格,settings->keymap->Eclipse  好,本节到此结束
好,本节到此结束【本文地址】
今日新闻 |
推荐新闻 |