基于Fuzzing和ChatGPT结合的AI自动化测试实践 |
您所在的位置:网站首页 › rf接口自动化测试 › 基于Fuzzing和ChatGPT结合的AI自动化测试实践 |
基于Fuzzing和ChatGPT结合的AI自动化测试实践
 作者:沈佳明 部门:电商测试 一、前言有赞目前,结合insight接口自动化平台、horizons用例管理平台、引流回放平台、页面比对工具、数据工厂等,在研发全流程中,已经沉淀了对应的质量保障的实践经验,并在逐渐的进化中。 在AI能力大幅进步的背景下,笔者尝试将业务场景给到ChatGPT,进行了文本用例生成的测试,观察到其输出测试用例的逻辑和测试人员编写用例的逻辑有较大的相似之处。在对ChatGPT的输出结果进行简单的调整和修改后,就可以用于业务测试中了。笔者发现AI设计的测试用例场景既能包括正向场景,也能包括逆向的异常场景,并能较为准确的给出测试用例描述和预期结果。在自动化测试中,测试工程师需要花费较多的时间去设计、实现和维护用例,对于该场景,我们是否可以应用ChatGPT的内容生成能力,来提升自动化测试脚本的编写效率呢?如果结合Fuzzing的测试思路,借助大量的生成用例来执行是否能挖掘潜在的代码问题呢?下面将介绍目前在做的基于Fuzzing(模糊测试)和ChatGPT结合的探索实践。 二、调研过程 2.1 什么是Fuzzing模糊测试(Fuzzing)的核心思想是通过系统自动生成随机数据作为输入,来验证被测程序的可靠性。在测试领域中,Fuzzing经常作为一种补充接口测试手段,来覆盖/探索接口中潜在的异常/临界值场景。简单来说,系统通过给定种子用例,随机生成大批量用例,调用被测接口,尝试发现问题(挖掘bug)。 模糊测试的难点在于如何基于种子用例生成随机有效的用例数据,从业界的经验来看,测试人员通过对生成内容进行建模、设计相应算法来匹配被测对象,才能取得比较好的生成效果。随着ChatGPT的发布,其AIGC的能力令人惊艳,如果借助ChatGPT的优势,能否降低生成随机数据的成本呢?于是,笔者围绕ChatGPT生成用例的可行性进行了尝试。 2.2 ChatGPT生成用例的可行性为了验证ChatGPT生成数据的能力,笔者随机找了一份公司的PRD,摘取了一部分需求(已脱敏)来测试ChatGPT生成用例的质量,以下是调研过程中的部分结果展示。 摘取需求:商品设置了会员价-会员等级-打折,则群团团下单享受会员折扣。前置条件为当前店铺A,消费者P是店铺的会员,店铺A笔记内的商品M售价100元,运费0元,店铺设置了该商品M会员打8折。 部分问答内容:   可以从上述的图片中发现,在给定较为完善的背景情况下,ChatGPT生成的测试用例还算那么回事。笔者和相关业务同学确认,如果在ChatGPT给出的用例上再做一些调整,就可以直接用于功能测试了,所以在ChatGPT生成用例这件事上,是有可行性的,值得进一步探索。而自动化测试,无外乎将生成内容和规则变更,让ChatGPT产出可行的入参内容即可。   2.3 结合Fuzzing与ChatGPT可以做什么 2.3 结合Fuzzing与ChatGPT可以做什么经过上述的调研,模糊测试(Fuzzing)的思路是 基于种子用例生成随机用例 -> 执行用例 -> 发现问题(bug挖掘),但其难点在于如何生成高质量的随机用例,而ChatGPT的内容生成能力,似乎可以解决这一问题。笔者将两者尝试结合,模糊测试作为核心思想,ChatGPT作为用例生成服务,目标是通过大量ChatGPT生成的用例,来挖掘被测对象潜在的问题。 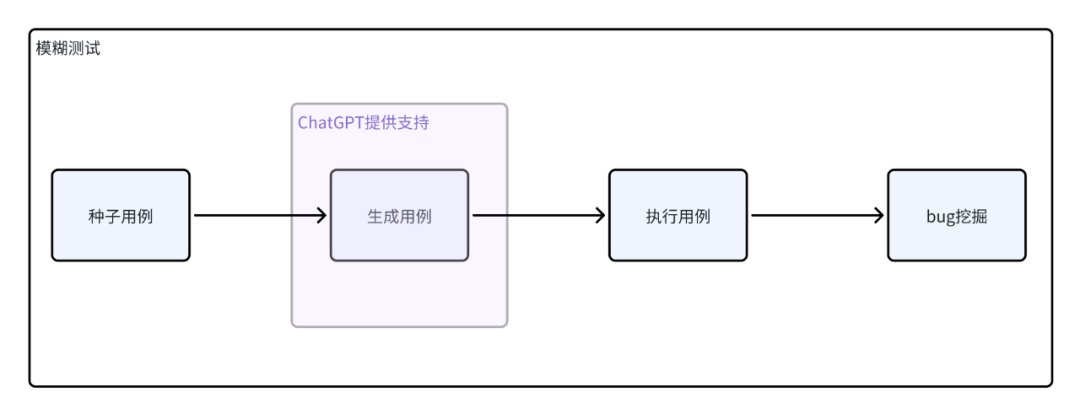 在自动化测试中,如果仅依赖模糊测试和ChatGPT生成的用例还不够,因为我们无法判断ChatGPT生成的用例是否有效,笔者尝试引入了自动化测试覆盖率的概念,将整体流程给串联起来:以模糊测试为基石,让ChatGPT来充当规则变异器,自动生成接口测试用例,覆盖率作为检验生成用例的有效性,目的是 发现问题和提高自动化测试的效率。 下面,笔者将以 ChatGPT用例生成、bug挖掘、代码覆盖率作为主线,来进行AI自动化测试实践。 三、设计与实现 前言提到,有赞已经有几个成熟的平台可以使用,为了降低实现的成本,笔者将尽可能基于现有平台的能力,来做设计与实现。 3.1 整体思路有赞目前已有成熟的接口测试平台insight、流量回放平台zan-hunter,来承接日常接口测试、线上巡检、引流回放等测试活动。基于调研结果,笔者经过整理,核心思路可概括为 拾取用例->生成用例->执行结果判别->覆盖率条件循环。具象的说,就是 (1)insight/zan-hunter 获取用例生成模版数据 ->(2)根据模版数据生成ChatGPT的输入(prompt)->(3)调用ChatGPT,根据要求生成用例(JSON输出)-> (4) 执行用例,调用java应用的接口进行测试 ,输出测试结果(bug挖掘)->(5)获取接口对应的行覆盖率,并根据判断是否要继续执行 ->(6)循环往复,直到覆盖率摸高到天花板(可能是70%~80%)->(9)End。 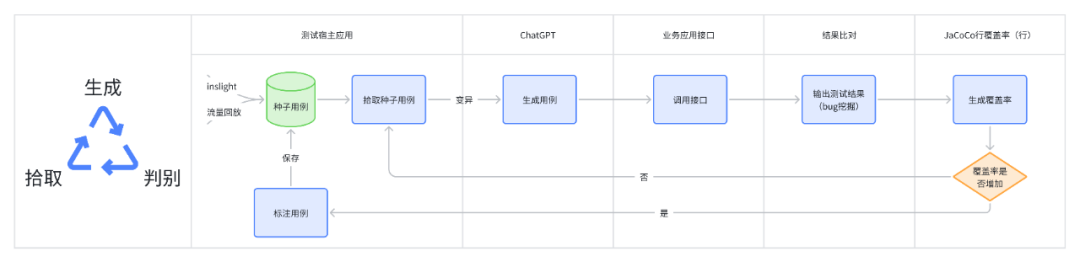 在现有资源限制、功能实现复杂度较高的背景下,笔者将其拆解为2个阶段来完成,同时本期将优先实现第一阶段的功能: 第一阶段:完成基于ChatGPT用例推荐,结合insight 用例创建与执行来实现测试环境与基准环境的结果比对,验证ChatGPT用例推荐有效性和被测代码稳定性,目标是能够挖掘出有效问题。第二阶段:接入自动化覆盖率采集能力。目的是通过接口执行覆盖率是否提升的判断,来优化测试用例生成的有效性,使其达到目标自动化覆盖率。 3.2 功能设计笔者根据实际情况,将实现内容做了拆解。 第一阶段需要实现的功能分成3块:1. 搭建自动生成推荐用例前端展示、后端增删改查的框架;2. 后端用例生成核心逻辑部分;3.后端用例执行结束bug挖掘部分。 第二阶段的功能做了简单的设计规划,主要是 覆盖率的收集、比对判别、有效用例筛选标记、循环生成用例四大块。 以下主要是自动生成推荐用例的后端服务部分的流程图。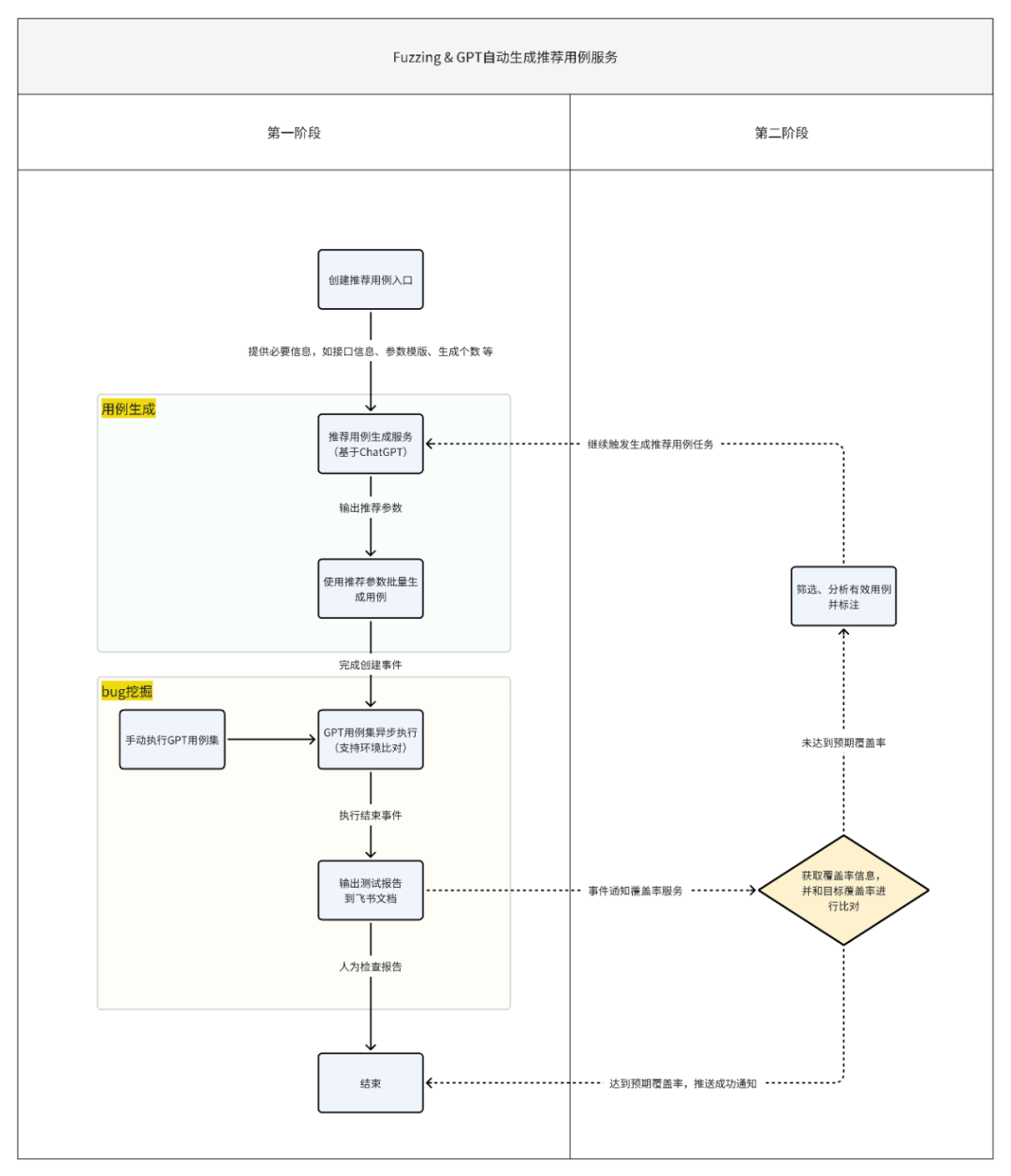 3.3 实现情况 3.3 实现情况目前,第一阶段的开发和验证已经结束,包括基于ChatGPT的推荐用例生成服务、用例执行、断言回写、结果输出等。实践结果证明基于ChatGPT创建的推荐用例,已经能够正确执行并感知到代码异常错误。第二阶段做了初步调研,暂未实现功能。 基于ChatGPT的推荐用例生成服务:前端页面输入提供生成规则,系统推荐参数模版;后端基于GPT-3.5模型,设计prompt来生成准确可靠的随机内容入参,结合insight已有能力,创建测试用例与执行集。   用例创建执行:基于ChatGPT生成的随机内容入参构建测试用例和创建执行集,insight执行并获得测试报告。(左:执行集详情;右:执行集结果) 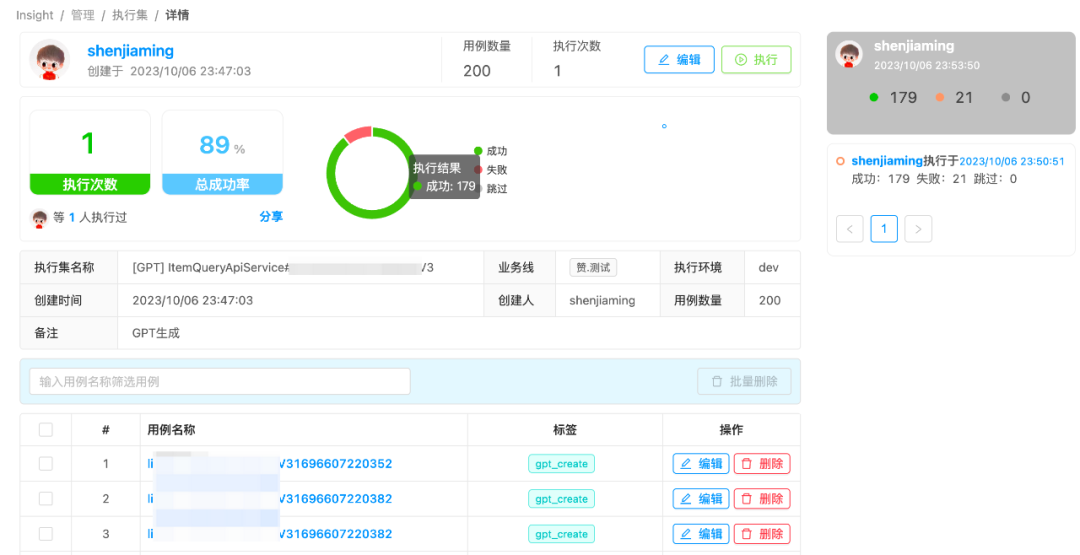 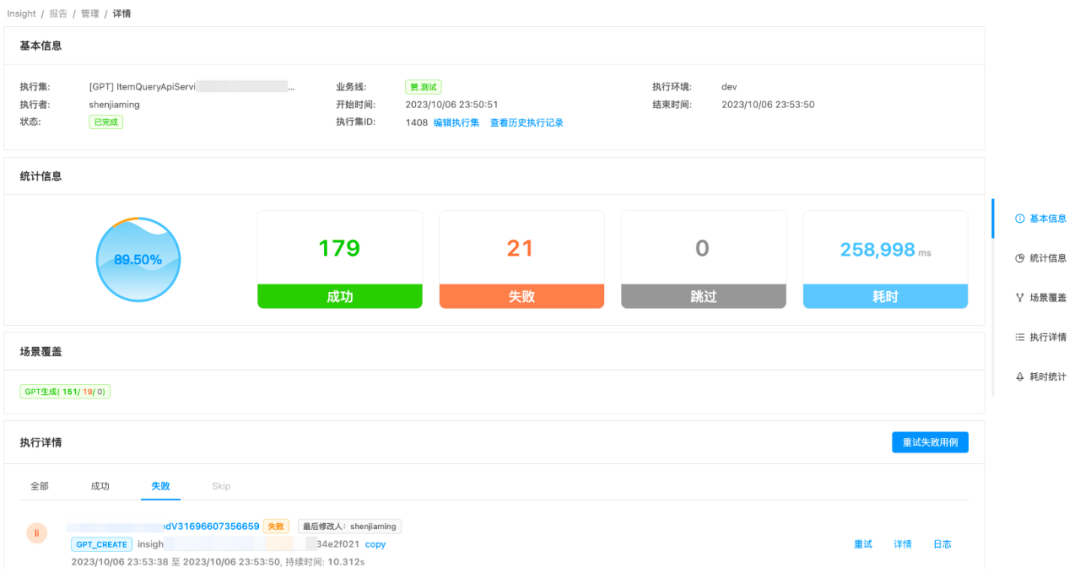 断言回写:由于执行结果的不确定性,我们将每一条用例第一次执行的结果作为用例基准断言。 结果输出:insight平台还没有合适的聚合结果展示能力,我们将每一条用例第一次执行的结果、后续执行的失败结果,系统进行规则过滤后,将潜在风险问题均输出到飞书文档,方便测试人员可视化观察。(左:平台单条错误展示;右:飞书表格聚合展示) bug挖掘: 由于输出的结果经过系统的第一次过滤,产生报告量数据适中,可以通过人为检查结果的方式来判断在当次执行的结果中,是否存在有效问题。  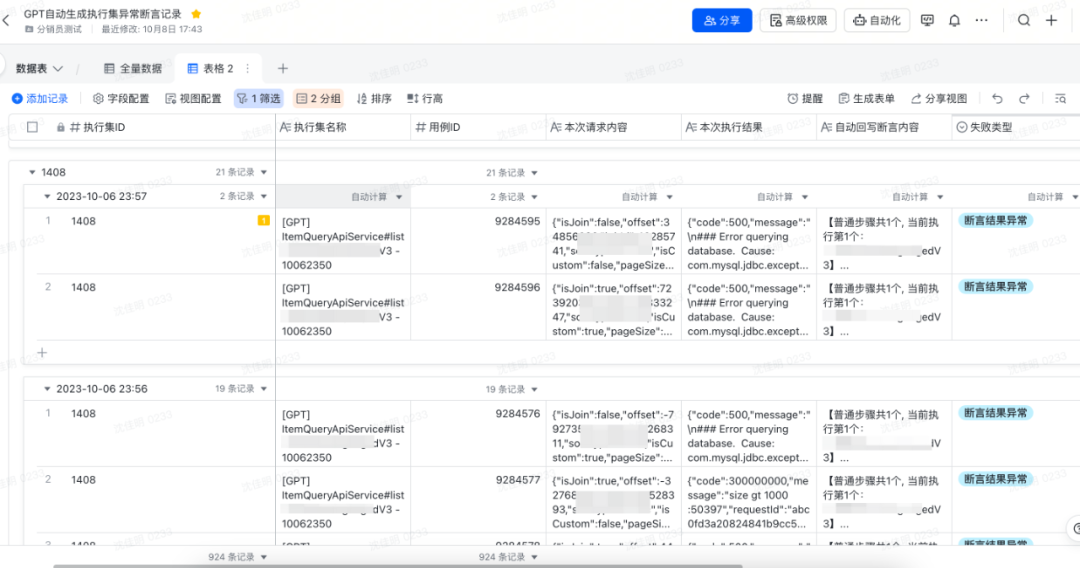 3.4 现阶段使用效果 3.4 现阶段使用效果由于资源分配、时间的关系,目前只完成第一阶段功能的开发验证。这里也将只基于第一阶段已经实现的能力做下使用总结,主要从生成速率、生成质量上来阐述使用效果。 3.4.1 用例生成速率通过ChatGPT生成千条用例并执行完毕产出报告的速率在8分钟左右(测试条件:推荐用例生成的入参字段个数 |
【本文地址】
今日新闻 |
推荐新闻 |