【精选】《金融数据分析导论:基于R语言》习题答案(第一章) |
您所在的位置:网站首页 › r语言第四章答案 › 【精选】《金融数据分析导论:基于R语言》习题答案(第一章) |
【精选】《金融数据分析导论:基于R语言》习题答案(第一章)
|
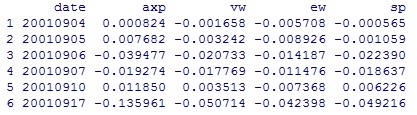
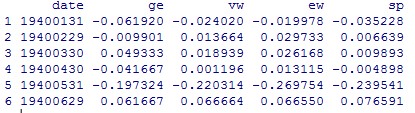
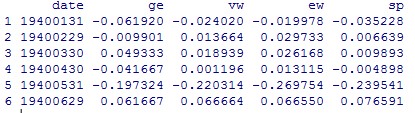
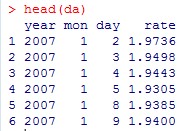
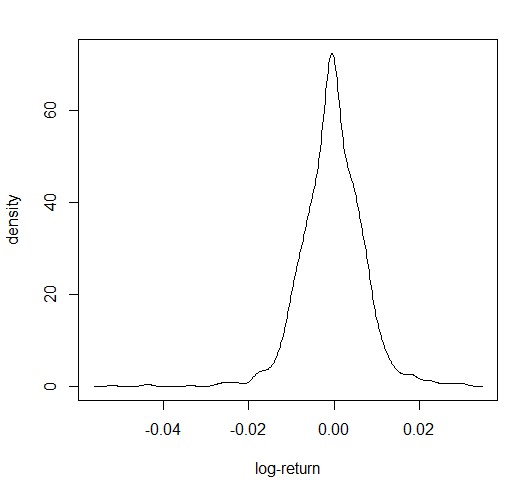
《金融数据分析导论:基于R语言》是芝加哥大学的教授Ruey S.Tsay所著,李洪成、尚秀芬、郝瑞丽翻译,机械工业出版社出版,是一本学习R语言和金融数据分析的很好的参考书籍。 ** 注:这些答案都是本人自己做出的结果,可能有错,仅供参考,发现有错的地方欢迎大家指出。 ** ** ** ** 第一章 ** 1.首先,将数据包放在当前工作目录下 library(fBasics) da = read.table("d-axp3dx-0111.txt",header=T) % 读出数据 head(da) % 显示数据的前 6 行,可以观察数据格式 mmm = da[,2:5] % 取出简单收益率的数据,即把日期去掉 basicStats(mmm) 对 mmm 中的数据做基础分析,就可得到各列简单收益率序列的样本均值 (Mean) 、标准差 (Stdev) 、偏度 (Skewness) 、超额峰度 (Kurtosis) 、最大值 (Maximum) 、最小值 (Minimum) rs = log(mmm+1) % 根据简单收益率求出对数收益率,公式为 r=In(R+1) basicStats(rs) % 基础分析求出一系列统计值 ss = rs[,1]% 取出 AXP 股票的对数收益率 t.test(ss) p 值大于 0.05 ,接受原假设,即 AXP 对数收益率的均值为 0 2.首先,将数据包放在当前工作目录下 library(fBasics) da = read.table("m-ge3dx-4011.txt",header=T) % 读出数据 head(da) % 显示数据的前 6 行,可以观察数据格式 mmm = da[,2:5] % 取出简单收益率的数据,即把日期去掉 basicStats(mmm) 提示错误如下: 经检查发现在数据的第 58 行(不包括标题) 19441031 的 sp 数据为 ”.” (非数值数据),因此系统报错。通过上网查阅资料,只查到如何删除含有 ”NA” 的行数据: na.omit(mmm) 或 mmm[complete.cases(mmm), ] [1] ,所以手工删除第 58 行: mmm = mmm[-58,]%x = x[-m,] 表示删除 x 矩阵中的第 m 行 然而删除了还是报同样的错误,于是我手工去 txt 文件里删除了第 58 行,就 ok 了,不知道程序怎么改才可以 = = 然后继续 对 mmm 中的数据做基础分析,就可得到各列简单收益率序列的样本均值 (Mean) 、标准差 (Stdev) 、偏度 (Skewness) 、超额峰度 (Kurtosis) 、最大值 (Maximum) 、最小值 (Minimum) rs = log(mmm+1) % 根据简单收益率求出对数收益率,公式为 r=In(R+1) basicStats(rs) % 基础分析求出一系列统计值 ss = rs[,1]% 取出 AXP 股票的对数收益率 t.test(ss) p 值小于 0.05 ,拒绝原假设,即 AXP 对数收益率的均值不为 0 3.首先,将数据包放在当前工作目录下 library(fBasics) da = read.table("m-ge3dx-4011.txt",header=T) % 读出数据 head(da) % 显示数据的前 6 行,可以观察数据格式 mmm = da[,5] % 取出 S&P 月收益率的数据 t.test(mmm) % 做 t 检验 因为 p 值为 2.436e-051.96 ,故拒绝原假设,即 S&P 综合指数的月股票收益率的峰度不为 3. 4.首先,将数据包放在当前工作目录下 library(fBasics) da = read.table("d-axp3dx-0111.txt",header=T) % 读出数据 head(da) % 显示数据的前 6 行,可以观察数据格式 mmm = da[,2] % 取出第 2 列 axp 的日简单收益率的数据 rs = log(mmm+1) % 求出对数收益率 s3 = skewness(rs) T = length(rs) t3= s3/sqrt(6/T) t3 t3 的绝对值小于 1.96 ,故接受原假设,即 axp 日对数收益率的偏度度量等于 0. s4 = kurtosis(rs) % 计算出超额峰度 t4 = s4/sqrt(24/T) t4 t4>1.96 ,故拒绝原假设,即 axp 日对数收益率的月股票收益率的超额峰度不为 0. 5.首先,将数据包放在当前工作目录下 library(fBasics) da = read.table("d-fx-ukus-0711.txt",header=T) % 读出英镑对美元汇率数据 head(da) % 显示数据的前 6 行,可以观察数据格式 发现最后一列是英镑对美元的汇率,取出最后一列数 mmm = da[,4] 将其转换为美元兑英镑的汇率 mmm = 1/mmm 根据每天的汇率值求出每天的日对数收益率,rt = In(pt/p(t-1)) ,rt 是第 t 期的日对数收益率,pt 是第 t 期的汇率值,设第 1 期r1 = In(pt/p(t-1)) = In1 = 0 ,循环计算从第 2 期到第 length(mmm) 期的日对数收益率。 r1 = 1:length(mmm) % 定义一个数组表示日对数收益率 r1[1] = 0 % 设定第 1 天的日对数收益率为 0 for (i in 2:length(r1)) { r1[i]=log(mmm[i]/mmm[i-1]) } r1 即为美元对英镑的汇率从 20070102-20111130 的日对数收益率。 同样的办法求出美元对日元的汇率从 20070102-20111130 的日对数收益率。 da = read.table("d-fx-usjp-0711.txt",header=T) head(da) r2= 1:length(mmm) r2[1] = 0 for (i in 2:length(r2)) { r2[i]=log(mmm[i]/mmm[i-1]) } r2 即为美元对日元的汇率从 20070102-20111130 的日对数收益率。 对 r1 和 r2 分别作基础分析,即可得到它们的样本均值 (Mean) 、标准差 (Stdev) 、偏度 (Skewness) 、超额峰度 (Kurtosis) 、最大值 (Maximum) 和最小值 (Minimum) 。 对于数据集 r2 ,求其密度分布的公式是 d = density(r2) ,画图函数为 plot(d$x, d$y, xlab=’log- return’, ylab=’density’, type=’l’)( 这两个公式见书中第 35 页的代码 ) d = density(r2) plot(d$x,d$y,xlab='log-return',ylab='density',type='l') 得到密度图如下: 假设检验( t 检验): t.test(r2) p 值大于 0.05 ,接受原假设,即美元 / 日元汇率的日对数收益率的均值为 0. [1] 人大经济论坛 http://bbs.pinggu.org/thread-2331183-1-1.html 吐槽: R 的矩阵定义好复杂啊
|



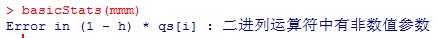












【本文地址】
今日新闻 |
推荐新闻 |