pydantic学习与使用 |
您所在的位置:网站首页 › r语言中prod是什么意思 › pydantic学习与使用 |
pydantic学习与使用
|
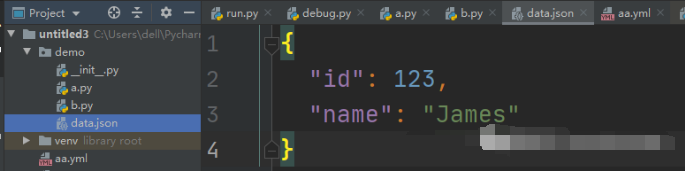
在 pydantic 中定义对象的主要方法是通过模型(模型继承 BaseModel )。 pydantic主要是一个解析库,而不是验证库。验证是达到目的的一种手段:建立一个符合所提供的类型和约束的模型。 换句话说,pydantic保证输出模型的类型和约束,而不是输入数据。 虽然验证不是pydantic的主要目的,但您可以使用此库进行自定义验证。 基本模型使用User这是一个模型,它有两个字段id,一个是整数,是必需的,name一个是字符串,不是必需的(它有一个默认值) from pydantic import BaseModel class User(BaseModel): id: int name = 'yo yo'类型name是从默认值(字符串)推断出来的,因此不需要类型注释(但是请注意当某些字段没有类型注释时有关字段顺序的警告) user = User(id='123')user这是一个实例User。对象的初始化将执行所有解析和验证,如果没有ValidationError引发,说明生成的模型实例是有效的。 user实例有 id 和 name 2个属性 user = User(id='123') print(user.id) # 123 print(user.name) # yo yo模型的字段可以作为用户对象的普通属性访问。字符串 ‘123’ 已根据字段类型转换为 int. name初始化用户时未设置,因此它具有默认值. 那么如何知道初始化的时候,需要哪些必填字段?可以通过 __fields_set__ 方法 print(user.__fields_set__) # {'id'}.dict() 可以将user对象的属性,转成字典格式输出,dict(user) 也是等价的 print(user.dict()) # {'id': 123, 'name': 'yo yo'} print(dict(user)) # {'id': 123, 'name': 'yo yo'}.json()可以将user对象的属性,转成json格式输出 print(user.json()) # {"id": 123, "name": "yo yo"} BaseModel 模型属性上面的例子只是展示了模型可以做什么的冰山一角。模型具有以下方法和属性: dict() 返回模型字段和值的字典;参看。导出模型 json() 返回一个 JSON 字符串表示dict();参看。导出模型 copy() 返回模型的副本(默认为浅拷贝);参看。导出模型 parseobj() 如果对象不是字典,则用于将任何对象加载到具有错误处理的模型中的实用程序;参看。辅助函数 parseraw() 用于加载多种格式字符串的实用程序;参看。辅助函数 parsefile() 喜欢parseraw()但是对于文件路径;参看。辅助函数 fromorm() 将数据从任意类加载到模型中;参看。ORM模式 schema() 返回将模型表示为 JSON Schema 的字典;参看。图式 schemajson() schema()返回;的 JSON 字符串表示形式 参看。图式 construct() 无需运行验证即可创建模型的类方法;参看。创建没有验证的模型 `__fields_set初始化模型实例时设置的字段名称集__fields模型字段的字典__config` 模型的配置类,cf。模型配置 递归模型可以使用模型本身作为注释中的类型来定义更复杂的分层数据结构。 from typing import List from pydantic import BaseModel class Foo(BaseModel): count: int size: float = None class Bar(BaseModel): apple = 'x' banana = 'y' class Spam(BaseModel): foo: Foo bars: List[Bar] m = Spam(foo={'count': 4}, bars=[{'apple': 'x1'}, {'apple': 'x2'}]) print(m) #> foo=Foo(count=4, size=None) bars=[Bar(apple='x1', banana='y'), #> Bar(apple='x2', banana='y')] print(m.dict()) """ { 'foo': {'count': 4, 'size': None}, 'bars': [ {'apple': 'x1', 'banana': 'y'}, {'apple': 'x2', 'banana': 'y'}, ], } """ 辅助函数Pydantic为解析数据的模型提供了三个classmethod辅助函数: parseobj:这与模型的方法非常相似_init,除了它需要一个字典而不是关键字参数。 如果传递的对象不是 dict,ValidationError则将引发。 parse_raw: 这需要一个str或bytes并将其解析为json,然后将结果传递给parse_obj. 通过适当地设置参数也支持解析泡菜数据。 content_type parse_file: 这需要一个文件路径,读取文件并将内容传递给parse_raw. 如果content_type省略,则从文件的扩展名推断。 parse_obj 的使用 from datetime import datetime from pydantic import BaseModel, ValidationError class User(BaseModel): id: int name = 'John Doe' signup_ts: datetime = None m = User.parse_obj({'id': 123, 'name': 'James'}) print(m) # id=123 signup_ts=None name='James'parse_raw 需要一个str或bytes并将其解析为json m = User.parse_raw('{"id": 123, "name": "James"}') print(m) # > id=123 signup_ts=None name='James'parse_file 可以读取一个文件的内容 data.json文件
.write_text()可以自己写内容到文件 from pathlib import Path path = Path('data1.json') path.write_text('{"id": 345, "name": "James 11"}') m = User.parse_file(path) print(m) # > id=345 name='James 11'下面是配套资料,对于做【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!
最后: 可以在公众号:程序员小濠 ! 免费领取一份216页软件测试工程师面试宝典文档资料。以及相对应的视频学习教程免费分享!,其中包括了有基础知识、Linux必备、Shell、互联网程序原理、Mysql数据库、抓包工具专题、接口测试工具、测试进阶-Python编程、Web自动化测试、APP自动化测试、接口自动化测试、测试高级持续集成、测试架构开发测试框架、性能测试、安全测试等。 如果我的博客对你有帮助、如果你喜欢我的博客内容,请 “点赞” “评论” “收藏” 一键三连哦!喜欢软件测试的小伙伴们,可以加入我们的测试技术交流扣扣群:779450660里面有各种软件测试资源和技术讨论) |

【本文地址】
今日新闻 |
推荐新闻 |