Pytorch用自己的数据训练ResNet |
您所在的位置:网站首页 › resnet显存 › Pytorch用自己的数据训练ResNet |
Pytorch用自己的数据训练ResNet
|
一. ResNet算法介绍
残差神经网络(ResNet)是由微软研究院的何恺明等人提出的。ResNet 在2015 年的ILSVRC中取得了冠军。 通过实验,ResNet随着网络层不断的加深,模型的准确率先是不断的提高,达到最大值(准确率饱和),然后随着网络深度的继续增加,模型准确率毫无征兆的出现大幅度的降低。这个现象与“越深的网络准确率越高”的信念显然是矛盾的、冲突的。ResNet团队把这一现象称为“退化(Degradation)”。 按道理,给网络叠加更多层,浅层网络的解空间是包含在深层网络的解空间中的,深层网络的解空间至少存在不差于浅层网络的解,因为只需将增加的层变成恒等映射,其他层的权重原封不动copy浅层网络,就可以获得与浅层网络同样的性能。更好的解明明存在,为什么找不到?找到的反而是更差的解? 训练集上的性能下降,可以排除过拟合,BN层的引入也基本解决了plain net的梯度消失和梯度爆炸问题。如果不是过拟合以及梯度消失导致的,那原因是什么? 显然,这是个优化问题,反映出结构相似的模型,其优化难度是不一样的,且难度的增长并不是线性的,越深的模型越难以优化。 有两种解决思路,一种是调整求解方法,比如更好的初始化、更好的梯度下降算法等;另一种是调整模型结构,让模型更易于优化——改变模型结构实际上是改变了error surface的形态。 ResNet从调整模型结构的角度出发,提出了残差块的概念。实际原理就是,让网络深层的每一个残差块都尽可能的学习恒等式。这样相当于简化了任务,网络深度也可更深。
为什么残差块要这样设计呢? ResNet的目的是设计一个恒等映射的网络,但神经网络拟合恒等式的任务比较复杂,不如直接学习到残差的映射。然后网络的目的是为了让残差等于零,这样就相当于一个恒等映射网络了。如图2所示为一个残差块,F(x)表示残差学习路径,x表示shortcut路径,学习后得到的映射关系为: 在原论文中,残差路径可以大致分成2种,一种有bottleneck结构,即下图右中的1×1 卷积层,用于先降维再升维,主要出于降低计算复杂度的现实考虑,称之为“bottleneck block”,另一种没有bottleneck结构,如下图左所示,称之为“basic block”。basic block由2个3×3卷积层构成。
ResNet为多个Residual Block的串联,其结构非常容易修改和扩展,通过调整block内的channel数量以及堆叠的block数量,就可以很容易地调整网络的宽度和深度,来得到不同表达能力的网络,而不用过多地担心网络的“退化”问题,只要训练数据足够,逐步加深网络,就可以获得更好的性能表现。目前ResNet最常被用来做为检测网络的backbone, 常用的结构有ResNet-50, ResNet-101等。 二、数据集介绍本次实验使用手势识别的开源数据集,训练一个手势分类器。数据集来源于项目https://codechina.csdn.net/EricLee/classification,一共有2850个样本,分为14类。
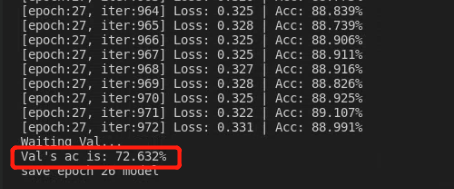
数据的pytorch定义没什么好说的,基本步骤。根据自己的数据特性重写几个函数就可以。在本次实验中,样本按照5:1的比例分为训练集和验证集。 import torch import torch.nn as nn from torch.utils.data import DataLoader,Dataset from torchvision import transforms as T import matplotlib.pyplot as plt import os from PIL import Image import numpy as np import random class hand_pose(Dataset): def __init__(self, root, train=True, transforms=None): imgs = [] for path in os.listdir(root): path_prefix = path[:3] if path_prefix == "000": label = 0 elif path_prefix == "001": label = 1 elif path_prefix == "002": label = 2 elif path_prefix == "003": label = 3 elif path_prefix == "004": label = 4 elif path_prefix == "005": label = 5 elif path_prefix == "006": label = 6 elif path_prefix == "007": label = 7 elif path_prefix == "008": label = 8 elif path_prefix == "009": label = 9 elif path_prefix == "010": label = 10 elif path_prefix == "011": label = 11 elif path_prefix == "012": label = 12 elif path_prefix == "013": label = 13 else: print("data label error") childpath = os.path.join(root, path) for imgpath in os.listdir(childpath): imgs.append((os.path.join(childpath, imgpath), label)) train_path_list, val_path_list = self._split_data_set(imgs) if train: self.imgs = train_path_list else: self.imgs = val_path_list if transforms is None: normalize = T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) self.transforms = T.Compose([ T.Resize(256), T.CenterCrop(224), T.ToTensor(), normalize ]) else: self.transforms = transforms def __getitem__(self, index): img_path = self.imgs[index][0] label = self.imgs[index][1] data = Image.open(img_path) if data.mode != "RGB": data = data.convert("RGB") data = self.transforms(data) return data,label def __len__(self): return len(self.imgs) def _split_data_set(self, imags): """ 分类数据为训练集和验证集,根据个人数据特点设计,不通用。 """ val_path_list = imags[::5] train_path_list = [] for item in imags: if item not in val_path_list: train_path_list.append(item) return train_path_list, val_path_list if __name__ == "__main__": root = "handpose_x_gesture_v1" train_dataset = hand_pose(root, train=False) train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True) for data, label in train_dataloader: print(data.shape) print(label) break因为nn.CrossEntroyLoss内部包含了softmax和ont-hot编码处理,所以在数据定义时不用进行ont-hot处理,且类别按照int进行排序即可(0,1,2,。。。) 三、模型训练 3.1 模型网络定义 import torch from torch import nn class Bottleneck(nn.Module): # 残差块定义 extention = 4 def __init__(self, inplanes, planes, stride, downsample=None): super(Bottleneck, self).__init__() self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, stride=stride, bias=False) self.bn1 = nn.BatchNorm2d(planes) self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(planes) self.conv3 = nn.Conv2d(planes, planes*self.extention, kernel_size=1, stride=1, bias=False) self.bn3 = nn.BatchNorm2d(planes*self.extention) self.relu = nn.ReLU(inplace=True) self.downsample = downsample self.stride = stride def forward(self, x): shortcut = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) out = self.relu(out) out = self.conv3(out) out = self.bn3(out) out = self.relu(out) if self.downsample is not None: shortcut = self.downsample(x) out = out + shortcut # 不能写作out+=shortcut out = self.relu(out) return out class ResNet50(nn.Module): def __init__(self, block, layers, num_class): self.inplane = 64 super(ResNet50,self).__init__() self.block = block self.layers = layers self.conv1 = nn.Conv2d(3, self.inplane, kernel_size=7, stride=2, padding=3, bias=False) self.bn1 = nn.BatchNorm2d(self.inplane) self.relu = nn.ReLU() self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) self.stage1=self.make_layer(self.block,64,layers[0],stride=1) self.stage2=self.make_layer(self.block,128,layers[1],stride=2) self.stage3=self.make_layer(self.block,256,layers[2],stride=2) self.stage4=self.make_layer(self.block,512,layers[3],stride=2) self.avgpool = nn.AvgPool2d(7) self.fc = nn.Linear(512*block.extention, num_class) def forward(self, x): out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.maxpool(out) #block部分 out=self.stage1(out) out=self.stage2(out) out=self.stage3(out) out=self.stage4(out) out=self.avgpool(out) out=torch.flatten(out,1) out=self.fc(out) return out def make_layer(self, block, plane, block_num, stride=1): block_list = [] downsample = None if(stride!=1 or self.inplane!=plane*block.extention): downsample = nn.Sequential( nn.Conv2d(self.inplane, plane*block.extention, stride=stride, kernel_size=1, bias=False), nn.BatchNorm2d(plane*block.extention) ) conv_block = block(self.inplane, plane, stride=stride, downsample=downsample) block_list.append(conv_block) self.inplane = plane*block.extention for i in range(1,block_num): block_list.append(block(self.inplane, plane, stride=1)) return nn.Sequential(*block_list) if __name__ == "__main__": resnet = ResNet50(Bottleneck,[3,4,6,3],14) x = torch.randn(64,3,224,224) x = resnet(x) print(x.shape)网络定义两部分,bottleneck是残差网络的基本模块,Resnet50是整个网络架构,和下图的网络结构对应。 注意在定义残差块bottleneck时,shortcut的跳连相加部分,不能写作out += shortcut,具体原因是out要保存下来进行backend的梯度计算,而+=是inplace操作,改变了变量。 如果用inplace的写法,会报错,报错信息为: RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: 3.2 训练 import torch import torch.nn as nn from torch.utils.data import DataLoader,Dataset from Data import hand_pose from Model import ResNet50, Bottleneck import os def main(): # 1. load dataset root = "handpose_x_gesture_v1" batch_size = 64 train_data = hand_pose(root, train=True) val_data = hand_pose(root, train=False) train_dataloader = DataLoader(train_data,batch_size=batch_size,shuffle=True) val_dataloader = DataLoader(val_data,batch_size=batch_size,shuffle=True) # 2. load model num_class = 14 model = ResNet50(Bottleneck,[3,4,6,3], num_class) device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = model.to(device) # 3. prepare super parameters criterion = nn.CrossEntropyLoss() learning_rate = 1e-3 optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) epoch = 30 # 4. train val_acc_list = [] out_dir = "checkpoints/" if not os.path.exists(out_dir): os.makedirs(out_dir) for epoch in range(0, epoch): print('\nEpoch: %d' % (epoch + 1)) model.train() sum_loss = 0.0 correct = 0.0 total = 0.0 for batch_idx, (images, labels) in enumerate(train_dataloader): length = len(train_dataloader) images, labels = images.to(device), labels.to(device) optimizer.zero_grad() outputs = model(images) # torch.size([batch_size, num_class]) loss = criterion(outputs, labels) loss.backward() optimizer.step() sum_loss += loss.item() _, predicted = torch.max(outputs.data, dim=1) total += labels.size(0) correct += predicted.eq(labels.data).cpu().sum() print('[epoch:%d, iter:%d] Loss: %.03f | Acc: %.3f%% ' % (epoch + 1, (batch_idx + 1 + epoch * length), sum_loss / (batch_idx + 1), 100. * correct / total)) #get the ac with testdataset in each epoch print('Waiting Val...') with torch.no_grad(): correct = 0.0 total = 0.0 for batch_idx, (images, labels) in enumerate(val_dataloader): model.eval() images, labels = images.to(device), labels.to(device) outputs = model(images) _, predicted = torch.max(outputs.data, dim=1) total += labels.size(0) correct += (predicted == labels).sum() print('Val\'s ac is: %.3f%%' % (100 * correct / total)) acc_val = 100 * correct / total val_acc_list.append(acc_val) torch.save(model.state_dict(), out_dir+"last.pt") if acc_val == max(val_acc_list): torch.save(model.state_dict(), out_dir+"best.pt") print("save epoch {} model".format(epoch)) if __name__ == "__main__": main()训练时每次epoch都分别在训练集和验证集测试准确率,并保存模型。 最终的训练结果如下。
训练集的准确率为88,验证集只有72.6,毫无疑问模型是存在一些过拟合的。究其原因是因为数据量太少,一共2850个样本,还按照5:1的比例分成了训练集和验证集。如果是使用迁移学习,用预训练模型来初始化模型,然后再训练,效果应该会好很多。 3.3 迁移学习迁移学习(Transfer learning) 顾名思义就是把已训练好的模型参数迁移到新的模型来帮助新模型训练。考虑到大部分数据或任务都是存在相关性的,所以通过迁移学习我们可以将已经学到的模型参数(也可理解为模型学到的知识)通过某种方式来分享给新模型从而加快并优化模型的学习效率不用像大多数网络那样从零学习。 优点:1. 加快训练速度,loss很快收敛; 2. 可以减少过拟合,得到泛化能力更强的模型。 因为我们自己定义的模型跟论文里的resnet50有所出入,所以直接加载网上的预训练模型是不行的。这里我们用torchvision自带的resnet50网络,然后加载预训练模型,改掉最后全连接层,然后训练。只需要在train.py里加载模型这里进行修改就可以。 # 2. load model num_class = 14 # model = ResNet50(Bottleneck,[3,4,6,3], num_class) model = models.resnet50(pretrained=True) fc_inputs = model.fc.in_features model.fc = nn.Linear(fc_inputs, num_class) device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = model.to(device)最终训练结果如下,在epoch到达22时候,loss很小了,验证集准确率为88,训练集准确率为99
为什么从零学习和fine-tune学习后的差距这么大呢,损失函数的大小差了十倍,验证集准确率差了20。个人觉得是还是跟初始化的关系大一点,初始化让loss不在一个局部最小值处打转,找到了更低的点,所以提高了模型的性能,但过拟合的问题依旧存在。
|





【本文地址】
今日新闻 |
推荐新闻 |