python利用read |
您所在的位置:网站首页 › r读取数据的数据最后一行为什么有NA › python利用read |
python利用read
|
目录
1. 案例1.1 案例1 read_table1.2 案例2 read_csv
2. pandas.read_table() 详解2.1 sep介绍参数列表:适用于read_csv()和read_table()
3. read_csv()读取dat数据、写入dat3.1 案例3.2 error_bad_lines参数
4. with + open()方法4.2 with + open() 获取最后一行
5. 特殊案例参考链接
1. 案例
1.1 案例1 read_table
df = pd.read_table(r'E:\data\2012_08_10.dat', sep=',', skiprows=1)
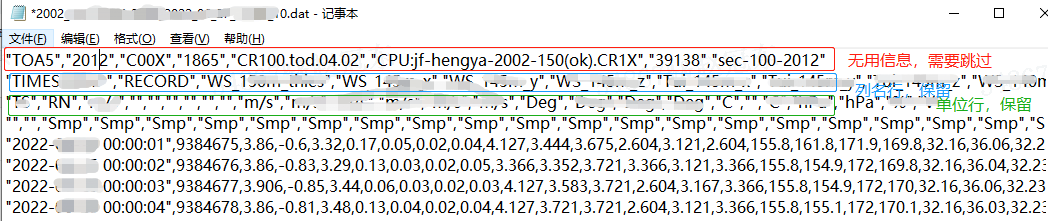
首先,用记事本打开 dat 信息,查看内容。发现第一行为无用信息,跳过第一行, skiprows=1,第二行和第三行看似杂乱,值得数量却和下面的行是一致的,需要保留。内容都是由 逗号 隔开,所以 sep=‘,’ 。
这里 sep 用的 \t+ data = pd.read_table(f, encoding='gbk', parse_dates={'time': ['年月日', '时间戳']}, error_bad_lines=False, sep='\t+',skiprows=10)filepath_or_buffer---->CSV文件的路径或URL地址。 sep---->CSV文件中字段分隔符,默认为逗号。 delimiter---->CSV文件中字段分隔符,默认为None。 header---->指定哪一行作为列名,默认为0,即第一行。 names---->自定义列名,如果header=None,则可以使用该参数。 index_col---->用作行索引的列编号或列名。 usecols---->读取指定的列,可以是列名或列编号。 dtype---->指定每列的数据类型,可以是字典或者函数。 na_values---->用于替换缺失值的值。 skiprows---->跳过指定的行数。 skipfooter---->跳过文件末尾的指定行数。 nrows---->读取指定的行数。 parse_dates---->指定哪些列需要转换为日期类型。 infer_datetime_format---->尝试解析日期时间格式(提高效率)。 dayfirst---->将日期解析为“日-月-年”而不是“月-日-年”的格式。 encoding---->CSV文件的编码方式,默认为None,使用系统默认编码。 squeeze---->如果文件只包含一列,则返回Series对象而不是DataFrame对象。 thousands---->千位分隔符。 decimal---->小数点分隔符。 参考链接[1] panda.read_table 2022.6 |

【本文地址】
今日新闻 |
推荐新闻 |