|
本文转自:https://mp.weixin.qq.com/s?__biz=MzA4MTk3ODI2OA==&mid=2650342004&idx=1&sn=4d270ab7ca54f6f2f7ec7aca113993f4&chksm=87811487b0f69d91d2b3a072be22e50b436e342e05cea6c1e28c9ade4c814f8ba1a53118a69b&scene=0&xtrack=1#rd
前言
大致分析了下京东评论 相同手机型号的产品用的评论都是一样的,所以每个型号的爬一个就可以了; 每一个评论最多只能爬100页,每页10条, 加上好中差评 大概能有2000多条不重复的评论 {productId}就是对应产品的productId; {score}对应全部/好/中/差评 0:全部评价 1:差评 2:中评 3:好评
爬去评论
每个型号的找一个主页,爬取评论 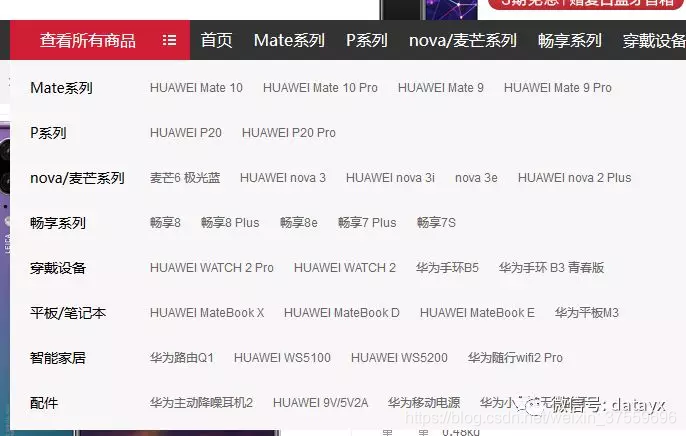
对应的html代码,用beautisoup分析网页,得到手机型号和herf
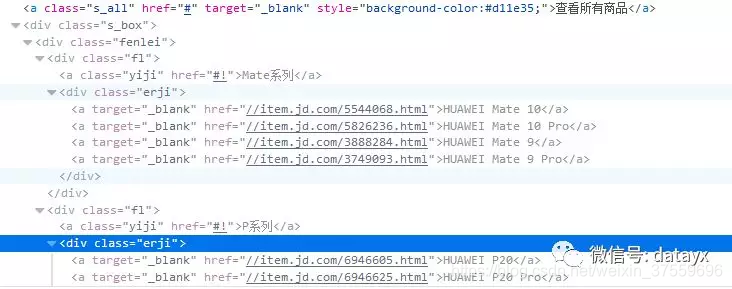
代码实现: 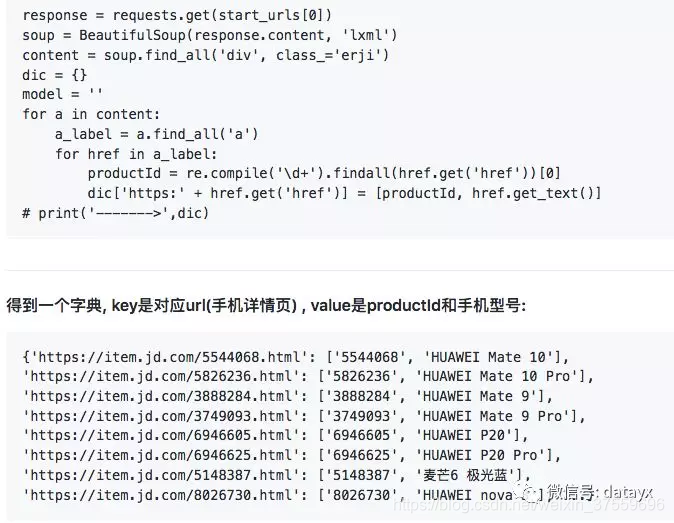

Start_requests:这里用的方法比较简单就是遍历循环,根据url三个参数,爬取每个手机型号的,好中差评评论,最后通过pipelines存入mongodb,代码实现: 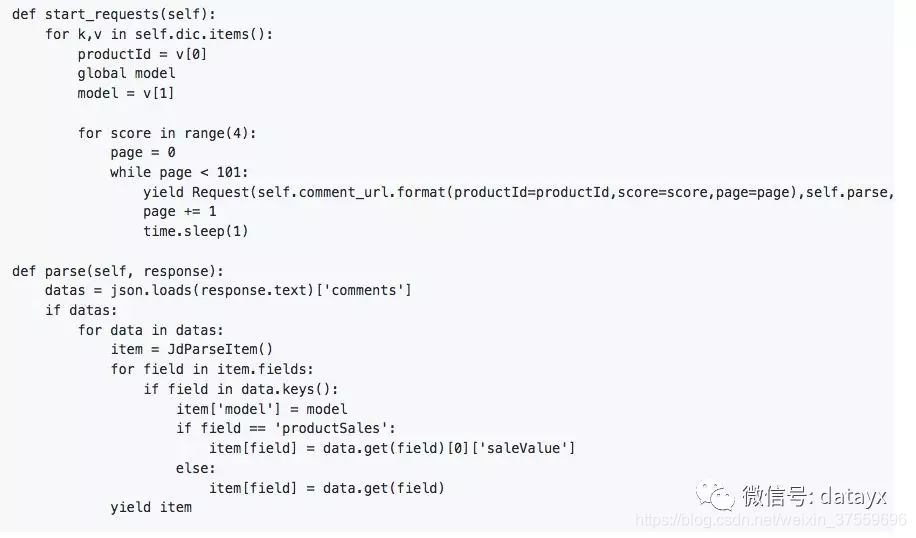
完整代码如下:
# -*- coding: utf-8 -*-
import re
import json
import time
import requests
from bs4 import BeautifulSoup
import scrapy
from scrapy import Spider,Request
from jd_parse.items import JdParseItem
class JdSpider(scrapy.Spider):
name = "jd"
allowed_domains = ["www.jd.com"]
start_urls = ['https://item.jd.com/5544068.html'] #score #0:全部评价 1:差评 2:中评 3:好评
comment_url = 'https://sclub.jd.com/comment/productPageComments.action?productId={productId}&score={score}&sortType=5&page={page}&pageSize=10&isShadowSku=0&rid=0&fold=1'
# haop_url = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv6955&productId=6946627&score=3&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1'
# zhongp_url = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv6955&productId=6946627&score=2&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1'
# chap_url = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv6955&productId=6946627&score=1&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1'
response = requests.get(start_urls[0])
soup = BeautifulSoup(response.content, 'lxml')
content = soup.find_all('div', class_='erji')
dic = {}
model = ''
for a in content:
a_label = a.find_all('a')
for href in a_label:
productId = re.compile('\d+').findall(href.get('href'))[0]
dic['https:' + href.get('href')] = [productId, href.get_text()]
# print('------->',dic)
def start_requests(self):
for k,v in self.dic.items():
productId = v[0]
global model
model = v[1]
for score in range(4):
page = 0
while page |