【Faster RCNN】损失函数理解 |
您所在的位置:网站首页 › rpn值怎么计算 › 【Faster RCNN】损失函数理解 |
【Faster RCNN】损失函数理解
|
目录 1. 使用Smoooh L1 Loss的原因 2. Faster RCNN的损失函数 2.1 分类损失 2.2 回归损失 一些感悟 关于文章中具体一些代码及参数如何得来的请看博客: tensorflow+faster rcnn代码解析(二):anchor_target_layer、proposal_target_layer、proposal_layer 最近又重新学习了一遍Faster RCNN有挺多收获的,在此重新记录一下。 1. 使用Smoooh L1 Loss的原因对于边框的预测是一个回归问题。通常可以选择平方损失函数(L2损失)f(x)=x^2。但这个损失对于比较大的误差的惩罚很高。 我们可以采用稍微缓和一点绝对损失函数(L1损失)f(x)=|x|,它是随着误差线性增长,而不是平方增长。但这个函数在0点处导数不存在,因此可能会影响收敛。 一个通常的解决办法是,分段函数,在0点附近使用平方函数使得它更加平滑。它被称之为平滑L1损失函数。它通过一个参数σ 来控制平滑的区域。一般情况下σ = 1,在faster rcnn函数中σ = 3
Faster RCNN的的损失主要分为RPN的损失和Fast RCNN的损失,计算公式如下,并且两部分损失都包括分类损失(cls loss)和回归损失(bbox regression loss)。
下面分别讲一下RPN和fast RCNN部分的损失。 2.1 分类损失公式:
(1)RPN分类损失: RPN网络的产生的anchor只分为前景和背景,前景的标签为1,背景的标签为0。在训练RPN的过程中,会选择256个anchor,256就是公式中的Ncls
可以看到这是一个这经典的二分类交叉熵损失,对于每一个anchor计算对数损失,然后求和除以总的anchor数量Ncls。这部分的代码tensorflow代码如下: rpn_cls_score = tf.reshape(self._predictions['rpn_cls_score_reshape'], [-1, 2]) #rpn_cls_score = (17100,2) rpn_label = tf.reshape(self._anchor_targets['rpn_labels'], [-1]) #rpn_label = (17100,) rpn_select = tf.where(tf.not_equal(rpn_label, -1)) #将不等于-1的labels选出来(也就是正负样本选出来),返回序号 rpn_cls_score = tf.reshape(tf.gather(rpn_cls_score, rpn_select), [-1, 2]) #同时选出对应的分数 rpn_label = tf.reshape(tf.gather(rpn_label, rpn_select), [-1]) rpn_cross_entropy = tf.reduce_mean( tf.nn.sparse_softmax_cross_entropy_with_logits(logits=rpn_cls_score, labels=rpn_label))假设我们RPN网络的特征图大小为38×50,那么就会产生38×50×9=17100个anchor,然后在RPN的训练阶段会从17100个anchor中挑选Ncls个anchor用来训练RPN的参数,其中挑选为前景的标签为1,背景的标签为0。 代码第一行将其reshape变为(17100,2),行数表示anchor的数量,列数为前景和背景,表示属于前景和背景的分数。代码第二行和第三行,将RPN的label也reshape成(17100,),即分别对应上anchor,然后从中选出不等于-1的,也就是选择出前景和背景,数量为Ncls,返回其index,为rpn_select。代码第四行,根据index选择出对应的分数。第五行,根据rpn_label和rpn_cls_score计算交叉熵损失。其中reduce_mean函数就是除以个数(Ncls)求平均。(2)Fast RCNN分类损失: RPN的分类损失时二分类的交叉熵损失,而Fast RCNN是多分类的交叉熵损失(当你训练的类别数>2时,这里假定类别数为5)。在Fast RCNN的训练过程中会选出128个rois,即Ncls = 128,标签的值就是0到4。代码为: cross_entropy = tf.reduce_mean( tf.nn.sparse_softmax_cross_entropy_with_logits( logits=tf.reshape(cls_score, [-1, self._num_classes]), labels=label)) 2.2 回归损失回归损失这块就RPN和Fast RCNN一起讲,公式为:
其中:
R是smoothL1 函数,就是我们上面说的,不同之处是这里σ = 3,RPN训练(σ = 1,Fast RCNN训练),
对于每一个anchor 计算完 对于
所以 代码: def _smooth_l1_loss(self, bbox_pred, bbox_targets, bbox_inside_weights, bbox_outside_weights, sigma=1.0, dim=[1]): sigma_2 = sigma ** 2 box_diff = bbox_pred - bbox_targets #ti-ti* in_box_diff = bbox_inside_weights * box_diff #前景才有计算损失的资格 abs_in_box_diff = tf.abs(in_box_diff) #x = |ti-ti*| smoothL1_sign = tf.stop_gradient(tf.to_float(tf.less(abs_in_box_diff, 1. / sigma_2))) #判断smoothL1输入的大小,如果x = |ti-ti*|小于就返回1,否则返回0 #计算smoothL1损失 in_loss_box = tf.pow(in_box_diff, 2) * (sigma_2 / 2.) * smoothL1_sign + (abs_in_box_diff - (0.5 / sigma_2)) * (1. - smoothL1_sign) out_loss_box = bbox_outside_weights * in_loss_box loss_box = tf.reduce_mean(tf.reduce_sum( out_loss_box, axis=dim )) return loss_box 一些感悟论文中把Ncls,Nreg和 为了平衡两种损失的权重,outside_weights的取值取决于Ncls,而Ncls的取值取决于batch_size。因此才会有
|

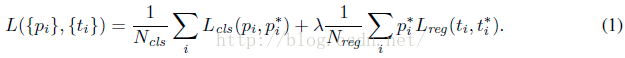
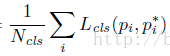



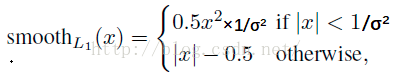

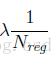 就是outside_weights,没有前景(fg)也没有后景(bg)的为0,其他为1/(bg+fg)=Ncls。
就是outside_weights,没有前景(fg)也没有后景(bg)的为0,其他为1/(bg+fg)=Ncls。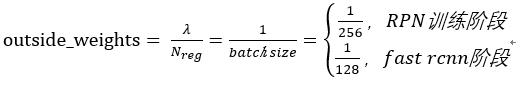
【本文地址】