9.多级缓存、JVM进程缓存、Lua语法 |
您所在的位置:网站首页 › rimowa型号尺寸表salsa › 9.多级缓存、JVM进程缓存、Lua语法 |
9.多级缓存、JVM进程缓存、Lua语法
|
多级缓存
文章目录
多级缓存一、多级缓存介绍1.1 传统缓存的问题1.2 多级缓存方案
二、JVM进程缓存2.1 案例准备2.1.1 导入SQL2.1.2 导入item-service项目2.1.3 导入商品查询页面
2.2 初始 Caffeine2.2.1 基本用法
2.3 实现进程缓存
三、Lua语法3.1 初识Lua3.2 变量和循环3.2.1 数据类型3.2.2 变量3.2.3 循环
3.3 函数、条件控制3.3.1 函数3.3.2 条件控制
3.4 案例:自定义函数,打印table
一、多级缓存介绍
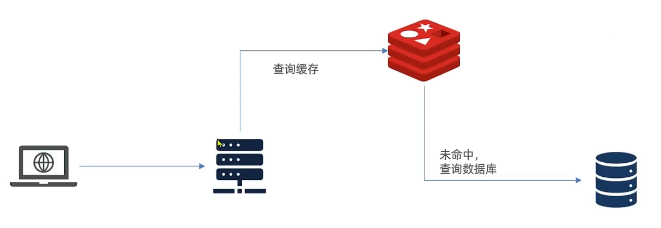
缓存的作用:减轻对数据库的压力,缩短服务响应的时间,从而提高服务的并发能力 但是如果是很高的并发量的话,仅仅靠Redis并不能满足高并发需求,而多级缓存能够应对亿级流量 1.1 传统缓存的问题传统的缓存策略一般是请求到大Tomcat后,先查询Redis,如果未命中则查询数据库,存在下面的问题: 请求要经过Tomcat处理,Tomcat的性能成为整个系统的瓶颈用户请求依然进入Tomcat,而后由Tomcat去查询Redis缓存,并且Tomcat本身的并发能力并不如Redis,在这个场景中,Tomcat成为业务的瓶颈 Redis缓存失效时,会对数据库产生冲击
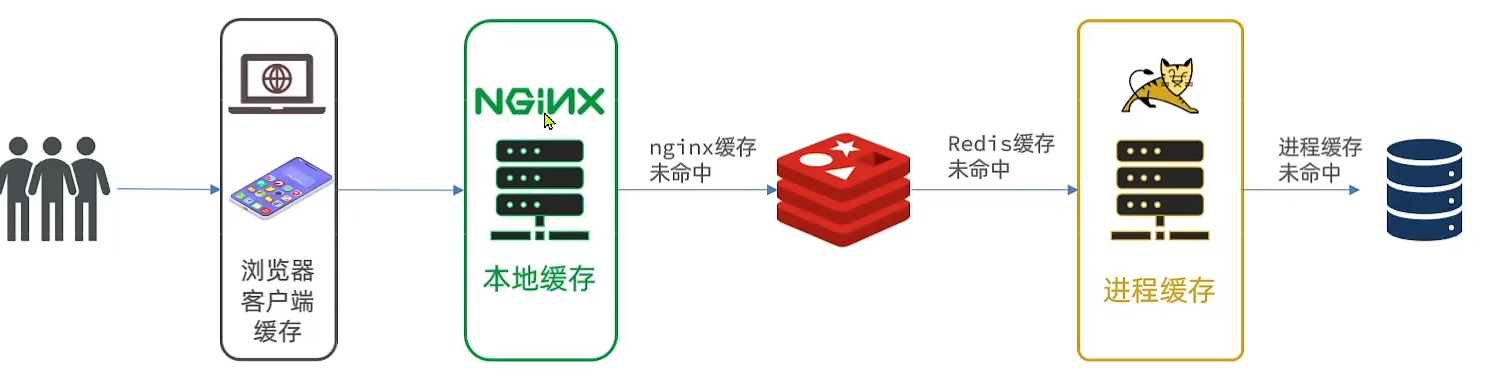
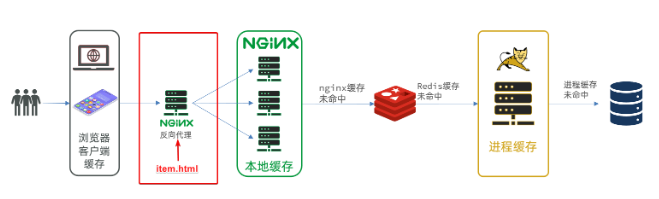
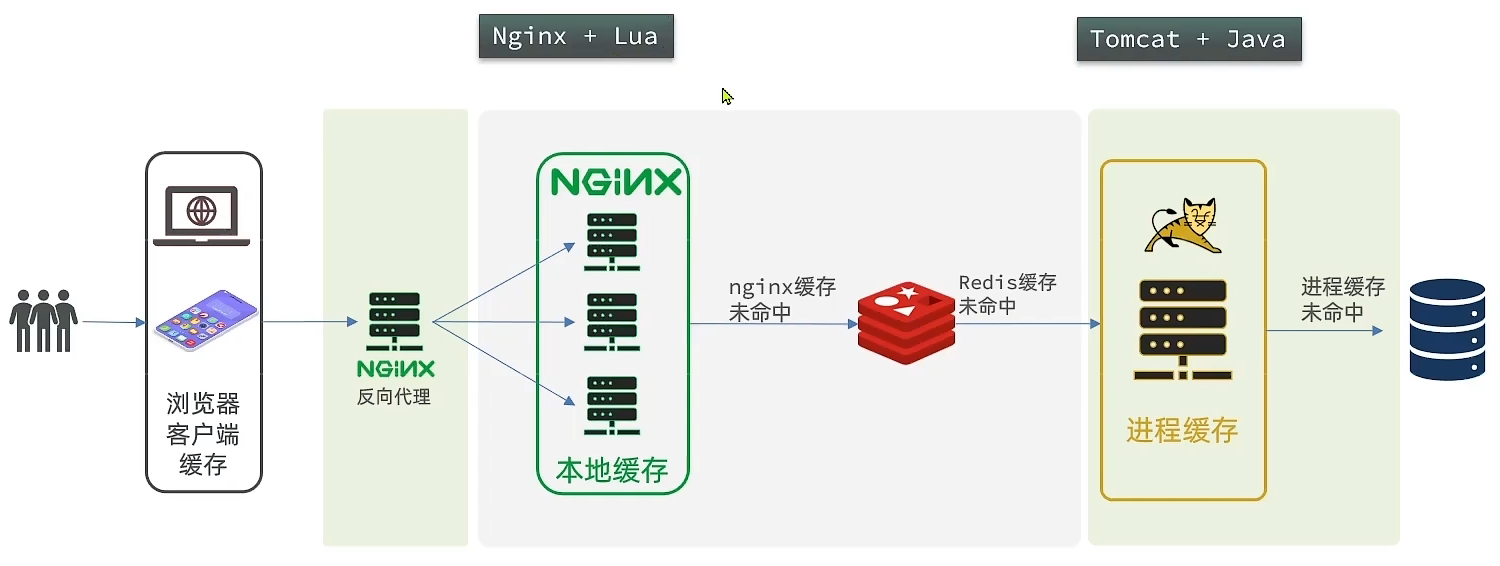
多级缓存就是充分利用请求处理的每个环节,分别添加缓存,减轻Tomcat压力,提升服务性能: ① 用户可以通过浏览器或者手机去访问我们的服务器得到数据并且渲染,在这里我们就可以形成一级缓存了,称为浏览器客户端缓存浏览器可以把服务器返回的静态资源保存在本地的,下一次再去访问静态资源的时候,我们的服务器只需要检查一下数据有没有变化,没有变化便返回304状态码,浏览器接收到304状态码就直接把本地的数据渲染,用户就能直接看到了,这样就可以减少很多的数据传输,提高渲染和响应的速度 ② 但是对于非静态数据,我们就不得不访问服务器端了,比如说请求到达了Nginx服务器以前的Nginx是用来做反向代理的,但是这里要形成第二级缓存,称为Nginx本地缓存 我们可以把数据缓存在Nginx本地,用户请求来了之后先看二级缓存有没有,如果有直接返回 ③ 如果Nginx的本地缓存没有,直接查询Redis此处查询Redis形成第三级缓存。如果Redis命中了,就返回,如果没有命中才会到大Tomcat 以前Redis是在Tomcat之后查,现在是Nginx之后查 ④Tomcat成为第四级缓存,叫做Tomcat进程缓存会在服务器的内部,利用类似map这样的形式(但并不是map),形成一个进程缓存 请求到大Tomcat之后先读取本地缓存,如果进程缓存命中后就直接返回,并不用去访问数据库了 这样Redis失效后,请求并不会直接打到mysql数据库上 模型图
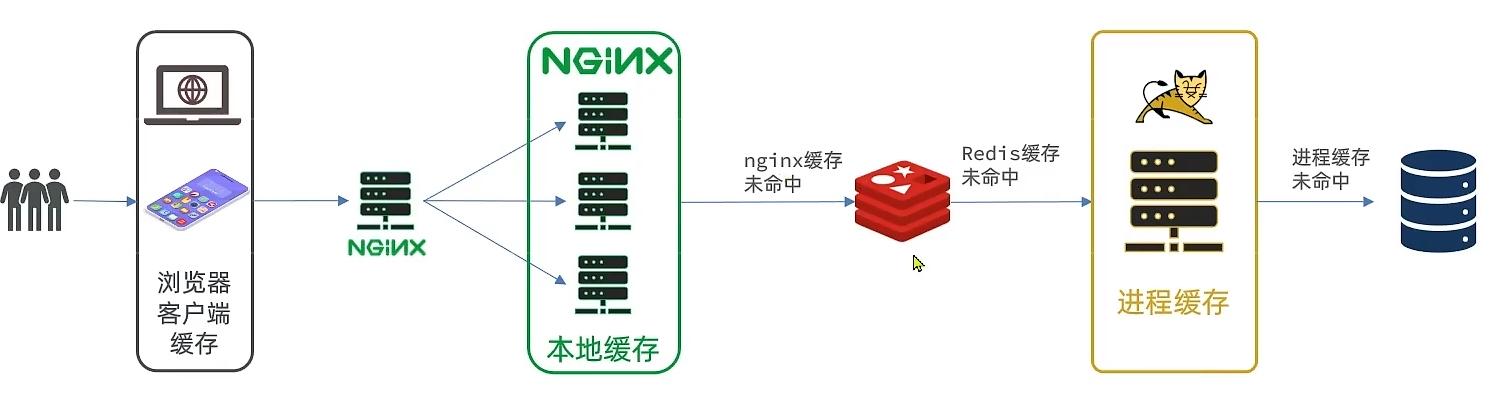
现在大部分的压力集中在了Nginx内部,此时Redis不再是一个反向代理服务器,就变成了一个真正的外部服务,可以在里面写业务逻辑,那可以将Nginx形成一个集群,才能应对一个高并发 也可以用一个单独的Nginx,来做一个反向代理,请求先到达这个单独的Nginx,然后再由其反向代理到我们多个这样的本地缓存(编写业务的Nginx服务器),之后就是Redis、Tomcat、MYSQL
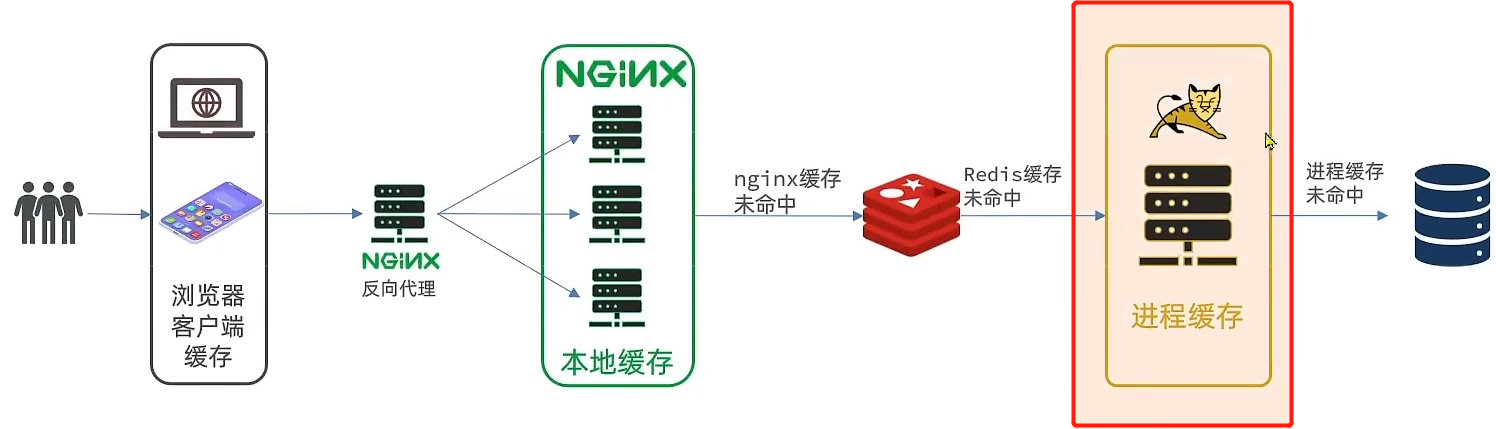
也就是下图标红的位置。也就是Tomcat服务内部去添加缓存,业务进来以后会优先查进程缓存,缓存未命中再查询数据库
其中包含两张表: tb_item:商品表,包含商品的基本信息tb_item_stock:商品库存表,包含商品的库存信息之所以将库存分离出来,是因为库存是更新比较频繁的信息,写操作较多。而其他信息修改的频率非常低。 其实就是一张表,但是做了一下分离 因为有一些信息需要经常修改,有一些信息很少修改, 修改之后需要修改缓存,操作Redis,那我们可以把经常修改的放到一张表,减少整条数据缓存过期的次数 2.1.2 导入item-service项目
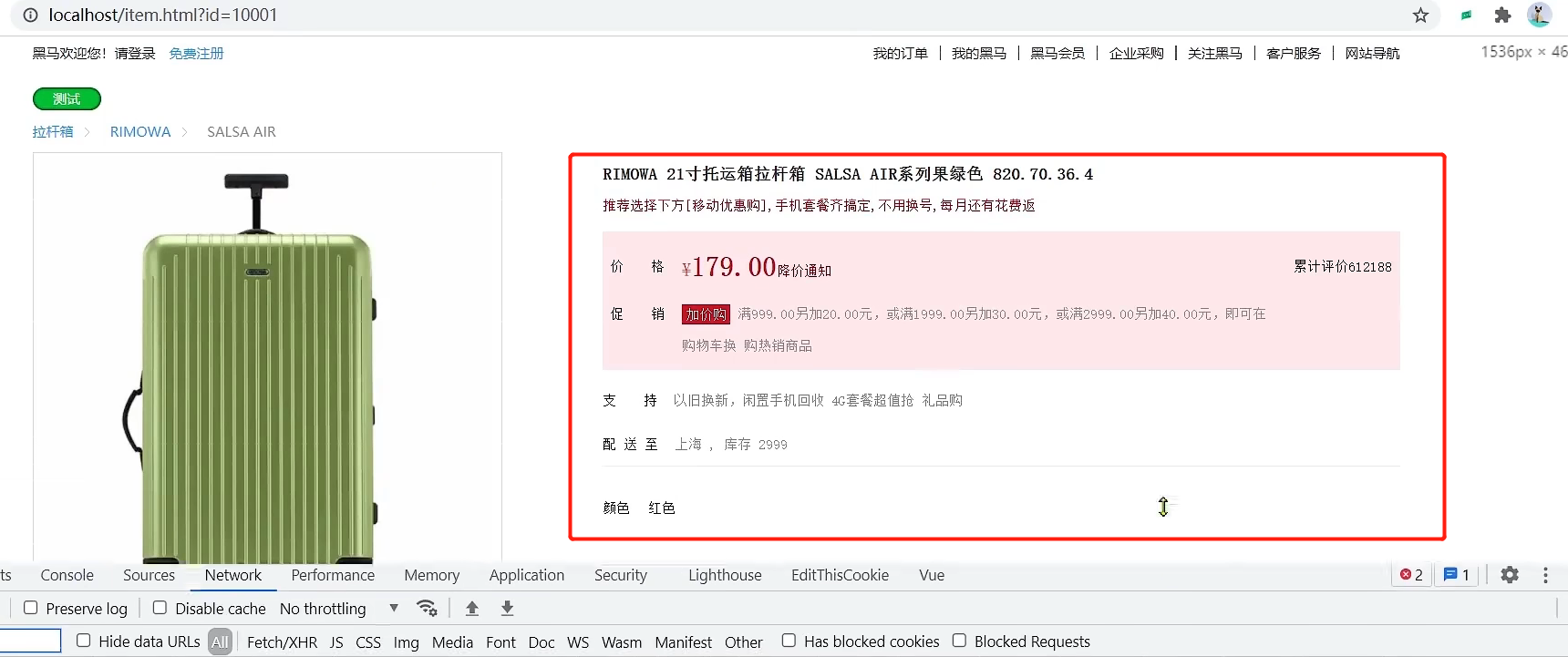
其中的业务包括: 分页查询商品新增商品修改商品修改库存删除商品根据id查询商品根据id查询库存业务全部使用mybatis-plus来实现,如有需要请自行修改业务逻辑。 启动服务,访问:http://localhost:8081/item/10001即可查询数据
商品查询是购物页面,与商品管理的页面是分离的。 部署方式如图:
我们需要准备一个反向代理的nginx服务器,如上图红框所示,将静态的商品页面放到nginx目录中。 页面需要的数据通过ajax向服务端(nginx业务集群)查询。 运行nginx服务 注意!Nginx一定不要放在有中文的目录下或者是有空格的目录录下 然后访问 http://localhost/item.html?id=10001即可(请求到了80端口,也就是Nginx服务器) 下面页面中的数据都是一些假数据,页面写死的
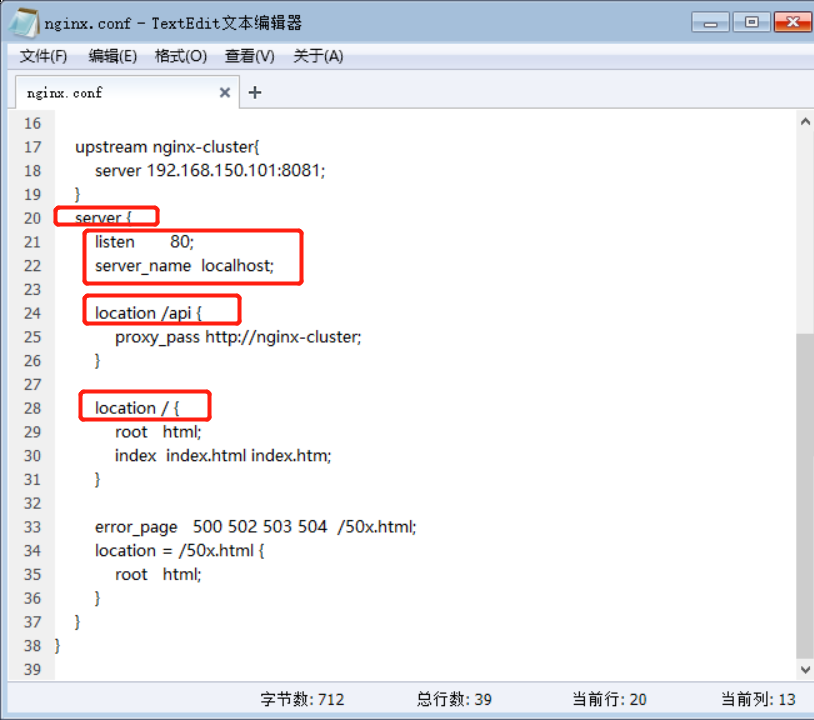
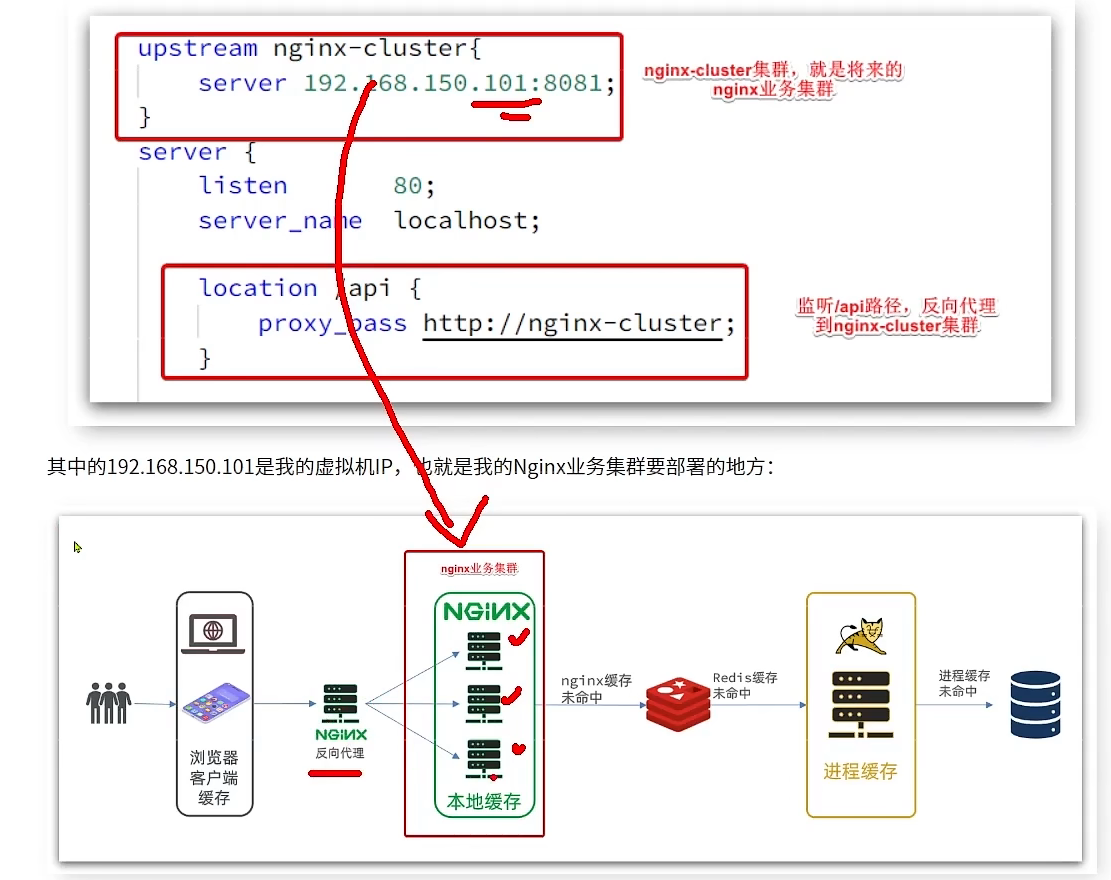
页面首先向Nginx发送请求,反向代理服务器获得请求,但是拿到后不能处理,它要把请求代理到我们的后台Nginx集群中,由后台Nginx集群完成后续的多级缓存处理 所以我们需要在这个反向代理服务器里,完成这个反向代理的配置 完成这个反向代理的配置 在Nginx中的conf目录下的nginx.conf文件下 如下面所示:
Nginx的业务集群:做Nginx的本地缓存、redis缓存、Tomcat缓存/查询等等。 如果下面的两个服务找不到,就会报错(先写一个8081,不写8082)。
比如说,以api开头的请求,会被我们的nginx配置拦截到了,拦截到后反向代理到proxy_pass http://nginx-cluster; proxy_pass http://nginx-cluster; 这是我们nginx里的负载均衡的配置
总结: 我们Windows上启动的Nginx就是起着一个反向代理的作用。 如果我们在Nginx集群中有多个Nginx,我们就可以在nginx-cluster中配置多个
导入商品案例后,就可以给商品的查询添加JVM缓存了 缓存在日常开发中启动至关重要的作用,由于是存储在内存中,数据的读取速度是非常快的,能大量减少对数据库的访问,减少数据库的压力。我们把缓存分为两类: 分布式缓存 例如Redis 优点:存储容量更大、可靠性更好、可以在集群间共享 缺点:访问缓存有网络开销. 场景:缓存数据量较大、可靠性要求较高、需要在集群间共享 假如有n台Tomcat,且都需要访问这个缓存,那我们就可以使用Redis缓存,因为Redis缓存是独立于Tomcat之外的 进程本地缓存 例如HashMap、GuavaCache 优点:读取本地内存,没有网络开销,速度更快 缺点:存储容量有限、可靠性较低、无法共享 场景:性能要求较高,缓存数据量较小0 进程本地缓存其实是作为一个分布式缓存的一个补充,当Redis缓存未命中时,再去查看一下进程本地缓存 企业当中是两者结合使用 本地缓存我们采用Caffeine。 Caffeine是一个基于Java8开发的,提供了近乎最佳命中率的高性能的本地缓存库。目前Spring内部的缓存使用的就是Caffeine GitHub地址: https://github.com/ben-manes/caffeine 在wiki里面有使用说明
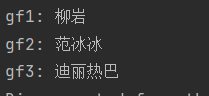
那一直这么存的话,肯定会将缓存存满,这怎么办呢? 驱逐策略。 如下三种: 基于容量 设置缓存的数量上限 //创建缓存对象 Cache cache = Caffeine.newBuilder() .maximumSize(1)//设置缓存大小上限为1个key .build(); /* 基于大小设置驱逐策略: */ @Test void testEvictByNum() throws InterruptedException { // 创建缓存对象 Cache cache = Caffeine.newBuilder() // 设置缓存大小上限为 1 .maximumSize(1) .build(); // 存数据 cache.put("gf1", "柳岩"); cache.put("gf2", "范冰冰"); cache.put("gf3", "迪丽热巴"); // 延迟10ms,给清理线程一点时间 // Thread.sleep(10L); // 获取数据 System.out.println("gf1: " + cache.getIfPresent("gf1")); System.out.println("gf2: " + cache.getIfPresent("gf2")); System.out.println("gf3: " + cache.getIfPresent("gf3")); }如果我们的线程不休眠,三个key对应的值都会输出
但是如果线程休眠后,只会输出gf3
基于时间 设置缓存的有效时间 Cache cache = Caffeine.newBuilder() //设置缓存有效期为10秒,从最后一次写入开始计时 .expireAfterWrite(Duration.ofSeconds(10)) .build(); /* 基于时间设置驱逐策略: */ @Test void testEvictByTime() throws InterruptedException { // 创建缓存对象 Cache cache = Caffeine.newBuilder() .expireAfterWrite(Duration.ofSeconds(1)) // 设置缓存有效期为 10 秒 .build(); // 存数据 cache.put("gf", "柳岩"); // 获取数据 System.out.println("gf: " + cache.getIfPresent("gf")); // 休眠一会儿 Thread.sleep(1200L); System.out.println("gf: " + cache.getIfPresent("gf")); }基于引用 设置缓存为软引用或弱引用,利用GC来回收缓存数据。性能较差,不建议使用。 在默认情况下,当一个缓存元素过期的时候,Cafeine不会自动立即将其清理和驱逐。而是在一次读或写操作后,或者在空闲时间完成对失效数据的驱逐。 2.3 实现进程缓存利用Caffeine实现下列需求 给根据id查询商品的业务添加缓存,缓存未命中时查询数据库 // 根据id查询商品 @GetMapping("/{id}") public Item findById(@PathVariable("id") Long id){ return itemCache.get(id,key->{ return itemService.query() .ne("status", 3).eq("id", key) .one(); }); // return itemService.query() // .ne("status", 3).eq("id", id) // .one(); } 给根据id查询商品库存的业务添加缓存,缓存未命中时查询数据库 // 根据id查询库存 @GetMapping("/stock/{id}") public ItemStock findStockById(@PathVariable("id") Long id){ return stockCache.get(id,key->{ return stockService.getById(id); }); // return stockService.getById(id); }缓存初始大小为100 缓存上限为10000 商品库和库存库并不是一个库,不要混淆 config配置类 @Configuration public class CaffeineConfig { // import com.github.benmanes.caffeine.cache.Cache; @Bean public Cache itemCache() { return Caffeine.newBuilder() // 初始化容量为100 .initialCapacity(100) // 最大容量10000 .maximumSize(10000) .build(); } @Bean public Cache stockCache() { return Caffeine.newBuilder() // 初始化容量为100 .initialCapacity(100) // 最大容量10000 .maximumSize(10000) .build(); } }验证商品是否成功 localhost:8081/item/10001
也成功的查询到了数据库,然后我们刷新,控制台没有任何反应
同理验证库存是否成功 localhost:8081/item/stock/10001 三、Lua语法在Nginx写业务使用Lua语法
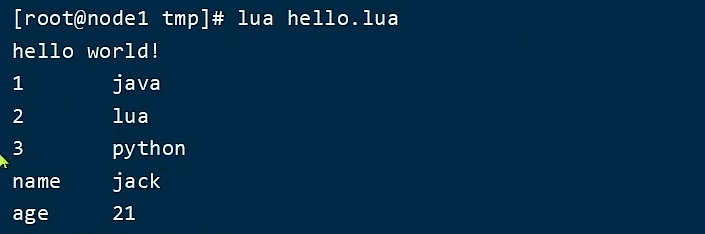
下面只是lua中常见的语法,并不是完整的 3.1 初识LuaLua是一种轻量小巧的脚本语言,用标准C语言编写并以源代码形式开放,其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。 官网: https://www.lua.org/ 在Linux虚拟机的任意目录下,新建一个hello.lua文件 touch hello.lua 添加下面的内容在文件中添加下面的内容 print("Hello World!") 运行 lua hello.lua 3.2 变量和循环 3.2.1 数据类型 数据类型描述nil只有值nil属于该类,表示一个无效值(在条件表达式中相当于false)boolean包含两个值:false和truenumber表示双精度类型的实浮点数string字符串由一对双引号或单引号来表示function由C或Lua编写的函数tableLua 中的表(table)其实是一个"关联数组"(associative arrays),数组的索引可以是数字、字符串或表类型。在 Lua里,table 的创建是通过”构造表达式"来完成,最简单构造表达式是{},用来创建一个空表。可以把这里的table理解为java中的map(更接近一点而已) 可以利用type函数测试给定变量或值的类型: print(type("Hello world")) print(type(10.4*3)) 3.2.2 变量Lua声明变量的时候,并不需要指定数据类型: -- 声明字符串 local str = 'hello!' -- 声明数字 local num = 21 -- 声明布尔类型 local flag = true -- 声明数组(数组下标从1开始) key为索引的 table local arr = ['java', 'python', 'lua'] -- 声明table,类似java的map local map ={name='Jack',age=21}访问table -- 访问数组,lua数组的角标从1开始 print(arr[1]) -- 访问table print(map['name']) print(map.name) 3.2.3 循环如果我们的变量是一个数组,我们想循环取出数据 遍历数组ipairs表示我要解析这个数组,然后解析出来的内容就是一个键值对,key与value的形式 -- 声明数组 key为索引的 table local arr = ['java', 'lua', 'python'] -- 遍历数组 for index,value in ipairs(arr) do print(index,value) end 遍历table -- 声明map,也就是table local map = {name='Jack', age=21] -- 遍历table for key,value in pairs(map) do print(key,value) end
定义函数的语法: function 函数名( argument1,argument2..., argumentn) -- 函数体 return 返回值 end例如打印数组 function printArr(arr) for index, value in ipairs(arr) do print(value) end end 3.3.2 条件控制类似java的条件控制,例如if、else语法 if(布尔表达式) then --[ 布尔表达式为 true 时执行该语句块 --] else --[ 布尔表达式为 false 时执行该语句块 --] end 3.4 案例:自定义函数,打印table需求:自定义一个函数,可以打印table,当参数为nil时,打印错误信息 local arr = {'java','lua','python'] local map = {name='jack', age= 21} local function printArr(arr) if (not arr) then print('数组不能为空!') return nil end for i, val in ipairs(arr) do print(val) end end printArr(arr) |









【本文地址】
今日新闻 |
推荐新闻 |