【精选】深挖ROC曲线(截断值计算) |
您所在的位置:网站首页 › roc曲线怎么看阈值 › 【精选】深挖ROC曲线(截断值计算) |
【精选】深挖ROC曲线(截断值计算)
|
深挖ROC曲线(截断值计算) - 基于R语言
前言混淆矩阵1.通过混淆矩阵计算准确度
为什么需要计算截断值重点部分:AUC计算和截断值定义1.何为最佳截断值2.最大F1值的截断值(F1-optimal threshold)3.最大sensitivities+specificities
ROC曲线绘制
前言
ROC曲线,多用于二分类问题的评价,通过选取合适的截断值(阈值threshold)便能得出AUC。但很多时候我们只是单纯地通过调包来计算AUC并绘制ROC曲线,其中的原理和最佳阈值的筛选往往被人们忽略。同时笔者最近的项目中需要重新温习这些小细节,故撰文积累一下。(本文不以实际用途出发,若只想得出结果可以看看这篇: ROC曲线基于R语言) 混淆矩阵混淆矩阵是计算Accuracy(准确度),Sensitivity(敏感性, FPR)和Specificity(精确性, TPR)的必经之路。我们通过一个实例来具体阐释混淆矩阵(通过R语言的CrossTable计算所得): | prediction test$label | 0 | 1 | Row Total | -------------|-----------|-----------|-----------| 0 | 41 | 7 | 48 | | 0.854 | 0.146 | 0.475 | -------------|-----------|-----------|-----------| 1 | 9 | 44 | 53 | | 0.170 | 0.830 | 0.525 | -------------|-----------|-----------|-----------| Column Total | 50 | 51 | 101 | -------------|-----------|-----------|-----------|混淆矩阵主要包括以下四个要素: TP :True positive, 代表真正例,预测值和实际值一致且二者都为正例FN:False negative, 代表假负例,预测值和实际值不一致(预测值为负,实际为正)FP:False positive, 代表假正例,预测值和实际值不一致(预测值为正,实际为负)TN:True negative, 代表真负例,预测值和实际值一致且二者都为负例 在这个例子中我们可以看出: TP=44; FN=9;FP=7 ; TN=41 1.通过混淆矩阵计算准确度
其实这个问题要分情况,并且很多R语言的包避开了这个问题,这里我举例说明: 假设存在两个数组,一个代表预测值,一个代表实际值 predict test.label 1 1 1 2 0 1 3 1 1 4 1 1 5 1 1 6 0 1上述是最佳情况,也是我们最希望看到的,因为负例和正例极其明显,仅仅需要判断是1或0便能得出结论。但很可惜的是,很多分类器计算出来的值往往是一个概率值(特别是在随机森林,boosting这类集成学习中),这个时候问题便不再那么简单了: p.p1 test.label 1 0.9327975 1 2 0.8683321 1 3 0.9916318 1 4 0.9363141 1 5 0.9975944 1 6 0.9124761 1上面这个图中,p.p1代表正例的概率,区间在(0,1)间的连续实数。我们无法直观地判断哪一个样本该是正例,哪一个又该是负例。诚然,少数情况下人们图省事会假定阈值为0.5,高于0.5的即是正例,低于0.5的即是负例,但这种做法在某些情况下会出现极大的偏误,使得我们对模型的性能进行误判(后续举例论证)。故我们需要通过合适方法来计算截断值,并用于AUC的计算。 重点部分:AUC计算和截断值定义 1.何为最佳截断值通过前文的叙述,我们知道了截断值不能单纯地通过0.5来进行定义,那么何为最佳的截断值,该如何去计算了?目前根据不少R语言的包和论文的查阅,笔者仅总结下述几种方法: 最大F1值的截断值(F1-optimal threshold) — 来源:h2o包针对AUC的计算最大sensitivities+specificities – 来源:R语言机器学习的一本书在计算截断值时,我们往往需要知道一个图像,即ROC曲线,这个图以sensitivities和1-specificities为横纵轴,AUC则为曲线围成的面积。可能读者很难将截断值和ROC曲线联想起来,这里通过一个例子阐释: [thresholds] [sensitivities] [specificities] [1,] -Inf 1 0.00000000 [2,] 0.001026790 1 0.02083333 [3,] 0.001237295 1 0.04166667 [4,] 0.001428533 1 0.06250000 [5,] 0.001587942 1 0.08333333 [6,] 0.001710115 1 0.10416667 [97,] 0.9991705 0.09433962 1 [98,] 0.9994262 0.07547170 1 [99,] 0.9994731 0.05660377 1 [100,] 0.9995572 0.03773585 1 [101,] 0.9996690 0.01886792 1 [102,] Inf 0.00000000 1第一列是阈值,第二列是sensitivities,第三列是specificitie。随着阈值的逐渐变大(从0-1),我们发现sensitivities在逐渐变小,而specificities在逐渐变大。我们取极端情况考虑,当阈值为0时,大于0的全为正例,即模型能完美的找出所有正例(敏感性=1),但很可惜,所有的负例也被定义为正例,故特异性=0,反之阈值=1时也成立。在正常情况下,我们肯定不愿意让模型瞎猜乱蒙,故我们需要一种均衡(统计优化),类似于方差-残差均衡(但现实情况不一定完全一致),我们希望二者都能同时达到相对最优的状态。 2.最大F1值的截断值(F1-optimal threshold)这个方法来自于h2o包中的h2o.auc()函数,F1值能同时考虑sensitivities和specificities,当F1值取得最大值时,便定义该阈值为最佳阈值: |
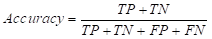
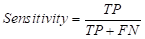
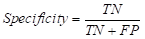 一般情况下,只要得出了混淆矩阵,我们便能根据上述公式计算出准确度等分类指标。当然这一切的前提是你得有个像样的混淆矩阵,而这就需要定义截断值了。
一般情况下,只要得出了混淆矩阵,我们便能根据上述公式计算出准确度等分类指标。当然这一切的前提是你得有个像样的混淆矩阵,而这就需要定义截断值了。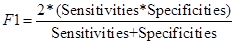 R语言代码如下:
R语言代码如下:【本文地址】
今日新闻 |
推荐新闻 |