SAS数据导入input要点 |
您所在的位置:网站首页 › sas中@@是什么意思 › SAS数据导入input要点 |
SAS数据导入input要点
|
1、input的输入格式
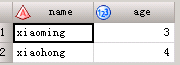
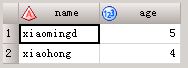
字符型变量默认8个字符,若使用input语句时,原文件字符长度超过8个字符,如果不加以说明,此时input会将字符截断为8个字符,如下: 代码1: data a; input name $ age; cards; xiaomingd5 3 xiaohong 4 ; run;此时第一个变量xiaomingd5将被截断,生成的结果为: 若使用input格式输入时,在$加上字符的长度,此时在读取时,就会按照指定的长度读取数据,将上面代码改为: 代码2: data a; input name $9. age; cards; xiaomingd5 3 xiaohong 4 ; run;此时第一个变量xiaomingd5的长度将会改变为9个字符,生成的结果为: 你会注意到name是改变了,但是两次的age结果不一样,这是为什么? 因为input语句总是从第1列开始读取数据,因此第一个变量name $9. 从第一列读到第9列,无论其中是否有分隔符。age变量的起始点在第10列,sas开始从第10列读取age之,所以代码2中age的值是5。
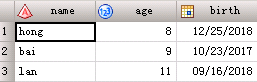
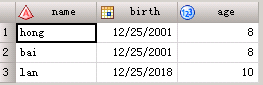
能否正确读取age值呢?可以的,使用冒号修饰符: 代码3: data a; input name :$9. age; cards; xiaomingd5 3 xiaohong 4 ; run;此时再运行程序,age值就是3。 【当一个变量的长度在input之前定义时,sas将一直读取直到遇到分隔符或者达到之前定义的长度为止】 代码4: data a; informat name $9.; input name $ age; cards; xiaomingd5 3 xiaohong 4 ; run;代码3和代码4的行为是一致的; 2、input中的指针 在读取外部数据时,跳到指定列使用@n,告诉sas在读取数据之前将指针移动到第n列;当你不知道数据开始位置,但是知道他总是在一个特定的字符后开始的,可以使用@‘character’指针,如:stu_name的数值总是出现在单词name后面,可以用下面的input语句 input @‘name’ stu_name $;@@从一行中读取多个观测:input语句以@@结尾,就像停车标志一样告诉sas:“停下来,留在原始数据的当前行”。sas将停留在那行数据,继续读取观测直到数据读取完毕或者遇到了没有@@符合input语句为止。 @@保持在本行: data c; input city $ state $ high low @@; cards; nome ak 55 44 miami fl 90 75 raleigh nc 88 68 ; run;+1代表跳过1列 为每个观测读取多行原始数据:告诉sas何时跳到下一行,需要在input中添加行指针,斜线(/)和井号(#n)。在input语句中插入一个斜线(/)指示跳到下一个原始数据行,#n代表为该观测进入原始数据的第n行。 data b; infile cards ; input city $ state $ /high low #3 record weight; cards; nome ak 55 44 88 29 miami fl 90 75 97 65 raleigh nc 88 68 105 50 ;斜线(/)告知sas在读取high和low前移动到数据下一行的第一列,#3告知sas在读取record和weight之前移动到数据第三行的第一列。 3、input语句中的冒号‘:’从外部导入数据,有时会需要给每个变量赋予输入格式,主要有2种办法: 法1:使用informat语句 data a; informat birth MMDDYY10.; input name $ age birth; datalines; hong 8 12/25/18 bai 9 10/23/17 lan 11 09/16/18 ; run;注:如果不指定输入格式,系统将不能识别birth里的数据格式,birth的运行结果将是数值型的缺失值; 法2:使用input中的冒号‘:’ data a; input name $ age birth:MMDDYY10.; datalines; hong 8 12/25/18 bai 9 10/23/17 lan 11 09/16/18 ; run;输出结果如下:
input语句中变量后跟数据格式时带冒号和不带冒号的区别: 带冒号指的是确定数据输入的格式,不带冒号如:birth MMDDYY10.指的是数据读取的位置,会导致读入数据不准确: data a; /* informat birth MMDDYY10.;*/ input name $ birth MMDDYY8. age; format birth MMDDYY10.; datalines; hong 12/25/18 8 bai 12/25/18 9 lan 12/25/18 10 ; run;结果如下:
带冒号的运行结果: data a; /* informat birth MMDDYY10.;*/ input name $ birth :MMDDYY8. age; format birth MMDDYY10.; datalines; hong 12/25/18 8 bai 12/25/18 9 lan 12/25/18 10 ; run;结果如下:
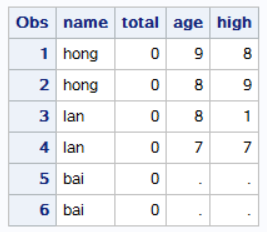
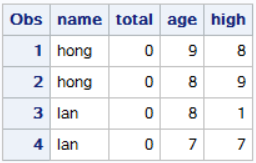
不用读取所有数据再做筛选保留哪些数据,可以只读需要的变量以确定是否保留当前的观测,用@(单尾@)结束input语句。该符合告知sas保持那行原始数据。在单尾@保留行数据时,你可以用IF语句来判断该变量,看他是否需要保留。如果是,则用第二个input语句为其余变量读取数据。如果没有单尾@,sas将自动为每一个input语句读取下一行原始数据。 input与if else的结合: data a; infile datalines; input name $ @; total+age; if name='hong' or name='lan' then input age high; cards; hong 9 8 hong 8 9 lan 8 1 lan 7 7 bai 3 4 bai 4 6 ; run;结果集:
结果集:
【对比单尾@和双尾@@】 @和@@都是行保持符,区别在于他们保持一行输入数据的时间长短不同,单尾@为后续的input语句保持一行数据,当sas回到data步的顶部开始生成下一条观测时,他将释放那行数据。 双尾@@即使在sas开始生成新观测时,也为后续的input语句保持那行数据。 、
|
【本文地址】
今日新闻 |
推荐新闻 |