基于R语言 meta/metafor 包进行荟萃分析(一) |
您所在的位置:网站首页 › r语言标准误差代码 › 基于R语言 meta/metafor 包进行荟萃分析(一) |
基于R语言 meta/metafor 包进行荟萃分析(一)
|
目录 目录 1.引言 2.安装,数据的读取和保存 不讲。这个有别的大佬讲了,没有创新点。 3.标准方法 3.1 固定效应模型与随机效应模型 3.1.1 连续型结果的数据测量 3.1.2 固定效应模型 3.1.3 随机效应模型 3.1.4 异质性检验 3.1.5 亚组分析 3.1.6 其他结果的meta分析 3.1.7 总结 3.2 二元结果的meta分析 3.3 异质性与meta回归 4.进阶操作(将在后续部分讲,敬请期待) 4.1 小小的,也很可爱 4.2 我的数据少东西了 4.3 多元meta 4.4 网络meta分析 4.5 让我看看你的诊断准不准? 5.总结和尾声
恕小菜鸟直言,长文章不放目录,纯纯耍流氓。 1.引言本文章仅供自己学习参考,如有不当之处,请各位大佬多多指正。你说这又要当医学生,又要写代码的,真的很不容易;而且还没有人带,那就更头大了,发出来主要也就是想和志同道合的小伙伴们一起讨论。 参考数据知识来自于:metafor包列出的参考文献《meta with R》以及《R语言实战 第二版》,后者在我看来是最好的R入门书。当然我知道大佬可能随便找点参考视频,meta分析就已经拿捏住了。那么请略过此贴吧。 本书在开头就已经介绍了连续型数据的参考绘图方法,我用自己的数据展示了一下函数的写法,因为原文中的一些参数已经不能直接那么写了。因为后面这个包将主要介绍metagen功能下的数据处理模式(原书中参考的是哮喘的一组数据,我则是使用了一组不同椎弓根螺钉置钉方法术中出血量的数据)。 本人R版本4.2.1,写下此贴的时候4.2.2的大部分更新包都已经上线。后面的更新可能会导致包内的功能差异,表达一下大意,还是得自己多多摸索。 m # 3. Calculate the variance > round(1/sum(weight), 4) [1] 1.4126 #metacont#### > mc1 round(c(mc1$TE.fixed, mc1$seTE.fixedˆ2), 4) [1] -15.5140 1.4126 ##画图 > forest(mc1, comb.random=FALSE, xlab= + "Difference in mean response (intervention - control) + units: maximum % fall in FEV1", + xlim=c(-50,10), xlab.pos=-20, smlab.pos=-20) > # 应用metafor包-metagen函数,需要算出TE,seTE并且标注出来 > mc1.gen # 1. Calculate standardised mean difference,运用R基础包计算 > # variance and weights > N SMD varSMD weight # 2. Calculate the inverse variance estimator > round(weighted.mean(SMD, weight), 4) [1] -0.3915 > # 3. Calculate the variance > round(1/sum(weight), 4) [1] 0.0049 > mc2 round(c(mc2$TE.fixed, mc2$seTE.fixedˆ2), 4) [1] -0.3915 0.0049模型中得到的TE这个东西,就叫做合并效应量,se这一行是它的标准误。 展示模型得到得到结果,使用print(summary(mc2), digits=2) 这一行命令。 3.1.3 随机效应模型很多研究合并时发现异质性很大。这是怎么回事呢?此时你肯定不能假定所有研究人群都来自某一同质的总体了。换言之,研究间存在着差异,也就是合并效应量的计算得加一个额外的项目u来讨论这玩意儿。进行模型计算时我们假设u也服从一个均值为0,标准差为τ的正态分布;并且随机效应模型的核心假设其实在于,u这个东西和研究k并无内在联系,两个分布各玩各的。
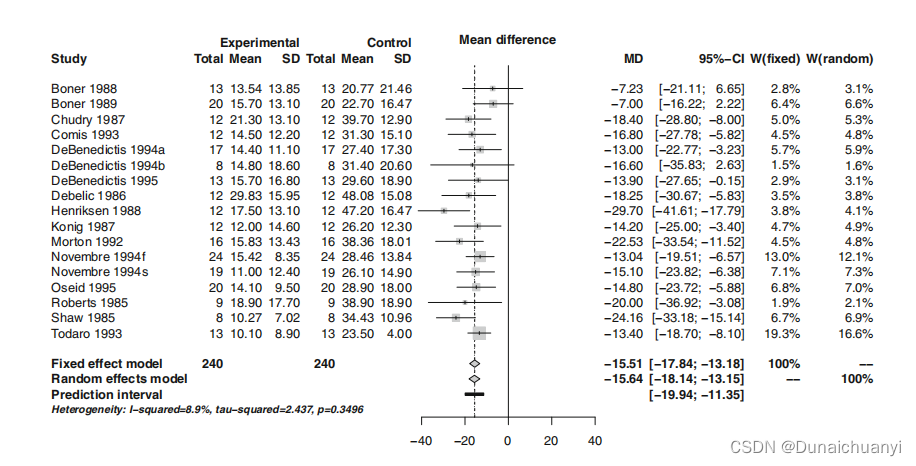
这就是所谓的互换性假设。如果我们接受这一假设,那么和固定效应模型相比,计算总体效应估计将更加关注来自较小研究的效应估计。上面说的这种差异的讨论,正是两种模型选择的核心问题。许多作者认为,由于小型研究更容易受到偏见的影响,固定效应估计(几乎)总是可以使用的;我们也常常看到,很多作者做出来异质性不大,还是会用随机效应模型验证一下自己的结果——所以不需要限制那么死板,言之有科学道理,他就是好的meta分析,是吧。 那么你需要提防的问题主要应该包括1 随机效应模型更加关注小样本的研究,2 随机效应模型得到的置信区间可能更宽。 ①估算研究间变异 DerSimonian–Laird estimator 估计方法是最流行的、也是默认方法。②Hartung-Knapp调整 Hartung和Knapp在随机效应模型中引入了一种新的基于精细方差估计量的元分析方法,有研究人员特地在内科学年鉴上吹捧啊,说这个方法比DerSimonian–Laird的还好。到底牛逼在哪里我其实也不懂,不过我能做一做试试看。 #直接metacont函数 > mc2.hk mc2.hk print(summary(mc2.hk), digits=2) Number of studies combined: k=17 95%-CI t p-value Random effects model -0.59 [-0.95; -0.22] -3.4 0.0036 Quantifying heterogeneity: tauˆ2 = 0.2309; H = 1.91 [1.5; 2.43]; Iˆ2 = 72.5% [55.4%; 83.1%] Test of heterogeneity: Q d.f. p-value 58.27 16 < 0.0001 Details on meta-analytical method: - Inverse variance method - DerSimonian-Laird estimator for tauˆ2 - Hartung-Knapp adjustment for random effects model这个方法算下来的特点(据书中所言)就是置信区间又宽了。 ③预测区间 Prediction Intervals 只是把别人的结果合并,似乎有点不能满足各位统计学大师了。于是他们搞了套公式,计算以后的研究结果可能出现的范围。除了总结历史,我们还能展望未来,怎么样,nb吧。当然了,这个区间的含义就只是一个区间,不是针对点估计值θ的;从中得到的结论是,我们预测今后的平均治疗效果至少也得>11%。 > print(summary(mc1, prediction=TRUE), digits=2) Number of studies combined: k=17 MD 95%-CI z p-value Fixed effect model -15.51 [-17.84; -13.18] -13.05 < 0.0001 Random effects model -15.64 [-18.14; -13.15] -12.30 < 0.0001 Prediction interval [-19.94; -11.35] *** Output truncated *** #简简单单画个图 forest(mc1, prediction=TRUE, col.predict="black")
metacont又来算异质性了。具体的细节可见后文部分。 计算异质性I方需要的公式包括
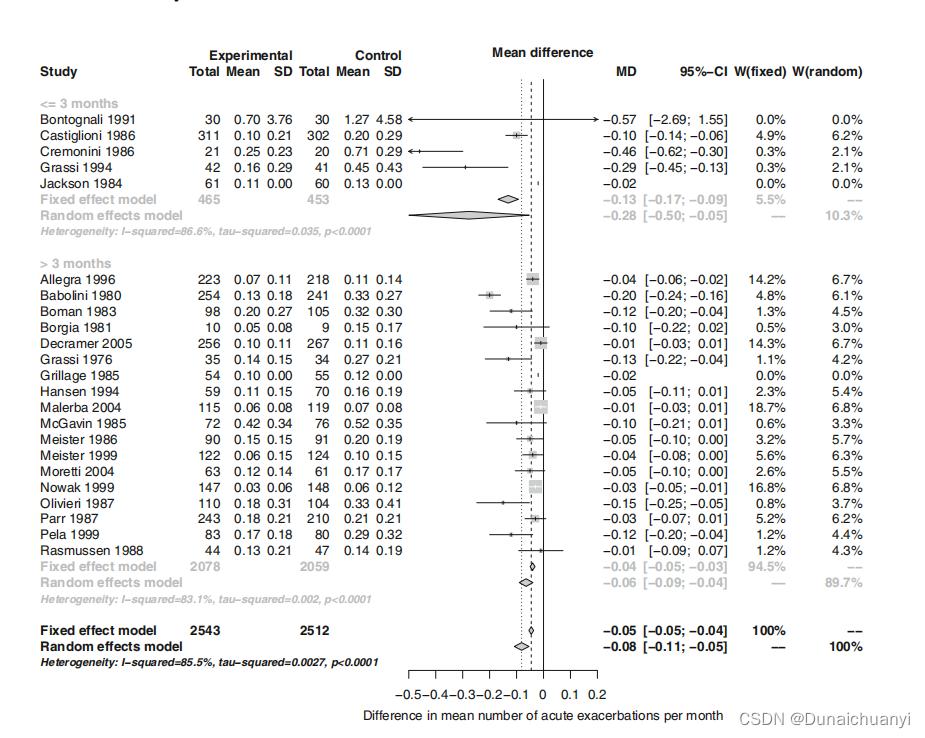
Q<K-1,不存在异质性,否则套公式计算。 Q越大(和K-1比),算得H方也就越大,异质性就越会接近100%;反之Q小小的,I方也小(起码得小于50%),那么在结论中你可以直接表述为 “有强有力的证据表明奈多克米尔钠改善运动后支气管收缩”;反之异质性若很大,那只有数据非常好(P data3 # 2. As usual, to view an object, type its name: > data3 #这里就不读取数据了,太长 > mc3 mc3$studlab[mc3$w.fixed==0] #通过权重=0筛选出报错的研究 [1] "Jackson 1984" "Grillage 1985" > print(summary(mc3), digits=2) Number of studies combined: k=21 MD 95%-CI z p-value Fixed effect model -0.05 [-0.05; -0.04] -10.06 < 0.0001 Random effects model -0.08 [-0.11; -0.05] -5.82 < 0.0001 Quantifying heterogeneity: tauˆ2 = 0.0027; H = 2.63 [2.19; 3.15]; Iˆ2 = 85.5% [79.1%; 89.9%] #异质性有点大 # 然后亚组分析 > mc3s mc3s forest(mc3s, xlim=c(-0.5, 0.2), + xlab="Difference in mean number of acute exacerbations per month") 给出结果时命令为:print(summary(mc3s), digits=2) 随机/固定效应模型的两种结果都会显示。你看,不需要太花里胡哨的命令,图就已经很高大上。
在这一部分将开始大量使用metagen方法。但是有没有可以替换的功能函数?肯定有的,原作中只给出了函数的名字,没有提用法,列出来看看吧。 •相关性meta分析的meta函数=metacor, •发病率比meta分析的meta函数=metainc, •单一比例meta分析的meta函数=metaprop(这个后面会讲)。 ① 生存数据的meta 举个简单的例子,你想研究某一疾病从发病(基线)到最终死亡(终点事件)的关系,则这种类型的数据称为时间-事件数据或生存数据。事件发生的时间是一个连续的量,然而,与迄今为止使用的具有连续型数据的示例相反,事件发生的时间通常不能被所有参与者观察到,因为研究中的最大随访时间是有限的。在随访期间没有发生终点事件的患者称为 censored observations,或者叫另一个我很喜欢的说法:“截尾”。截尾是生存数据的一个显著特征。 生存数据的另一个重要方面(本书没有涉及)是竞争事件,例如,研究心血管疾病与死亡时,有些参与者确实因为冠心病死亡,但也有参与者被泥头车送去异世界了;那么他原本会因为冠心病而死亡的时间就无法被观察到。在这种情况下,只能观察到由于心血管或非心血管原因而死亡的时间。在生存分析中,风险函数,即描述给定生存到特定时间点的瞬时死亡风险的函数,起着核心作用。为了比较两组不同暴露人群的结局差异,通常使用风险比(hazard ratio,HR),即风险函数的比率。因此,风险比的对数及其标准误差是meta分析中使用的基本量。由于风险比和相应的标准误差并不总是在出版物中报告,存在几种方法来获得这些数量,例如从已发表的生存曲线中。通用逆方差法可以直接使用对数风险比logHR及其标准误差se。在下面的例子中,我们考虑最基本的情况,即固定效应和随机效应的meta分析,使用dersimonan - laird方法估计研究间方差2。 > # 1. Read in the data 用的是04号文件 > data4 # 2. Print data > data4 #看看数据 author year Ne Nc logHR selogHR 1 FCG on CLL 1996 53 52 -0.5920 0.3450 2 Leporrier 2001 341 597 -0.0791 0.0787 3 Rai 2000 195 200 -0.2370 0.1440 4 Robak 2000 133 117 0.1630 0.3120 ##开始使用高贵的metagen函数 > mg1 print(mg1, digits=2) ##看看结果 HR 95%-CI %W(fixed) %W(random) FCG on CLL 1996 0.55 [0.28; 1.09] 3.68 5.85 Leporrier 2001 0.92 [0.79; 1.08] 70.70 59.76 Rai 2000 0.79 [0.59; 1.05] 21.12 27.32 Robak 2000 1.18 [0.64; 2.17] 4.50 7.08 Number of studies combined: k=4 HR 95%-CI z p-value Fixed effect model 0.89 [0.78; 1.01] -1.82 0.0688 Random effects model 0.87 [0.74; 1.03] -1.58 0.1142② 交叉实验的meta分析 交叉试验是另一种比较治疗方法的流行设计。在交叉试验中,患者自己就是自己的对照。它的优势在于,从治疗比较中去除患者之间的差异,使患者数量减少,还能达到相同的统计功效。交叉试验的适用情况是慢性但稳定的疾病,即患者既不能治愈,也不会随着时间的推移(急剧)恶化。 在简单的交叉设计中,患者被随机分配到治疗序列AB或BA,即要么先接受治疗a,然后“交叉”到治疗B,反之亦然。通常,第一治疗期和第二治疗期被所谓的洗脱期分开,使得第一治疗期的治疗效果不转移到第二治疗期。原则上,两种治疗A和B的更长的序列是可能的,例如ABBA。注意,交叉试验的第一阶段等同于平行组研究设计。《医学统计学》(Statistics in Medicine)的一系列论文已经描述了交叉试验荟萃分析的统计方法以及平行组和交叉试验的结合。 对于具有连续结果的交叉试验的荟萃分析,可以使用通用逆方差法。在此例中,Curtin等报道了12项平行组试验和21项交叉试验的结果,以评估补充钾对降低收缩压和舒张压的影响(Meta-analysis combining parallel and cross-over clinical trials. I: Continuous outcomes - PubMed)。书中选取了交叉实验+舒张压的组合提取数据。标注了ab的是因为实验设计是双臂的,其他的可能本来就只有一组受试者,阶段1补钾,阶段2不补,就此完成试验。 在荟萃分析中我们其实没有使用相关性(corr)这一列,然而,通过使用交叉设计,这些值给出了精度增益的一些指示。所有相关性都在0以上,范围在0.29 ~ 0.88之间。 > # 1. Read in the data > data5 # 2. Print data > data5 author year N mean SE corr 1 Skrabal et al. 1981a 20 -4.5 2.1 0.49 2 Skrabal et al. 1981b 20 -0.5 1.7 0.54 3 MacGregor et al. 1982 23 -4.0 1.9 0.41 4 Khaw and Thom 1982 20 -2.4 1.1 0.83 5 Richards et al. 1984 12 -1.0 3.4 0.50 6 Smith et al. 1985 20 0.0 1.9 0.50 7 Kaplan et al. 1985 16 -5.8 1.6 0.65 8 Zoccali et al. 1985 23 -3.0 3.0 0.50 9 Matlou et al. 1986 36 -3.0 1.5 0.61 10 Barden et al. 1986 44 -1.5 1.4 0.44 11 Poulter and Sever 1986 19 2.0 2.2 0.36 12 Grobbee et al. 1987 40 -0.3 1.5 0.61 13 Krishna et al. 1989 10 -8.0 2.2 0.48 14 Mullen and O’Connor 1990a 24 3.0 2.0 0.50 15 Mullen and O’Connor 1990b 24 1.4 2.0 0.50 16 Patki et al. 1990 37 -13.1 0.7 0.53 17 Valdes et al. 1991 24 -3.0 2.0 0.50 18 Barden et al. 1991 39 -0.6 0.6 0.88 19 Overlack et al. 1991 12 3.0 2.0 0.50 20 Smith et al. 1992 22 -1.7 2.5 0.29 21 Fotherby and Potter 1992 18 -6.0 2.5 0.81 > mg2 print(summary(mg2), digits=2)# 展示结果 Number of studies combined: k=21 MD 95%-CI z p-value Fixed effect model -3.71 [-4.32; -3.11] -12.03 < 0.0001 Random effects model -2.38 [-4.76; -0.01] -1.96 0.0495 Quantifying heterogeneity: tauˆ2 = 27.03; H = 3.66 [3.14; 4.25]; Iˆ2 = 92.5% [89.9%; 94.5%] Test of heterogeneity: Q d.f. p-value 267.24 20 < 0.0001固定效应和随机效应模型均显示补充钾可显著降低舒张压。由于研究间异质性非常大,随机效应估计的置信区间比固定效应估计的置信区间要宽得多。因此,随机效应模型的p值要大得多。 ③ 调整后疗效的meta分析 通用反方差法的另一个应用是调整治疗效果的荟萃分析,例如,分析logistic回归模型调整后的对数优势比logOR或Cox回归模型调整下的对数风险比logHR。例2.15 Greenland和Longnecker[12]描述了一种结合来自汇总剂量-反应数据的趋势估计的方法。一项对16项病例对照研究的荟萃分析评估了饮酒对乳腺癌风险的影响,书中此为例进行了说明。这些研究的数据下面的代码所示。meta分析采用调整后的对数风险比(b列)及其标准误差(SE)。为了像作者[12]那样将结果报告为对数风险比,我们使用参数backtransfer =FALSE。结果和原文献中的一致,作者说的,错了别找我。 > # 1. Read in the data > data6 # 2. Print data > data6 ##有四列哦 author year b SE 1 Hiatt and Bawol 1984 0.004340 0.00247 2 Hiatt et al. 1988 0.010900 0.00410 3 Willett t al. 1987 0.028400 0.00564 4 Schatzkin et al. 1987 0.118000 0.04760 5 Harvey et al. 1987 0.012100 0.00429 6 Rosenberg et al. 1982 0.087000 0.02320 7 Webster et al. 1983 0.003110 0.00373 8 Paganini-Hill and Ross 1983 0.000000 0.00940 9 Byers and Funch 1982 0.005970 0.00658 10 Rohan and McMichael 1988 0.047900 0.02050 11 Talamini et al. 1984 0.038900 0.00768 12 O’Connell et al. 1987 0.203000 0.09460 13 Harris and Wynder 1988 -0.006730 0.00419 14 Le et al. 1984 0.011100 0.00481 15 La Vecchia et al. 1985 0.014800 0.00635 16 Begg et al. 1983 -0.000787 0.00867 > mg3 summary(mg3) Number of studies combined: k=16 logRR 95%-CI z p-value Fixed effect model 0.0082 [0.0056; 0.0108] 6.2409 < 0.0001 Random effects model 0.0131 [0.0062; 0.0199] 3.7298 0.0002 Quantifying heterogeneity: tauˆ2 = 0.0001; H = 2.24 [1.78; 2.82]; Iˆ2 = 80.1% [68.5%; 87.4%] Test of heterogeneity: Q d.f. p-value 75.31 15 < 0.0001 3.1.7 总结在此部分中,使用连续结果详细描述了通用逆方差方法及其在meta分析中的应用,还介绍了固定效应法和随机效应法。我们已经展示了如何分别将典型数据与metacont和metagen函数一起使用,以及如何print和绘制森林图。我们还讨论了估计研究间方差的各种方法,并将Hartung-Knapp平差描述为经典随机效应方法的替代方法。此外,我们还说明了byvar选项的使用,这使得亚组分析更加简单。关于亚组分析的更多细节见后续章节。最后,通用示范倒方差法已在不同情况下的使用(生存结果、交叉试验、调整后的治疗效果),作者说明了该方法的广泛适用性。 本来(一)是打算把3.2,3.3讲完的,但是篇幅太长的话肯定就没人看了,而且下面的内容也非常多,就留给后续章节去说明。 3.2 二元结果的meta分析 3.3 异质性与meta回归 4.进阶操作(将在后续部分讲,敬请期待) 4.1 小小的,也很可爱 4.2 我的数据少东西了 4.3 多元meta 4.4 网络meta分析 4.5 让我看看你的诊断准不准? 5.总结和尾声在综合R档案网络(CRAN)上可以找到许多关于R安装的有价值的信息和文件,对R有更进一步了解的兴趣的小伙伴你们还在等什么呢?好急,等不及要用各位大佬自己设计的R包了,哼!~ |
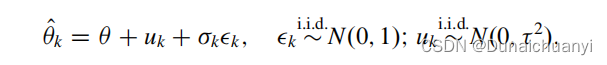
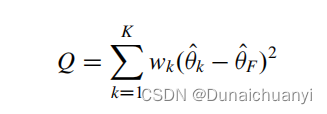
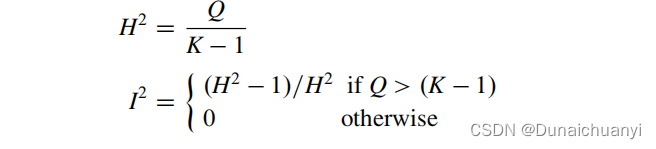
【本文地址】
今日新闻 |
推荐新闻 |