Statistical inference via data science 简介与数据可视化 |
您所在的位置:网站首页 › r语言cheatsheet › Statistical inference via data science 简介与数据可视化 |
Statistical inference via data science 简介与数据可视化
|
Statistical inference via data science第1章 introduction 这是一本入门书籍 这本书大致的学习路线 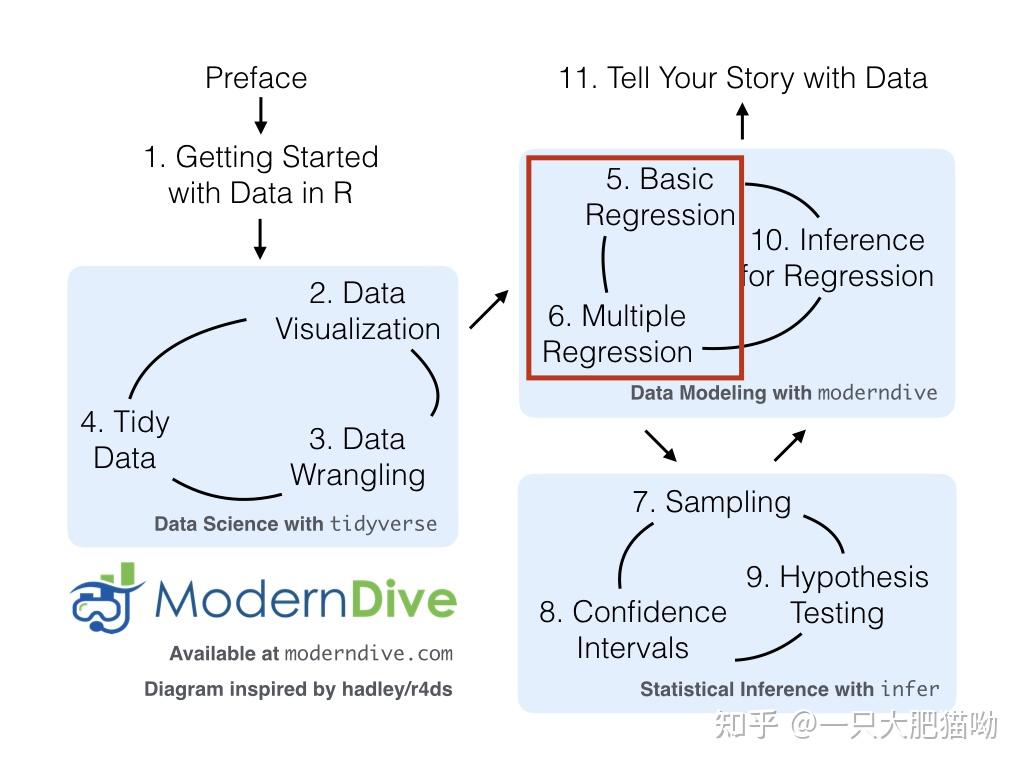 20221130014032 20221130014032y1s1 Rstudio-server 确实挺好用的,作为一门解释型语言,这样挺合适的,在网页进行交互很合适 Prompt: 提示 Command Prompt: 命令提示符 spread sheet: 电子数据表 也就是后面的数据框 data frame Attribute Spread Sheet: 属性编辑器 使用包之前记得先load 需要注意Note the uppercase V in View(). R is case-sensitive R是大小写敏感的 kable使用kable()可以生成Markdown格式的表格,比如kable(airlines) |carrier |name | |:-------|:---------------------------| |9E |Endeavor Air Inc. | |AA |American Airlines Inc. | |AS |Alaska Airlines Inc. | |B6 |JetBlue Airways | 几种查看数据框的方法1.View() 2.glimpse() 3.kable() 4.operator$ identification varibles 用于辨别区分,具有唯一性 比如名字 代号 measurement variables 表征量,可能会重复,高度,价格等非唯一的 stats统计 有时候一个变量可能无法唯一性的区分,就需要两个。最好在数据库的最左侧放上区分变量 重要的快捷键这部分感觉有点用,所以应该写在前面 - 光标切换到editor区域,ctrl+1 - 光标切换到console区域,ctrl+2 - 注释,多行或者单行以及取消 ctrl+/ 第2章 data visualizationaesthetic attributes: 图形属性 作图的几个部分: - 数据 - 图形几何 - 图形属性 x/y坐标 颜色 图形 gapminder data五大洲的分类:南北美洲算一个,再除去南极洲  20221125150423 20221125150423一共使用了好几组变量,X轴和Y轴分别代表了GDP和寿命预期,dot大小代表了人口数量,dot颜色差异代表了不同的大洲 delve: 钻研 delve into: 深入研究 这本书比较初级,对图表只考虑faceting 和position,更多的需要查看R for data science ggplot2 packages5个常用的图标5NG 1. scatterplots 2. linegraphs 3. boxplots 4. histograms 5. barplots 其余的图大多属于上述的变种,有些图表适合分类变量,另一些适合数据型变量 n. (表演者或表演团的)全部剧目,全部曲目,全部节目;全部技能(或才能) 网络释义:repertoire: 保留剧目 1. 散点图alaska_flights = flights %>% filter(carrier == "AS") ggplot(data = alaska_flights, mapping = aes(x = dep_delay, y = arr_delay) + geom_point() # 这部分是图例的,加上点型的图例大致画了一个散点图,数据来自提取到的alask_flights,geometric object选取了geom_point() Warning message: Removed 5 rows containing missing values (geom_point()).警告信息的出现是因为原始数据中缺失了5个,并没有air_time  20221125154650 20221125154650给R的图表加图层的时候,最后换行后加入,方便在添加多个图层的美观简洁 上一行末尾放个+号,换行后接着写下一行 overplotting 点太多了,很重叠。解决办法: 1. 调整点的透明度 2. 加随机的jitter或者nudges。 opaque: 不透明的 Opaque paint: 不透明涂料 opaque glass: 磨砂玻璃 反义词:transparenct nudge: 闪屏振动 Nudge Keys Left: 左方向键 Nudge Keys Right: 右方向键 使用geom_jitter()的原理是让重叠的点之间带上随机的避让,设置width和height的时候要适当考虑,太小避让不开,太大会改变原有的图形  20221125173905ggplot(data = alaska_flights, mapping = aes(x = arr_delay, y = dep_delay)) +
geom_jitter(with = 30, height = 30) #加上了随机避让的散点图 20221125173905ggplot(data = alaska_flights, mapping = aes(x = arr_delay, y = dep_delay)) +
geom_jitter(with = 30, height = 30) #加上了随机避让的散点图在geom_point()中设置alpha值调整透明度 在实际使用中,到底使用那种方法是看情况的,需要自己做出决定,最好都试试看看效果。 散点图直接反映了两个数值型变量之间的关系,比较直观, 2.线图线图也是两个数值型变量之间的关系,也叫做explanatory variable。数据天生就有顺序 代码没多大区别,只是修改了最后的geometric object 换成线图 early_january_weather = weather %>% filter(origin == "EWR" & month == 1 & day 20221125202048线图和散点图都适合反应两个数值型变量之间的关系,但是需要注意的是当x轴上的变有一个内在秩序或者顺序的时候,优先使用这些图 给图片添加labs坐标轴标签的方法见4.3 部分转换数据格式 3. histogramshistogram: 直方图 Histogram Equalization: 直方图均衡化 Histogram matching: 直方图匹配 bin把(数据)归入统计堆 stat_bin() using bins = 30. Pick better value with binwidth. 提示信息,bins默认是直方图的一个柱子30宽度,后面会学习如何修改 在geom_histogram()中添加白色垂直边框线 然后柱子填充steelblue颜色。 有时候bindwidth不太合适,需要我们手动修改一下,或者我们可以直接修改bins的总数量 ggplot(data = weather, mapping = aes(x = temp)) + geom_histogram(binwidth = 3, color = "white", fill = "steelblue") ggplot(data = weather, mapping = aes(x = temp)) + geom_histogram(bins = 40, color = "white", fill = "steelblue") 不同粒度的bin还是能在表现上有很大的区别 直方图如果取极限的话,就是折线图了吧  20221125231848faceting 20221125231848faceting多个复图,创建多个并列的图标 tilde: 波浪符 tilde or swung dash: 代字号 tilde expansion: 波浪线扩展 看代码能够发现,就是在使用某两个变量作为x和y轴变量的同时,再选取一个额外的变量月份作为split faceting的变量,同时可以在内部添加nrow或者ncol参数调整我们需要多少行或者多少列 ggplot(data = weather, mapping = aes(x = temp)) + geom_histogram(binwidth = 5, color = "white") + facet_wrap(~ month) 20221125234535ggplot(data = weather, mapping = aes(x = temp)) +
geom_histogram(binwidth = 5, color = "white") +
facet_wrap(nrow = 2, ncol = 6, ~ month) 20221125234535ggplot(data = weather, mapping = aes(x = temp)) +
geom_histogram(binwidth = 5, color = "white") +
facet_wrap(nrow = 2, ncol = 6, ~ month) 20221125235424补充统计知识 20221125235424补充统计知识以下内容只适用于数值型变量 1. 平均值 叫meam 也是average 2. median 中位数,偶数个时取中间两个数平均值 3. standard deviation SD 标准差表征的是给定数据偏离平均的程度有多大,除的是n-1而不是n  20221126115246 20221126115246Quantile: 分位数 quantile regression: 分量回归 quantile function: 分位函数 Outliers: 极端值 Models for outliers: 离群值模型 Outliers-Data: 异常点检测 whisker: 晶须 Tin whisker: 锡须 crystal whisker: 晶须 5个统计数据summary的五个数: - 最小值 - the first quantile 25th percentile $Q_1$是前半部分的中位数 - the second quantile 50th percentile - the third quantile 75th percentile $Q_3$是后半部分的中位数 - 最大值 IQR就是中间的50%,Q1和Q3中间的,最后形成了箱型图 interquartile range IQR 定义为 $Q_3$-$Q_1$,衡量中间50%是怎样分布的,对应这箱型图的箱子的长度。中位数和IQR并不会受极端值影响,而平均数和标准差会被影响。 这样IQR和中位数更适合skewed datasets: 偏斜样本集,因为IQR和中位数比极端值更强大。 whisker 是箱子的须,看起来像是从数据集的最小值到最大值,但是实际上最长不会超过从箱子上下边开始算的箱子长度的1.5倍,超出这些范围的数据成为偏离值,异常点,特殊标记。 这五个数在构建箱型图的时候,需要用到 4. 箱型图side-by-side 注意faceting是那种使用一个额外的变量对图表进行拆分,方便我们进一步区分的对比,在此之外,使用side-by-side boxplot也可以达到这种可视化的目的 使用geom_boxplot会绘制箱型图 Warning messages: 1: Continuous x aesthetic ℹ did you forget aes(group = ...)? 2: Removed 1 rows containing non-finite values (stat_boxplot()). 用连续的数值型变量绘制的图片,需要把x变量进行分组。 原来是这样的,月份之间因为无法区分导致图片无法显示月份和temp的关系  20221126130148 20221126130148factor() 的使用方法,factor是专门存放定性数据的数据结构,包括名义型和有序性,名义型无顺序,只有分类,有序性带着顺序,优良中合格差等 函数 factor() 用来创建因子,基本格式为: factor(x, levels, labels, ordered, ...) x:为创建因子的数据向量; levels:指定因子的各水平值,默认为 x 中不重复的所有值; labels:设置各水平名称 (前缀) ,与水平一一对应; ordered:设置是否对因子水平排序,默认 FALSE 为无序因子, TRUE 为有序因子; 该函数还包含参数 exclude:指定有哪些水平是不需要的 (设为 NA) ;nmax 设定水平数的上限。 若不指定参数 levels,则因子水平默认按字母顺序。我们使用factor()把月份数据进行分类,默认不重复数据,默认无序 #下面是箱型图 ggplot(data = weather, mapping = aes(x = factor(month), y = temp)) + geom_boxplot() 20221126130841 20221126130841图片中,箱子的高度等于IQR,中间50%,,如果箱子比较高的话,意味着数据分布比较散,差异范围大。whisker则是分别表示前25%和后25%的分布,最长不能超过1.5倍箱子长度,但是可以小于,末端是最大值和最小值,表示了前后25%数据的分布情况,差异情况。whisker上的点,是异常的偏离值,anomalous 不太正常的。 偏离值的定义不是绝对的,是任性专断的。 图表的有用信息,箱子的位置,高度。 查看数据差异的方法 那个月份的天气变化最大 看箱子的高度,11月份最大,而8月份最小 weather |> group_by(month) |> summarize(IQR = IQR(temp, na.rm = TRUE)) |> arrange(desc(IQR))统计weather数据中和temp相关的IQR数据,使用新的管道符号|>代替%>%传递参数,可行。 在箱型图中,偏离值比在直方图中更容易观察到,因为直方图中柱子可能不够高到让我们明显地看到。 5. 柱状图有好几种,按需使用,side-by-side stacked facted plot 通过分类变量观察数据,统计在某一个分类下的数量,或者说频率,绘制成柱状图即可。 R 中自带的数据框是 data.frame,建议改用更现代的数据框:tibble6。 Hadley 在 tibble 包中引入一种 tibble 数据框,以代替 data.frame;而且 tidyverse 包都是基于tibble 数据框。 fruits = tibble( fruit = c("apple", "apple", "orange", "apple", "orange") ) fruits_counted = tibble( fruit = c("apple", "orange"), number = c(3, 2) ) ggplot(data = fruits, mapping = aes(x = fruit)) + geom_bar() ggplot(data = fruits_counted, mapping = aes(x = fruit, y = number)) + geom_col()上面代码最终的显示效果是相同,区别在于我们是否把数据提前统计过 - 我们pre-counted过了,就用geom_col layer,并且x和y都要制定好,y指向我们count的number - 没有提前统计过,就直接用geom_bar() 尽量避免piechart 人类会高估超过90度的部分,低估小于90度的成分,对角度的认识不太准确 两组分类型变量,查看公共的分布 ,joint distribution stacked barplot 重叠棒状图  20221126170340ggplot(data = flights, mapping = aes(x = carrier, fill = origin)) +
geom_bar(position = position_dodge(preserve = "single")) 20221126170340ggplot(data = flights, mapping = aes(x = carrier, fill = origin)) +
geom_bar(position = position_dodge(preserve = "single")) 20221126170544总结 20221126170544总结 20221126171158 20221126171158ggplot中的参数中的data=、mapping=可以省略,是默认值,书后面的内容大多会省略 关于ggplot的细节,在rstudio的help cheatsheet(笑),数据可视化里面可以看到,写的非常详细 在里面我们可以看到,对变量的区分了连续性变量 continuous和离散型变量, discrete这个可以很好的对应数值型变量和分类型变量 Nuanced: 细致入微 nuanced patent: 有细微差别的 Skilled Nuanced: 娴熟入微 v. 适合,关于,适用;从属,归属;(在特定的时间或地点)生效,存在 网络释义: pertain: 相关 pertain to: 关于 pertain-dress: 皮尔卡 扑克牌 red diamond heart black spade黑桃 club梅花 permutation test: 置换检验 partial Monte Carlo permutation test: 卡罗置换检验 vt. 强调;重读 accentuate: 强调 Accentuate the positive: 肯定 accentuate e: 强调 |
【本文地址】