物联网信息处理技术IPT(数据挖掘)第一章 |
您所在的位置:网站首页 › reduction翻译 › 物联网信息处理技术IPT(数据挖掘)第一章 |
物联网信息处理技术IPT(数据挖掘)第一章
|
目录 1.1 Data &its Characteristics数据及其特征 Data Objects and Attribute Types测量数据相似性和不相似性 Basic Statistical Descriptions of Data数据的基本统计描述 记录点1:倾斜数据 记录点2:四分五值、箱线图 Measuring Data Similarity and Dissimilarity测量数据的相似性和差异性 记录点3:非相似性矩阵 记录点4:计算二元变量间的不相似性,p=q+r+s+t 记录点5:特殊的闵可夫斯基——曼哈顿、欧式、切比雪夫 记录点6:不相似矩阵归一化 1.2 Data Preprocessing数据预处理 Why Preprocess the Data?为什么要预处理数据? Major Tasks in Data Preprocessing数据预处理中的主要任务 Data cleaning数据清洗 记录点7:处理有噪声的数据 记录点8:让数据平滑的简单方法:面平滑/边界平滑 Data integration数据集成 Data reduction数据简化 记录点9:三种新属性创建方法 记录点10:取样类型 Data transformation数据转换 记录点11:数据转换的3种方法 1.1 Data &its Characteristics数据及其特征 Data Objects and Attribute Types测量数据相似性和不相似性
接下来要讲的
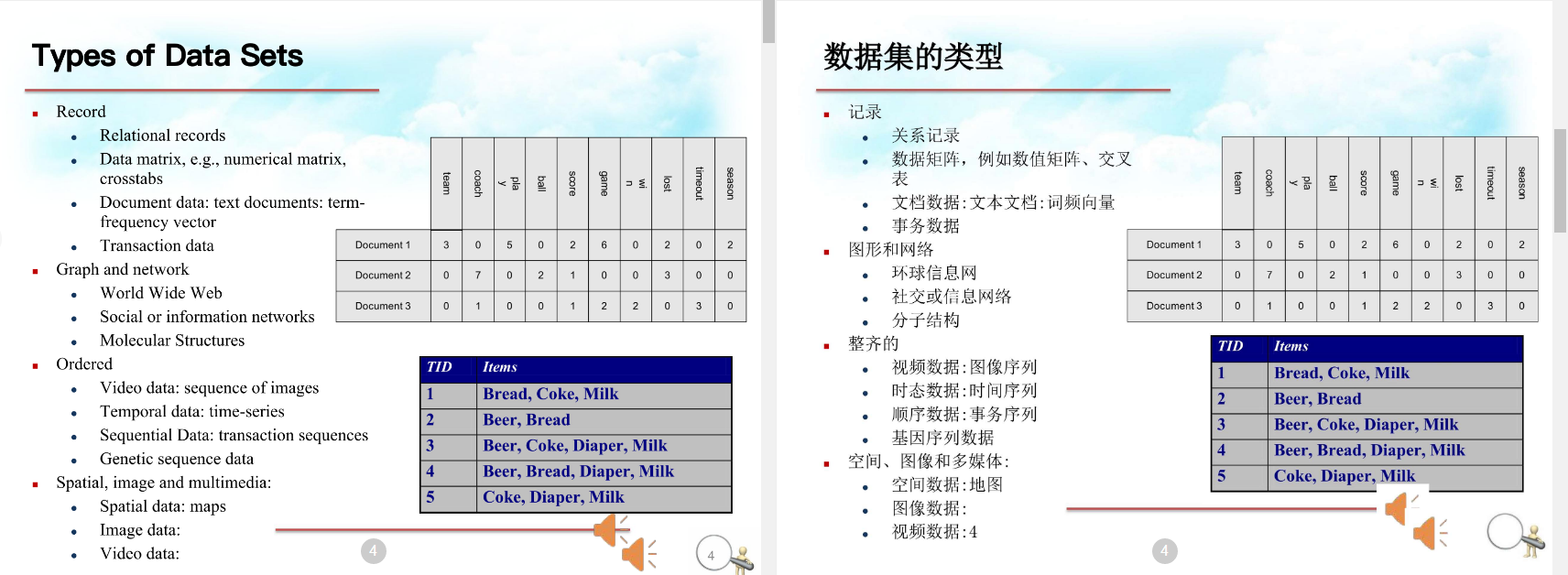
右上角是text documents类型。三个文档就有三个向量 右下角是transaction data,一种交易类型的数据结构,每一行是一条交易记录 左边没有图示的直接看文字
属性就是数据库中的列,这块有点像数据库 这几种type后面会介绍
数字属性类型:前者代表“日期”(没有绝对零点),后者代表“温度” Basic Statistical Descriptions of Data数据的基本统计描述
了解数据的集合的一些特征
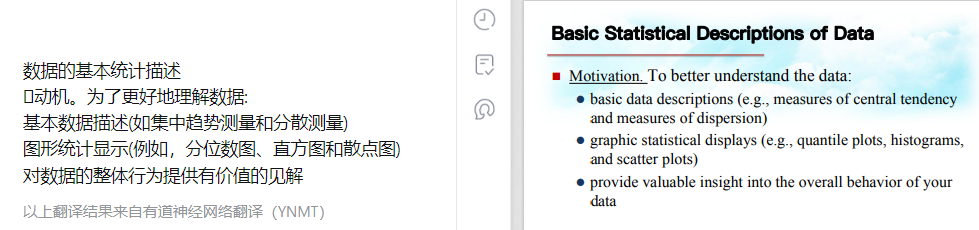
翻译不太对,应该是:平均值、中值(公式是中值的估算方法)、众数
由最高点开始到缓坡,众中均 记录点1:倾斜数据
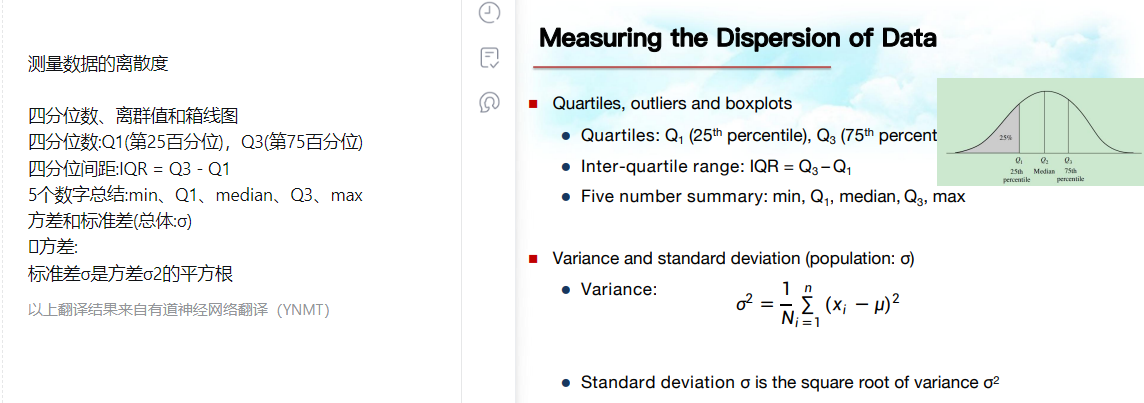
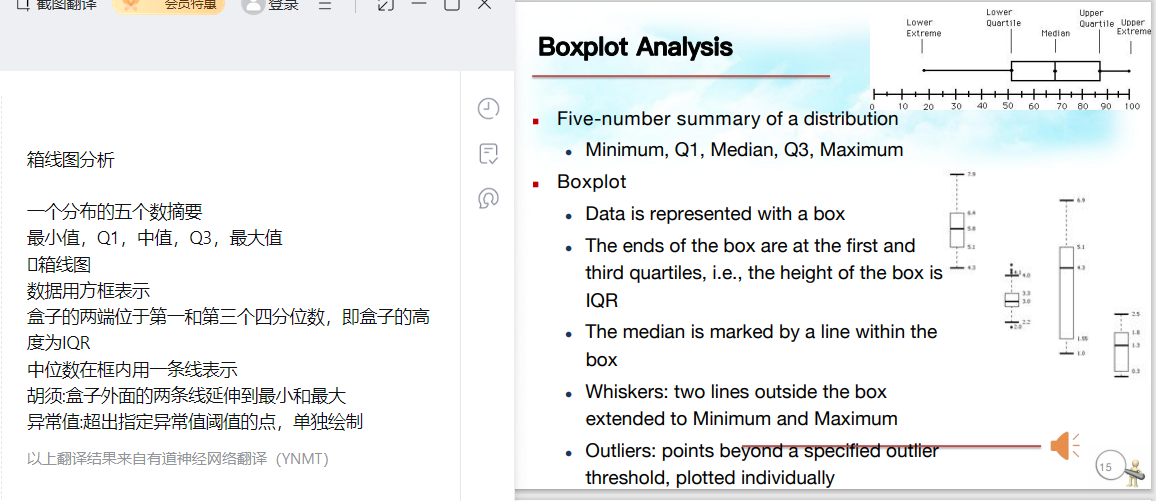
四分位数:Q1 Q3 IQR 五值:Q1Q3和中众均
这里的5值就是上面的5值
这图不是很懂,箱线图的理解 记录点2:四分五值、箱线图
小卖铺的资料显示这里有个“测量数据的分散性”是重点,但老师好像没讲
Measuring Data Similarity and Dissimilarity测量数据的相似性和差异性
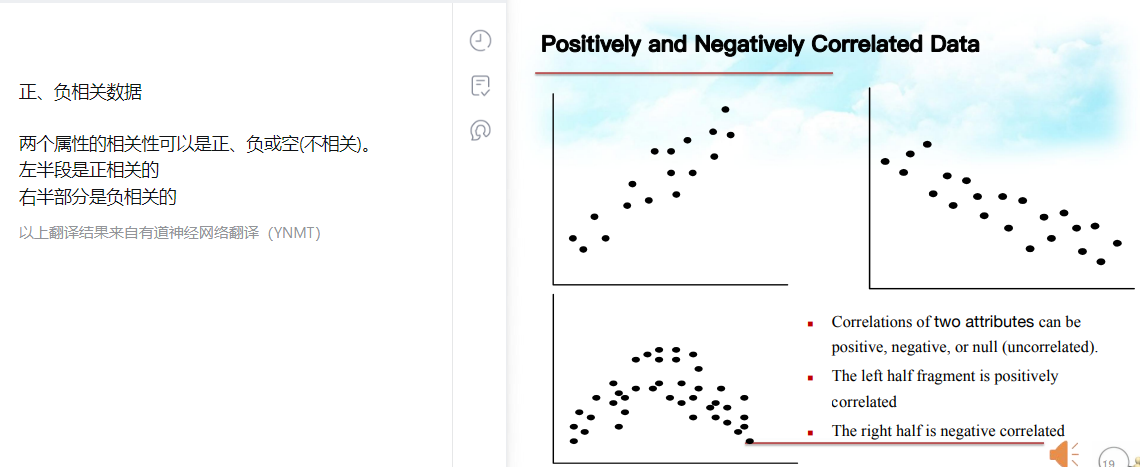
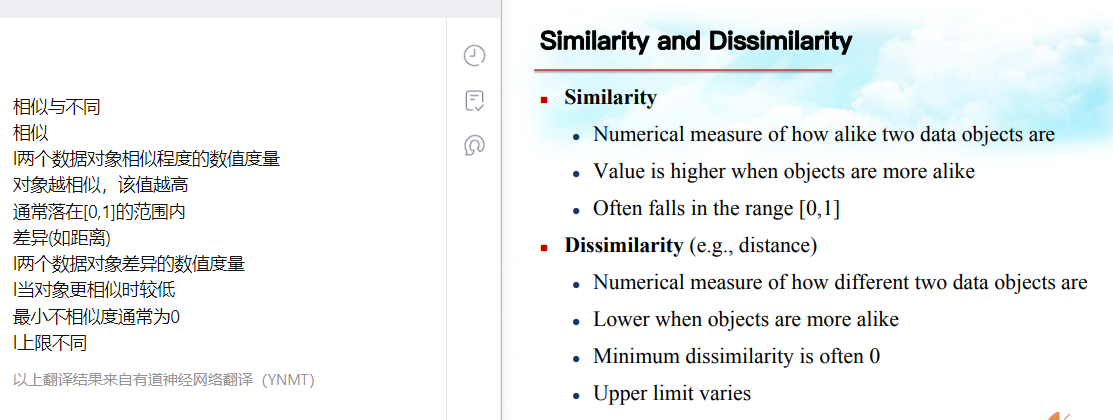
相似度和相异度正相反
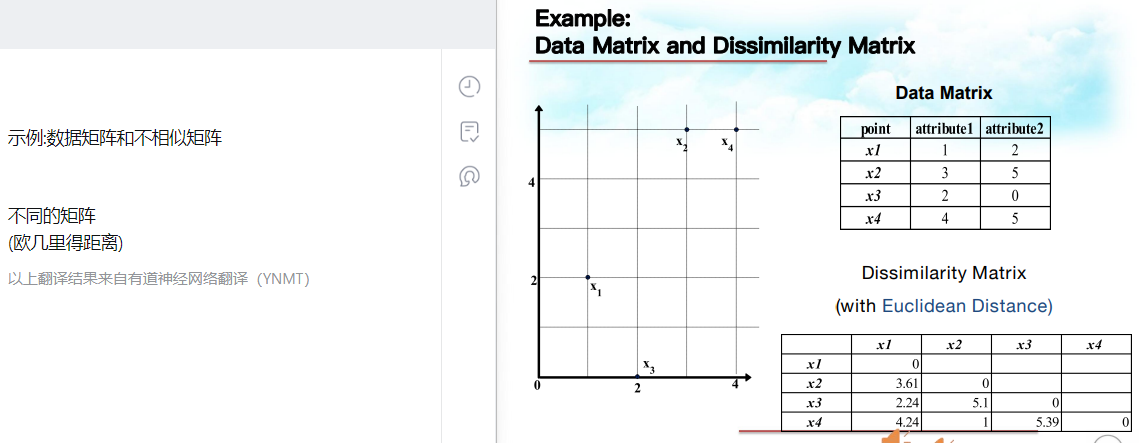
右下角是两个点在左图的距离,欧式距离,就是最常见的简单距离,比如x1和x3之间的欧式距离就是√(1^2+2^2) 记录点3:非相似性矩阵
接下来就是d的各种算法 p-m就是没匹配上的数量(吧) 只有一个nominal,就是只有一个变量(我的理解是只有一个属性)所以p值是1 至于m的值,1号和2号的code分别是A和B,它俩没匹配上,所以是0,根据公式得d值为1
前一张图是一维,上面这张讲的是二维,就是两个属性的时候该怎么算 有t的公式是对称性的,没有的是非对称的。T的含义是对于非对称都是0 的数去掉,因为不重要的值为0
这个计算过程看如下草稿1,很简单的跳转草稿 记录点4:计算二元变量间的不相似性,p=q+r+s+t
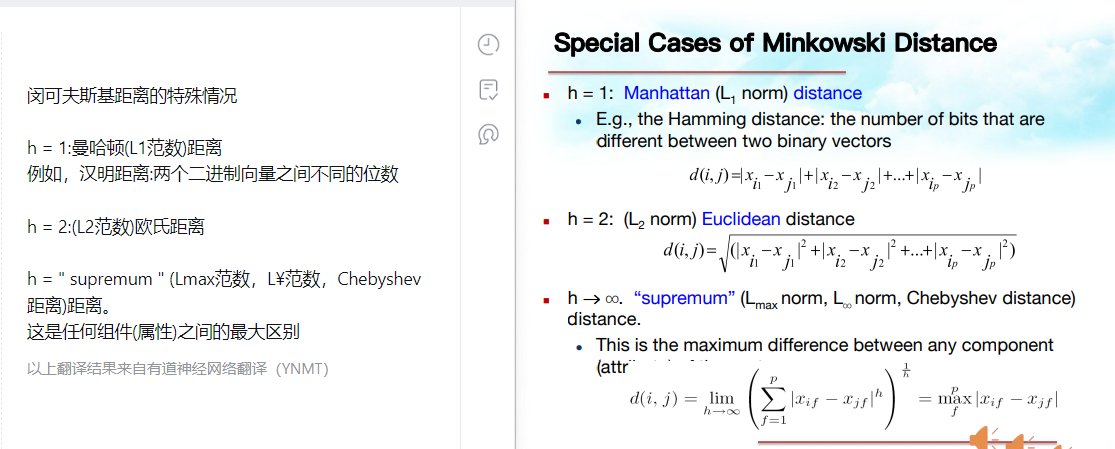
这个d是刚刚的d吗?不太像,刚刚是相似度的d,这个是闵可夫斯基的d 注意这3个闵可夫斯基的d的属性
闵可夫斯基的d的计算方法由h不同可以有不同算法/叫法 曼哈顿距离、欧式距离,最后一个:切比雪夫距离 记录点5:特殊的闵可夫斯基——曼哈顿、欧式、切比雪夫
曼哈顿距离->欧式距离->切比雪夫距离 这个计算过程看草稿2,跳转草稿
看不懂,看下面的例子
就是算出矩阵后,让最大数乘以k得1,其它所有数也乘以k 欧几里得距离,好像就是欧式距离 记录点6:不相似矩阵归一化
这就是个总结
1.2 Data Preprocessing数据预处理
数据减少,不是数据整理,翻译有误 这个排版有点问题,因为数据预处理的主要任务就是:数据清理、数据集成、数据减少、数据转换 Why Preprocess the Data?为什么要预处理数据?
最后那个1月1的意思是,如果你的生日是1月1,那么可能你只是选择了默认值而不是真正的在这天生日
有的数据不重要就不用浪费时间处理 如何处理缺失数据:丢掉、手动填补(直觉填)、自动填补(公式填)
例子如下
看PPT里的数字就能看懂,这里三个模块,顺序是:一-》二或者一->三 那个一->三的4 8 9 15 换成4 4 4 15,就是把数字换成距离更近的最值,9离4比9离15近,9就变4 记录点8:让数据平滑的简单方法:面平滑/边界平滑 Data integration数据集成
“对于同一个现实世界的实体,不同来源的属性值是不同的”的意思是同样是描述速度,可能因为用的单位不同,所以数据差别大
派生数据那个例子,意思是年收入可以通过月收入累加得到,不需要重新统计 Data reduction数据简化
翻译的问题,是数据减少,不是数据整理,也可以翻译为数据简化
数据简化,是为了提高数据挖掘的效率
第一个是数据降维 还有一个是去掉对任务没帮助的数据 我没搞懂这三个数据简化方法的区别,问问ChatGPT
问了也不懂
启发式属性选择方法 就是选属性,由最好最相关的属性开始选
信息融合 记录点9:三种新属性创建方法
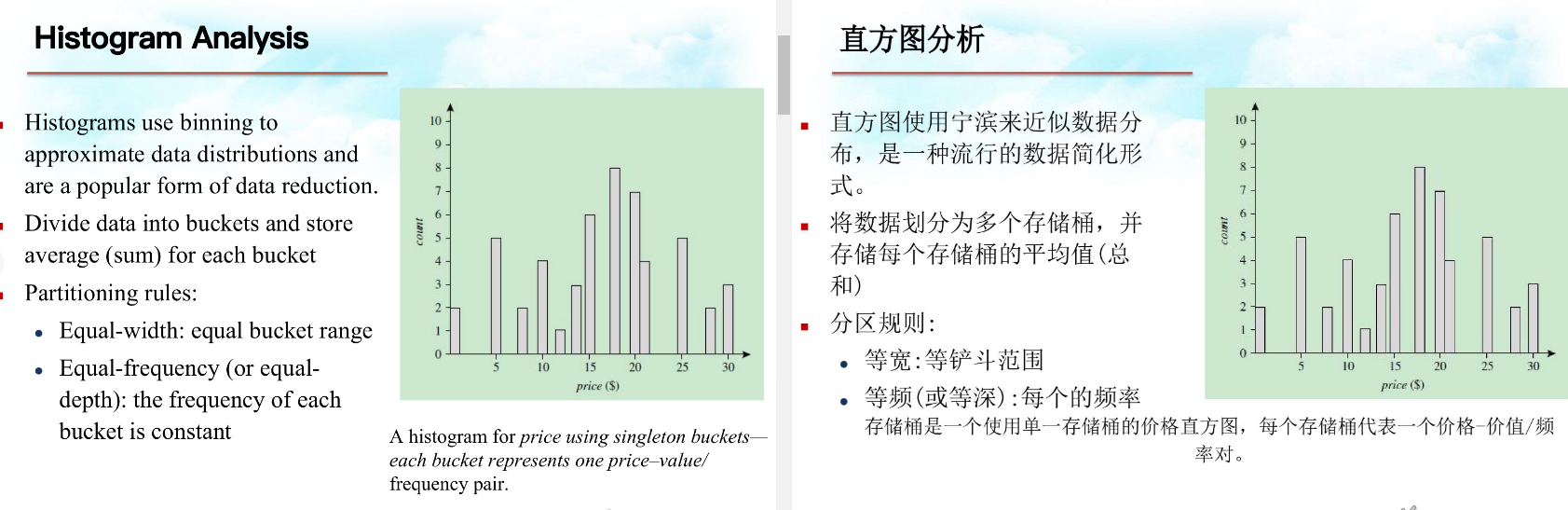
降低数据体积 翻译的内容和排版都怪怪的,non-parametric是无参数方法 参数方法就是用数据做出公式,做完了就丢掉数据,只留下公式 无参数方法就是都记下来,但是会做成表格图表
分组后,用每组的中心值代表这组数据
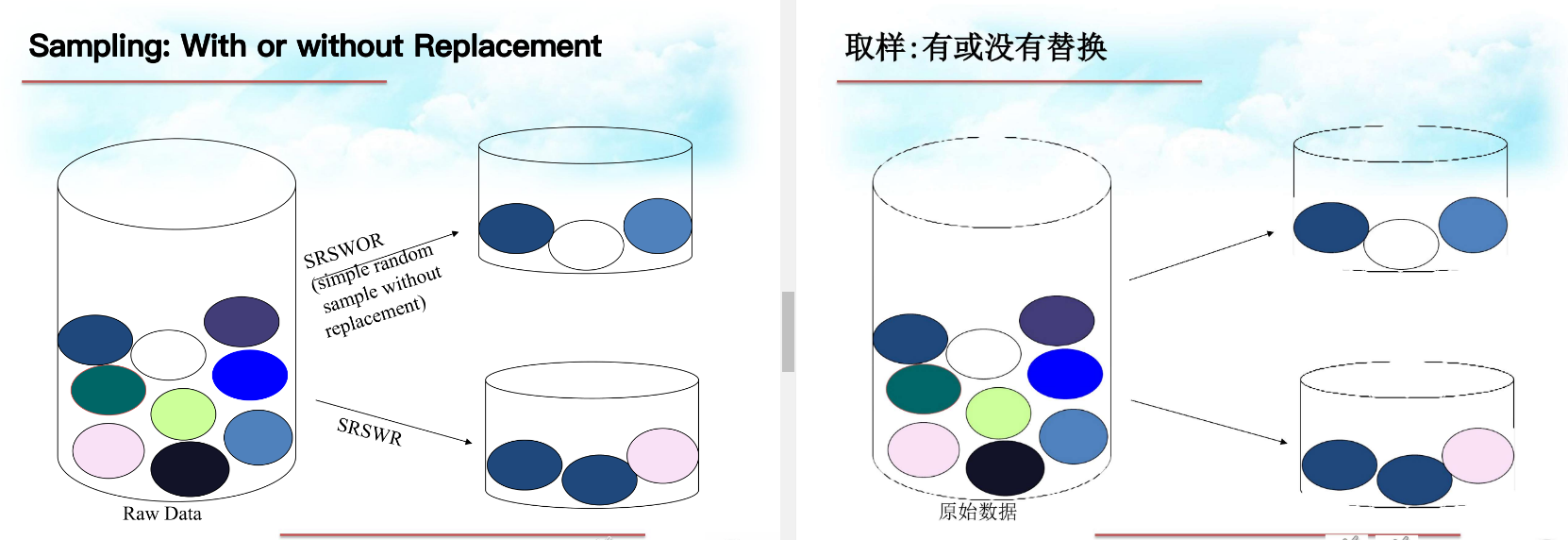
随机采样、分层采样(就是高中遇到的周期采样)
Without就是取完样之后还把抽到的数据放回去了 分层可以是随机打乱后分组,从每组选一个 Data transformation数据转换
第三个转换数据的方法是要用数据集里的max算出满足条件的j值,然后根据j值改变其余数据
这个计算方法不在上面三个数据转换方法里,只是上面三个数据转换方法中的第二个方法Z-score的延申计算方法,有点像计算平均值,但是把数值加在一起后不除以数据的数量,而是随机选一个n来除以 |











 两个对比是这样的,左边的分母p就是右边q+r+s+t,意思是左p-m=右q+t=右两个属性一样
两个对比是这样的,左边的分母p就是右边q+r+s+t,意思是左p-m=右q+t=右两个属性一样
































【本文地址】
今日新闻 |
推荐新闻 |