【数据分析day05】Scipy读/写.mat文件,wav,mp3 |
您所在的位置:网站首页 › scipy读取mat文件 › 【数据分析day05】Scipy读/写.mat文件,wav,mp3 |
【数据分析day05】Scipy读/写.mat文件,wav,mp3
|
Scipy文件输入/输出,wav,mp3
读写.mat 文件
写入 .savemat()
读取 .loadmat()
wav
读 wavfile.read()
拼接 np.vstack()
写 wavfile.write()
MP3
读: AudioSegment.from_mp3()
转化为wav: wavfile.write()
裁剪(就是按毫秒切片)
导出 export()
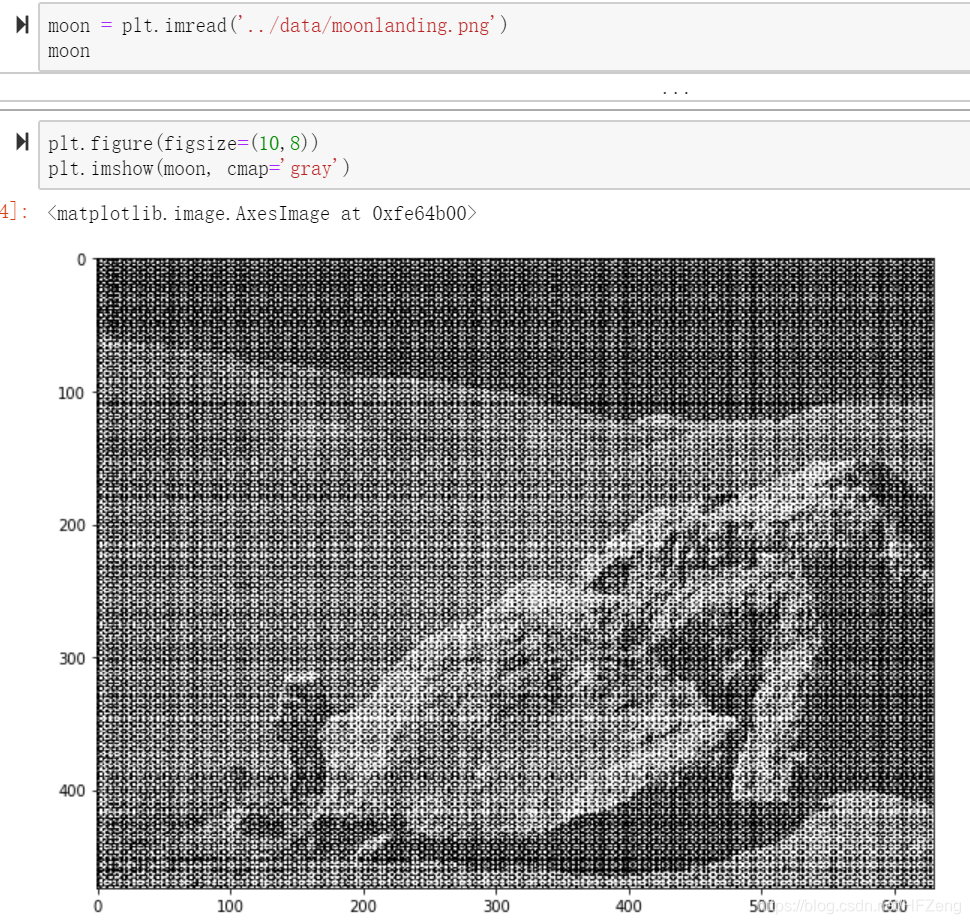
读取png文件命名为“moon”(df),降噪后处理成“moon_cleaned”(df),并将两个df数据存储到.mat文件中
mat :标准二进制文件
常规图片读取用"plt.imread"
mat文件读取用 scipy.io 库的 .loadmat() 和.savemat()
moon (df) 导入: import scipy.io as spio 读写.mat 文件 写入 .savemat()将上面两个df数据,存储到“moon_cleaned.mat”文件中,分布命名为{‘moon_cleaned’和’moon_origin’ import scipy.io as spio spio.savemat('moon_cleaned.mat', mdict={'moon_cleaned': moon_cleaned, 'moon_origin': moon}) 读取 .loadmat()读取上面的“moon_cleaned.mat”文件 data = spio.loadmat('./moon_cleaned.mat') data
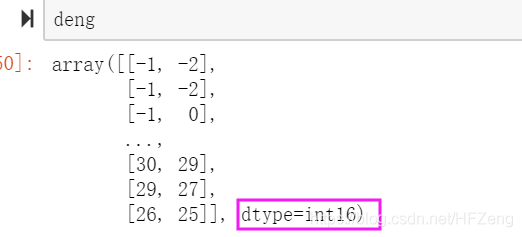
使用scipy处理wav文件 WAV为微软公司(Microsoft)开发的一种声音文件格式,音质好 单声道是一维矩阵,立体声(双声道)是二维 标准的采样频率为:11.025kHz(语音效果)、22.05kHz(音乐效果)、44.1kHz(高保真效果) 导包:from scipy.io import wavfile 读 wavfile.read() from scipy.io import wavfile # 返回值为元组,分别为:“采样频率: 和 ”数据“ _, deng = wavfile.read('../data/邓紫棋-喜欢你.wav')wav的音乐文件, 数据类型必须是int16,取值范围: -32768 ~ +32767
截取一半的音频只需要 len(deng)//2 (整除) 再读取另一首歌 _, lin = wavfile.read('../data/林俊杰-爱不会绝迹.wav') lin 拼接 np.vstack()将两首歌各自截取一半,再拼接成一首歌 # 拼接 mix_music = np.vstack((deng[:len(deng)// 2], lin[:len(lin)//2])) 写 wavfile.write() # 导出 wavfile.write('mix_music.wav', 44100, mix_music) MP3使用pydub+ ffmpeg处理mp3文件 需要安装pydub ffmpeg需要下载,并解压将3个文件放至Python安装目录中的bin目录下,然后还要配置环境变量 pydup中的AudioSegment可以处理mp3文件导包: from pydub import AudioSegment 读: AudioSegment.from_mp3() jing = AudioSegment.from_mp3('../data/难念的经.mp3') type(jing)返回一个AudioSegment对象
注意:这里不要直接打印它(因为数据特别长,可能会卡死) 查看一下类型 type(jing_data)
查看形状 jing_ndarray.shape
转换后 4M --> 40+M 返回的是秒
剪辑合并各一半的两首歌 mix = jing[: 269609 // 2] + love[: 234527 // 2] mix
|
 降噪后的moon_cleaned (df)
降噪后的moon_cleaned (df) 
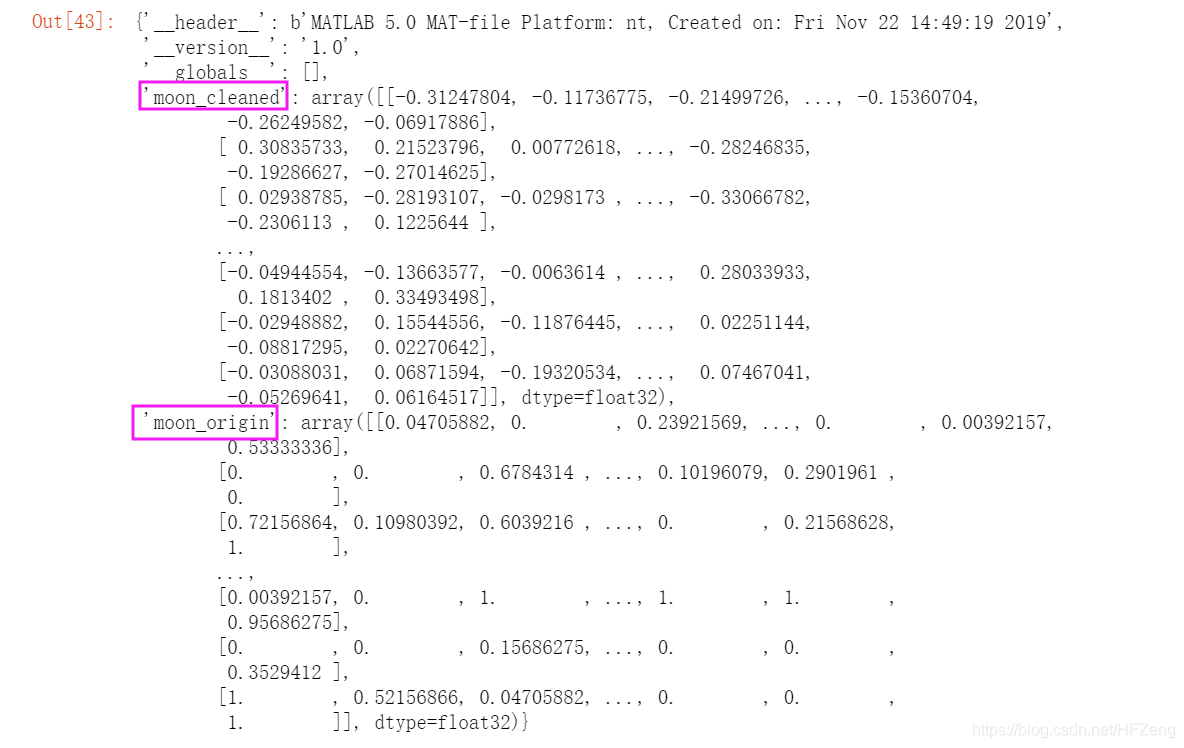 可分别取df,这里取‘moon_origin’为例:
可分别取df,这里取‘moon_origin’为例:
 查看矩阵形状
查看矩阵形状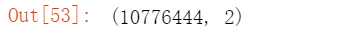 10776444 / 44100 剩下的是秒数
10776444 / 44100 剩下的是秒数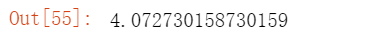 4.072分钟 相当于 4分42秒
4.072分钟 相当于 4分42秒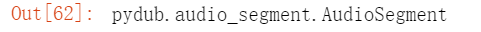 可直接运行播放音频(需要等一阵子)
可直接运行播放音频(需要等一阵子) 获取原始数据
获取原始数据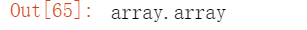 转换成 ndarray
转换成 ndarray 查看类型
查看类型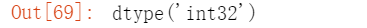

 导入另一首歌 并 查看时长
导入另一首歌 并 查看时长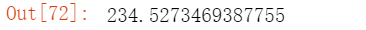 切片的时候切的是音乐的时长, 单位是毫秒. 先算出两首歌的时长毫秒数
切片的时候切的是音乐的时长, 单位是毫秒. 先算出两首歌的时长毫秒数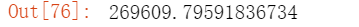
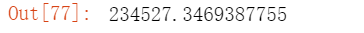

【本文地址】