Le |
您所在的位置:网站首页 › resnet和vgg区别 › Le |
Le
|
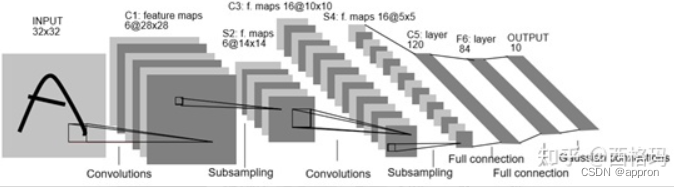
Le-Net Lenet也称Lenet-5,共5个隐藏层(不考虑磁化层),网络结构为:
AlexNet 提出背景:解决Lenet识别大尺寸图片进行的效果不尽人意的问题 与LeNet相比,AlexNet具有更深的网络结构,共8个隐藏层,包含5层卷积和3层全连接,网络结构为:
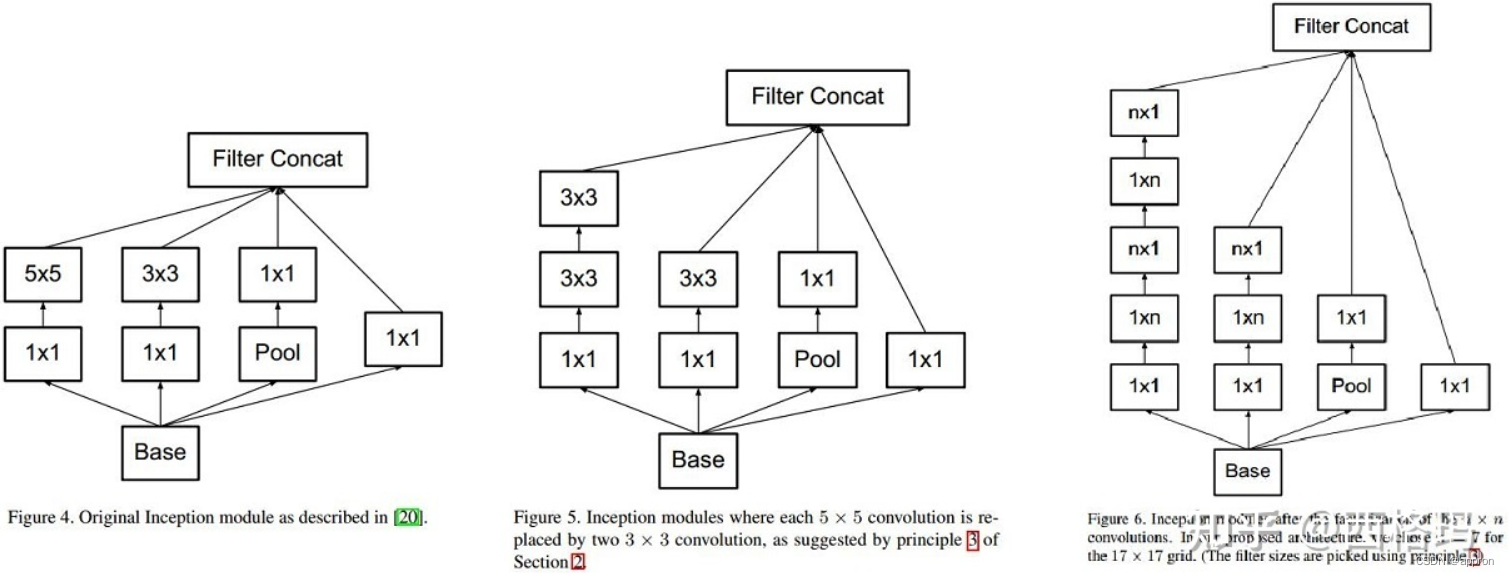
同时使用了如下方法改进模型的训练过程: 数据增广:深度学习中常用的一种处理方式,通过对训练随机加一些变化,比如平移、缩放、裁剪、旋转、翻转或者增减亮度等,产生一系列跟原始图片相似但又不完全相同的样本,从而扩大训练数据集。通过这种方式,可以随机改变训练样本,避免模型过度依赖于某些属性,能从一定程度上抑制过拟合。(过拟合:算法模型比数据模型复杂,解决是降低算法模型复杂度,例如dropout,L1,L2正则化,或者增加数据复杂度,例如获得更多数据。当然,Early stopping也可以,不让学习过度,集成学习也可以,毕竟解决一切)使用Dropout抑制过拟合使用ReLU激活函数减少梯度消失现象(梯度消失和梯度爆炸):在AlexNet之前,神经网络一般都使用sigmoid或tanh作为激活函数,这类函数在自变量非常大或者非常小时,函数输出基本不变,称之为饱和函数。为了提高训练速度,AlexNet使用了修正线性函数ReLU,它是一种非饱和函数,与 sigmoid 和tanh 函数相比,ReLU分片的线性结构实现了非线性结构的表达能力,梯度消失现象相对较弱,有助于训练更深层的网络。使用GPU训练。与CPU不同的是,GPU转为执行复杂的数学和几何计算而设计,AlexNet使用了2个GPU来提升速度,分别放置一半卷积核。局部响应归一化。AlexNet使用局部响应归一化技巧,将ImageNet上的top-1与top-5错误率分别减少了1.4%和1.2%。重叠池化层。与不重叠池化层相比,重叠池化层有助于缓解过拟合,使得AlexNet的top-1和top-5错误率分别降低了0.4%和0.3%。VggNet 提出背景:alexNet虽然效果好,但是没有给出深度神经网络的设计方向。即,如何把网络做到更深。 在论文中有VGG-11,VGG-13,VGG-16,VGG-19的实验比较,VGG-16的效果最佳,这里给出网络结构。 VGG11:Conv(3*3,64,1)*1+Conv(3*3,128,1)*1+Conv(3*3,256,1)*2+Conv(3*3,512,1)*2+Conv(3*3,512,1)*2+FC(4096)+FC(4096)+FC(1000)VGG13:Conv(3*3,64,1)*2+Conv(3*3,128,1)*2+Conv(3*3,256,1)*2+Conv(3*3,512,1)*2+Conv(3*3,512,1)*2+FC(4096)+FC(4096)+FC(1000)VGG16:Conv(3*3,64,1)*2+Conv(3*3,128,1)*2+Conv(3*3,256,1)*3+Conv(3*3,512,1)*3+Conv(3*3,512,1)*3+FC(4096)+FC(4096)+FC(1000)VGG19:Conv(3*3,64,1)*2+Conv(3*3,128,1)*2+Conv(3*3,256,1)*4+Conv(3*3,512,1)*4+Conv(3*3,512,1)*4+FC(4096)+FC(4096)+FC(1000)vggnet严格使用3*3小尺寸卷积和池化层构造深度CNN,取得较好的效果。小卷积能减少参数,方便堆叠卷积层来增加深度(加深了网络,减少了卷积)。即vggnet=更深的Alex net+conv(3*3) googlenet 背景:alexNet虽然效果好,但是没有给出深度神经网络的设计方向。即,如何把网络做到更深。 googlenet设计了inception结构来降低通道数,减少计算复杂度,其中inception结构包括以下几种
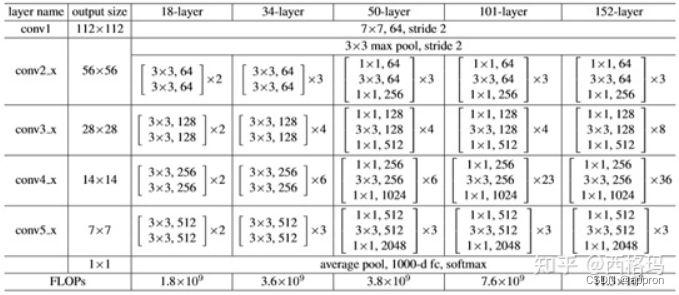
googlenet:Alex net+inception=conv*1+inception*9+FC*1 Resnet 提出背景:alexNet虽然效果好,但是没有给出深度神经网络的设计方向。即,如何把网络做到更深。 Resnet从避免梯度消失或爆炸的角度,使用残差连接结构使网络可以更深,共5个版本
|

【本文地址】
今日新闻 |
推荐新闻 |