【机器学习】模型训练前夜 |
您所在的位置:网站首页 › rip算法的预处理 › 【机器学习】模型训练前夜 |
【机器学习】模型训练前夜
|
本文代码推荐使用Jupyter notebook跑,这样得到的结果更为直观。 缺失数据处理: # 显示数据的缺失值 import pandas as pd from io import StringIO csv_data = '''A,B,C,D 1.0,2.0,3.0,4.0 5.0,6.0,,8.0 10.0,11.0,12.0,''': # csv_data = unicode(csv_data) df = pd.read_csv(StringIO(csv_data)) print(df)  # 显示每列的缺失值数量
df.isnull().sum()
# 显示每列的缺失值数量
df.isnull().sum()
 删除存在缺失值的特征或者样本:
# 删除数据集中包含缺失值的行
df.dropna()
删除存在缺失值的特征或者样本:
# 删除数据集中包含缺失值的行
df.dropna()
 # 删除数据集中至少包含一个NAN的列,axis=1。
df.dropna(axis=1)
# 删除数据集中至少包含一个NAN的列,axis=1。
df.dropna(axis=1)
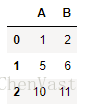 # 只在所有列都为NaN的地方删除行。
df.dropna(how='all')
# 只在所有列都为NaN的地方删除行。
df.dropna(how='all')
 # 删除没有至少4个非nan值的行。
df.dropna(thresh=4)
# 删除没有至少4个非nan值的行。
df.dropna(thresh=4)
 # 只有当NaN出现在特定列(这里:“C”)时,才会删除行。
df.dropna(subset=['C'])
# 只有当NaN出现在特定列(这里:“C”)时,才会删除行。
df.dropna(subset=['C'])
 插值技术:处理数据缺失
插值技术:处理数据缺失
最常用的插值技术:均值插补,使用相应的特征均值来替换缺失值。 from sklearn.preprocessing import Imputer imr = Imputer(missing_values='NaN', strategy='mean', axis=0) imr = imr.fit(df) imputed_data = imr.transform(df.values) print(df.values)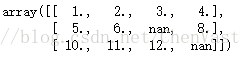 print(imputed_data)
print(imputed_data)
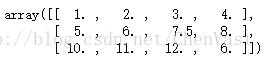
Imputer类的fit方法:对数据集中的参数进行识别并构建相应的数据补齐模型 Imputer类的transform方法:使用刚构建的数据补齐模型对数据集中相应参数的缺失值进行补齐。 数据补齐需要保持维度相同。 处理类别数据:类别数据分为:标称特征、有序特征 标称特征:不具备排序的特性 有序特征:特征为有序的或可排序的 例子: import pandas as pd df = pd.DataFrame([ ['green', 'M', 10.1, 'class1'], ['red', 'L', 13.5, 'class2'], ['blue', 'XL', 15.3, 'class1']]) df.columns = ['color', 'size', 'price', 'classlabel'] print(df) 有序特征的映射:
有序特征的映射:
类别字符串转整数: size_mapping = { 'XL': 3, 'L': 2, 'M': 1} df['size'] = df['size'].map(size_mapping) print(df)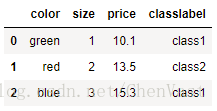 类标编码:
类标编码:
类标不是有序的 特定的字符串类标,赋予的具体整数值不重要,一般以枚举的方式从0开始设定类标。 import numpy as np class_mapping = {label:idx for idx,label in enumerate(np.unique(df['classlabel']))} class_mapping # 使用映射字典将类标转为整数
df['classlabel'] = df['classlabel'].map(class_mapping)
print(df)
# 使用映射字典将类标转为整数
df['classlabel'] = df['classlabel'].map(class_mapping)
print(df)
 # 将字典键值对倒置,还原为原始数据
inv_class_mapping = {v: k for k, v in class_mapping.items()}
df['classlabel'] = df['classlabel'].map(inv_class_mapping)
print(df)
# 将字典键值对倒置,还原为原始数据
inv_class_mapping = {v: k for k, v in class_mapping.items()}
df['classlabel'] = df['classlabel'].map(inv_class_mapping)
print(df)
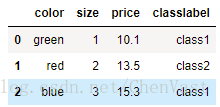 # 使用SKlearn的LabelEncoder类可以快捷的操作整数编码
from sklearn.preprocessing import LabelEncoder
class_le = LabelEncoder()
y = class_le.fit_transform(df['classlabel'].values)
print (y)
class_le.inverse_transform(y)
标称特征上的独热编码
# 使用SKlearn的LabelEncoder类可以快捷的操作整数编码
from sklearn.preprocessing import LabelEncoder
class_le = LabelEncoder()
y = class_le.fit_transform(df['classlabel'].values)
print (y)
class_le.inverse_transform(y)
标称特征上的独热编码
独热编码技术:创建一个新的虚拟特征,虚拟特征的每一列各代表标称标称数据的一个值。 # 使用OneHotEncoder类实现 from sklearn.preprocessing import OneHotEncoder ohe = OneHotEncoder(categorical_features=[0]) ohe.fit_transform(X).toarray() # 使用pandas的get_dummies实现
pd.get_dummies(df[['price', 'color', 'size']])
# 使用pandas的get_dummies实现
pd.get_dummies(df[['price', 'color', 'size']])
 将数据集划分为训练集和测试数据集:
将数据集划分为训练集和测试数据集:
使用pandas,在线从UCI机器学习样本数据库读取开源葡萄酒数据集。 df_wine = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data', header=None) df_wine.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols', 'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue', 'OD280/OD315 of diluted wines', 'Proline'] print('Class labels', np.unique(df_wine['Class label'])) df_wine.head() # 使用SKlearn下的model_selection模块中的train_test_split函数
from sklearmodel_selection import train_test_split
X, y = df_wine.iloc[:, 1:].values, df_wine.iloc[:, 0].values
X_train, X_test, y_train, y_test = \
train_test_split(X, y, test_size=0.3, random_state=0)
# 使用SKlearn下的model_selection模块中的train_test_split函数
from sklearmodel_selection import train_test_split
X, y = df_wine.iloc[:, 1:].values, df_wine.iloc[:, 0].values
X_train, X_test, y_train, y_test = \
train_test_split(X, y, test_size=0.3, random_state=0)
将数组中1-13个特征赋值给X,第一列的类标赋值给变量y。 随机将X和y各自划分为训练集合测试集, test_size=0.3表示将30%的样本划分到X_test 和y_test,剩余的划分给X_train和y_train。 划分训练集和测试集要尽量保留有价值的信息。 一般的数据量的数据集划分法为:60/40,70/30,80/20 大数据量的数据集划分为:90/10,99/1 将特征值缩放到相同的区间:特征缩放:数据预处理过程中至关重要的一步,为其保证模型的性能最佳。 将不同的特征缩放到相同的区间:归一化、标准化 归一化:将特征值缩放到[0,1]区间,最小到最大缩放的特例。 
x为特定样本,x min和x max分别为某特征列的最小值和最大值 案例: from sklearn.preprocessing import MinMaxScaler mms = MinMaxScaler() X_train_norm = mms.fit_transform(X_train) X_test_norm = mms.transform(X_test)标准化:将特征列的均值设为0,方差为1,使得特征列的值呈标准正态分布,易于权重更新。保持了异常值所蕴含的有用信息,使得算法受到这些值影响最小。 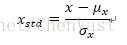
σ和μ分别为某个特征列的均值和标准差。 案例: from sklearn.preprocessing import StandardScaler stdsc = StandardScaler() X_train_std = stdsc.fit_transform(X_train) X_test_std = stdsc.transform(X_test) 选择有意义的特征值过拟合(高方差): 模型在训练集是的表现比测试集上好很多,过拟合于训练数据。 模型参数对于训练集的特定观测值拟合得非常接近 产生的原因:建立给定训练集上的模型过于复杂
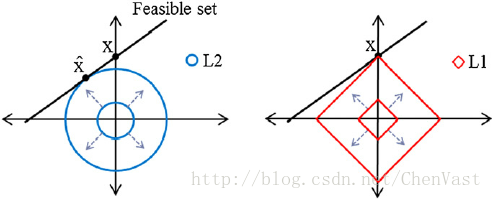
常用降低泛化误差的方案: 1、 收集更多的训练数据 2、 正则化引入罚项 3、 选择相对较少的简单模型 4、 降低数据的维度 使用L1正则化满足数据稀疏化: L1降低模型复杂度 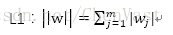
将权重的平方和用绝对值和来代替 L1正则化可以生成稀疏的特征向量,且大多数权值为0。
通过正则化参数来增加正则化的强度,使得权值向0收缩,降低模型对训练集的依赖程度 L2的罚项是二次的

SKlearn实现L1正则化代码: from sklearn.linear_model import LogisticRegression lr = LogisticRegression(penalty='l1', C=0.1) lr.fit(X_train_std, y_train) print('Training accuracy:', lr.score(X_train_std, y_train)) print('Test accuracy:', lr.score(X_test_std, y_test))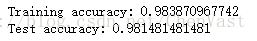
# 训练和测试的精确度表示未出现过拟合 # 获得截距项 lr.intercept_ lr.coef_
 # 绘制正则化效果图
import matplotlib.pyplot as plt
%matplotlib inline
fig = plt.figure()
ax = plt.subplot(111)
colors = ['blue', 'green', 'red', 'cyan',
'magenta', 'yellow', 'black',
'pink', 'lightgreen', 'lightblue',
'gray', 'indigo', 'orange']
weights, params = [], []
for c in np.arange(-4, 6):
lr = LogisticRegression(penalty='l1', C=10**c, random_state=0)
lr.fit(X_train_std, y_train)
weights.append(lr.coef_[1])
params.append(10**c)
weights = np.array(weights)
for column, color in zip(range(weights.shape[1]), colors):
plt.plot(params, weights[:, column],
label=df_wine.columns[column+1],
color=color)
plt.axhline(0, color='black', linestyle='--', linewidth=3)
plt.xlim([10**(-5), 10**5])
plt.ylabel('weight coefficient')
plt.xlabel('C')
plt.xscale('log')
plt.legend(loc='upper left')
ax.legend(loc='upper center',
bbox_to_anchor=(1.38, 1.03),
ncol=1, fancybox=True)
# plt.savefig('./figures/l1_path.png', dpi=300)
plt.show()
# 绘制正则化效果图
import matplotlib.pyplot as plt
%matplotlib inline
fig = plt.figure()
ax = plt.subplot(111)
colors = ['blue', 'green', 'red', 'cyan',
'magenta', 'yellow', 'black',
'pink', 'lightgreen', 'lightblue',
'gray', 'indigo', 'orange']
weights, params = [], []
for c in np.arange(-4, 6):
lr = LogisticRegression(penalty='l1', C=10**c, random_state=0)
lr.fit(X_train_std, y_train)
weights.append(lr.coef_[1])
params.append(10**c)
weights = np.array(weights)
for column, color in zip(range(weights.shape[1]), colors):
plt.plot(params, weights[:, column],
label=df_wine.columns[column+1],
color=color)
plt.axhline(0, color='black', linestyle='--', linewidth=3)
plt.xlim([10**(-5), 10**5])
plt.ylabel('weight coefficient')
plt.xlabel('C')
plt.xscale('log')
plt.legend(loc='upper left')
ax.legend(loc='upper center',
bbox_to_anchor=(1.38, 1.03),
ncol=1, fancybox=True)
# plt.savefig('./figures/l1_path.png', dpi=300)
plt.show()
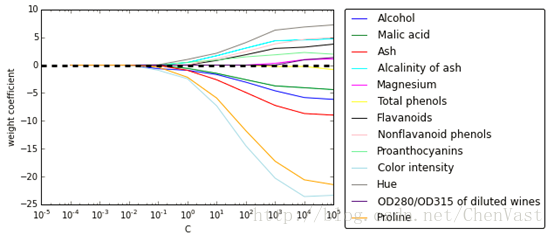
C是正则化参数的倒数。 序列特征选择算法降低模型复杂度从而解决过拟合的方法是通过特征选择进行降维 对未经正则化处理的模型特别有效 降维技术主要分为:特征降维,特征提取
序列特征选择算法是一种贪婪算法,将原始的d维特征空间压缩到一个k维的特征子空间。
经典的序列特征选择算法:序列后向选择算法(SBS) 目的:在分类性能衰减最小的约束下,降低原始特征空间上的数据维度,提高计算效率。 SBS可以在模型面临过拟合问题时提高模型的预测能力。
SBS算法理念:SBS依次从特征集合中删除某些特征,直到新的子特征包含指定数量的特征 为了确定每一步所需删除的特征,需要定义一个最小化的标准衡量函数。 函数准则:比较判定分类器的性能在删除某个特定特征前后的差异 由此可知,每一步待删除的特征,就是那些能够使得函数尽可能大的特征。
算法步骤: 1、 设k=d进行算法初始化,d是特征空间Xd的维度 2、 定义x为满足标准x=argmax(Xk-x)最大化特征 3、 将特征x从特征集中删除:X(k-1)=Xk-x,k=k-1 4、 如果k等于目标特征数量,算法终止,否则跳到2步。 python实现SBS算法: from sklearn.base import clone from itertools import combinations import numpy as np from sklearn.cross_validation import train_test_split from sklearn.metrics import accuracy_score class SBS(): def __init__(self, estimator, k_features, scoring=accuracy_score, test_size=0.25, random_state=1): self.scoring = scoring self.estimator = clone(estimator) self.k_features = k_features self.test_size = test_size self.random_state = random_state def fit(self, X, y): X_train, X_test, y_train, y_test = \ train_test_split(X, y, test_size=self.test_size, random_state=self.random_state) dim = X_train.shape[1] self.indices_ = tuple(range(dim)) self.subsets_ = [self.indices_] score = self._calc_score(X_train, y_train, X_test, y_test, self.indices_) self.scores_ = [score] while dim > self.k_features: scores = [] subsets = [] for p in combinations(self.indices_, r=dim-1): score = self._calc_score(X_train, y_train, X_test, y_test, p) scores.append(score) subsets.append(p) best = np.argmax(scores) self.indices_ = subsets[best] self.subsets_.append(self.indices_) dim -= 1 self.scores_.append(scores[best]) self.k_score_ = self.scores_[-1] return self def transform(self, X): return X[:, self.indices_] def _calc_score(self, X_train, y_train, X_test, y_test, indices): self.estimator.fit(X_train[:, indices], y_train) y_pred = self.estimator.predict(X_test[:, indices]) score = self.scoring(y_test, y_pred) return score实现SBS应用于SKlearn中KNN分类器: %matplotlib inline from sklearn.neighbors import KNeighborsClassifier import matplotlib.pyplot as plt knn = KNeighborsClassifier(n_neighbors=2) # selecting features sbs = SBS(knn, k_features=1) sbs.fit(X_train_std, y_train) # plotting performance of feature subsets k_feat = [len(k) for k in sbs.subsets_] plt.plot(k_feat, sbs.scores_, marker='o') plt.ylim([0.7, 1.1]) plt.ylabel('Accuracy') plt.xlabel('Number of features') plt.grid() plt.tight_layout() # plt.savefig('./sbs.png', dpi=300) plt.show()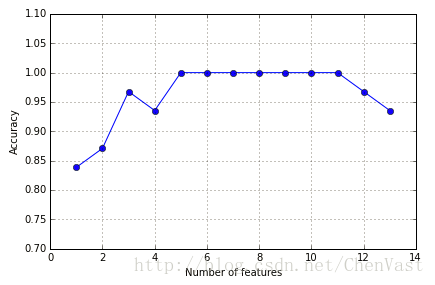
查看算法正确率达到100%的特征: k5 = list(sbs.subsets_[8]) print(df_wine.columns[1:][k5])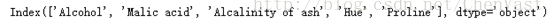
验证KNN分类器在原始测试集上的表现: knn.fit(X_train_std, y_train) print('Training accuracy:', knn.score(X_train_std, y_train)) print('Test accuracy:', knn.score(X_test_std, y_test))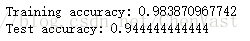
在选定的5个特征集看KNN性能: knn.fit(X_train_std[:, k5], y_train) print('Training accuracy:', knn.score(X_train_std[:, k5], y_train)) print('Test accuracy:', knn.score(X_test_std[:, k5], y_test))
当特征数量不及葡萄酒数据集原始数据特征数量一半时,测试集上的预测准确率提高。 SKlearn里有许多特征选择算法:基于特征权重的递归后向消除算法、基于特征重要性的特征选择树方法、单变量统计方法。 通过随机森林判定特征的重要性: from sklearn.ensemble import RandomForestClassifier feat_labels = df_wine.columns[1:] forest = RandomForestClassifier(n_estimators=10000, random_state=0, n_jobs=-1) forest.fit(X_train, y_train) importances = forest.feature_importances_ indices = np.argsort(importances)[::-1] for f in range(X_train.shape[1]): print("%2d) %-*s %f" % (f + 1, 30, feat_labels[f], importances[indices[f]])) plt.title('Feature Importances') plt.bar(range(X_train.shape[1]), importances[indices], color='lightblue', align='center') plt.xticks(range(X_train.shape[1]), feat_labels, rotation=90) plt.xlim([-1, X_train.shape[1]]) plt.tight_layout() # plt.savefig('./figures/random_forest.png', dpi=300) plt.show()
|

【本文地址】
今日新闻 |
推荐新闻 |