TensorFlow入门教程(8)读取数据集之Dataset |
您所在的位置:网站首页 › sarcasm怎么读 › TensorFlow入门教程(8)读取数据集之Dataset |
TensorFlow入门教程(8)读取数据集之Dataset
|
# #作者:韦访 #博客:https://blog.csdn.net/rookie_wei #微信:1007895847 #添加微信的备注一下是CSDN的 #欢迎大家一起学习 # 1、概述前两讲,我们讲了队列和TFRecord,不知道你们有没有注意到,程序运行时,有如下警告(我现在用的TensorFlow版本是1.15.1,老的版本没有这个警告), WARNING:tensorflow:From demo4.py:54: string_input_producer (from tensorflow.python.training.input) is deprecated and will be removed in a future version. Instructions for updating: Queue-based input pipelines have been replaced by `tf.data`. Use `tf.data.Dataset.from_tensor_slices(string_tensor).shuffle(tf.shape(input_tensor, out_type=tf.int64)[0]).repeat(num_epochs)`. If `shuffle=False`, omit the `.shuffle(...)`. 这说明我们以前使用队列的方式已经淘汰了,它推荐我们使用tf.data.Dataset的接口,tf.data.Dataset是比较高级的接口,使用这个接口使得处理数据集更简单,这一讲,我们就来看这个tf.data.Dataset接口怎么使用,这也是TensorFlow现在主推的数据集处理方式,必须要重点掌握。 环境配置: 操作系统:Win10 64位 显卡:GTX 1080ti Python:Python3.7 TensorFlow:1.15.0 2、Dataset对象 tf.data.Dataset接口是通过创建Dataset对象来生成Dataset数据集的,有了Dataset对象,就可以直接做洗牌(shuffle)、设置batch size、复制数据(repeat)等操作。有三种方法可以创建Dataset对象,分别是tf.data.Dataset.from_tensors、tf.data.Dataset.from_tensor_slices和tf.data.Dataset.from_generator。 我们这里主要学习tf.data.Dataset.from_tensor_slices的用法。 3、tf.data.Dataset.from_tensor_slices来看一个简单的demo就明白怎么使用tf.data.Dataset.from_tensor_slices了,代码如下, import tensorflow.compat.v1 as tf import numpy as np def get_data(dataset): # 创建迭代器 iterator = dataset.make_one_shot_iterator() # 从迭代器中获取一个数据 return iterator.get_next() def main(argv=None): # 创建Dataset对象 dataset = tf.data.Dataset.from_tensor_slices(np.arange(0, 10)) data = get_data(dataset) # 创建会话 with tf.Session() as sess: try: while True: # 打印获取的data数据 print(sess.run(data)) except: print('Done..') if __name__ == '__main__': tf.app.run()首先,通过tf.data.Dataset.from_tensor_slices接口创建一个Dataset对象,然后,通过这个对象创建一个迭代器,再从迭代器中拿到数据,最后在会话中得到这些数据。运行结果如下,
我们上面说过,Dataset可以直接对数据进行处理操作,那么,现在就基于上面的demo来看看怎么进行数据处理。 设置batch size设置batch size很简单,只要在创建Dataset对象以后,直接设置即可,代码如下, import tensorflow.compat.v1 as tf import numpy as np def get_data(dataset): # 创建迭代器 iterator = dataset.make_one_shot_iterator() # 从迭代器中获取一个数据 return iterator.get_next() def main(argv=None): # 创建Dataset对象 dataset = tf.data.Dataset.from_tensor_slices(np.arange(0, 10)) # 设置batch size dataset = dataset.batch(2) data = get_data(dataset) # 创建会话 with tf.Session() as sess: try: while True: # 打印获取的data数据 print(sess.run(data)) except: print('Done..') if __name__ == '__main__': tf.app.run()运行结果,
接着来看对数据进行洗牌的操作,跟上面设置batch size的方式一样,所以这里就不放全部代码了,只放关键代码即可,代码如下, # 洗牌操作,其中参数5是指定buffer_size dataset = dataset.shuffle(5)运行结果,
那么这个buffer_size怎么理解呢?我们画个图来理解,
如上图所示,Dataset会根据buffer_size的值创建一个大小为buffer_size的缓冲区Buffer,然后,将所有数据All Data的前buffer_size个数据填充Buffer,
接着,从Buffer随机取一个数据输出,比如上图中就随机取出了item 3作为输出,那么,原来item 3的位置就会空出来,
此时,就会顺序的从All Data里选择一条数据填充到这个空出来的Buffer位置,然后再随机从Buffer中抽取一个数据输出,如此循环,就可以对数据进行洗牌操作。buffer_size越大,数据的顺序就会被洗得越乱。如果设置buffer_size为1,就会发现,数据的顺序没被洗乱。 复制数据repeat接着来看复制数据操作,代码如下, # 复制操作,其中参数2是复制次数 dataset = dataset.repeat(2)运行结果,
Map操作主要是对数据集的每条数据进行指定的操作,比如,让数据集的每个数据乘以2,代码如下, # Map操作,可以对每个数据进行指定操作 dataset = dataset.map(lambda x : x * 2)运行结果,
Filter操作可以对数据进行过滤,比如,过滤掉数据中小于5的数,代码如下, # filter操作,对数据进行过滤操作dataset = dataset.filter(lambda x : x > 4) 运行结果,
老规矩,还是以MNIST数据集为例,跟上一讲一样,将数据保存成图片的形式,如下图所示,
数据集准备好了,接下来就使用Dataset来读取,首先,导入所有图片和其对应的标签,代码如下, # 导入所有图片和其对应的标签 def load_files(dir): print("Loading files...") fileslist = [] labelslist = [] for path, dirs, files in os.walk(dir): for file in files: fileslist.append(os.path.join(path, file)) labelslist.append(int(os.path.basename(path))) return shuffle(np.asarray(fileslist), np.asarray(labelslist)) # return np.asarray(fileslist), np.asarray(labelslist)接着,创建Dataset对象,代码如下, # 创建Dataset对象 def create_dataset(fileslist, labelslist, batchsize): dataset = tf.data.Dataset.from_tensor_slices((fileslist, labelslist)) # 解析图片数据 dataset = dataset.map(read_image) # 洗牌操作,其中参数是指定buffer_size dataset = dataset.shuffle(60) # 复制操作 dataset = dataset.repeat(60) # 设置batch size dataset = dataset.batch(batchsize) return dataset而read_image函数就是读取图片数据的操作,代码如下, # 读取图片数据并归一化 def read_image(filename, label): image = tf.read_file(filename) image = tf.image.decode_image(image) image = tf.reshape(image, [28 * 28]) image = tf.cast(image, tf.float32) image /= 255 label = tf.cast(label, tf.int32) return image, label接着,就要创建迭代器了,代码如下, def get_data(dataset): # 创建迭代器 iterator = dataset.make_one_shot_iterator() # 从迭代器中获取一个数据 return iterator.get_next()这些都准备好以后,就可以在会话中运行了,我们顺便将标签打印出来看看对不对,代码如下, def main(argv=None): fileslist, labelslist = load_files("MNIST_DATASET/all_images") # 创建Dataset对象 dataset = create_dataset(fileslist, labelslist, 50) data = get_data(dataset) # 创建会话 with tf.Session() as sess: try: while True: images, labels = sess.run(data) print(labels) except: print('Done..')运行结果如下,
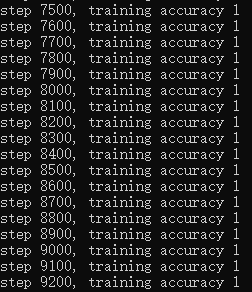
和上一讲一样,我们获取到数据以后,将其送到CNN网络进行模型训练,也是比较简单的,直接上代码,核心代码如下, def main(argv=None): fileslist, labelslist = load_files("MNIST_DATASET/all_images") print(labelslist) # 创建Dataset对象 dataset = create_dataset(fileslist, labelslist, 50) data = get_data(dataset) # 创建x占位符,用于临时存放MNIST图片的数据, # [None, 784]中的None表示不限长度,而784则是一张图片的大小(28×28=784) x = tf.placeholder(tf.float32, [None, 784]) # label 存的是实际图像的标签,即对应于每张输入图片实际的值 label = tf.placeholder(tf.float32, [None, 10]) # 将图片从长度为784的向量重新还原为28×28的矩阵图片, # 因为MNIST是黑白图片,所以深度为1, # 第一个参数为-1,表示一维的长度不限定,这样就可以灵活设置每个batch的训练的个数了 x_image = tf.reshape(x, [-1, 28, 28, 1]) # 搭建神经网络结构 acc, op, keep_prob, loss = net(x_image, label) # 创建会话 with tf.Session() as sess: sess.run(tf.global_variables_initializer()) try: for i in range(20000): images, labels = sess.run(data) # print(labels) # 将label转成one-hot形式 ls = [] for l in labels: la = [i == int(l) for i in range(0, 10)] ls.append(la) ls = np.asarray(ls).astype(np.float) # print('images', images) # print('labels', ls) # 将数据传入神经网络,开始训练 sess.run(op, feed_dict={x: images, label: ls, keep_prob: 0.5}) if i % 100 == 0: train_accuracy = sess.run(acc, feed_dict={x: images, label: ls, keep_prob: 1.0}) print("step %d, training accuracy %g" % (i, train_accuracy)) except: print('Done..')运行结果,
完整代码链接如下, https://mianbaoduo.com/o/bread/YpeTmZ0=
下一讲,我们来结合前面所学的知识,来看看怎么识别比MNIST更复杂一点的CIFAR-10数据集。 |






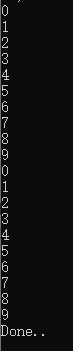





【本文地址】
今日新闻 |
推荐新闻 |