一个可持久化的大容量 Redis 存储服务Pika |
您所在的位置:网站首页 › redis内存扩容 › 一个可持久化的大容量 Redis 存储服务Pika |
一个可持久化的大容量 Redis 存储服务Pika
|
一、Pika简介 Pika 是一个可持久化的大容量 Redis 存储服务,兼容 string、hash、list、zset、set 的绝大部分接口,解决 Redis 由于存储数据量巨大而导致内存不够用的容量瓶颈,并且可以像 Redis一样,通过 slaveof 命令进行主从备份,支持全同步和部分同步,Pika 还可以用在 twemproxy 或者 codis 中来实现静态数据分片。 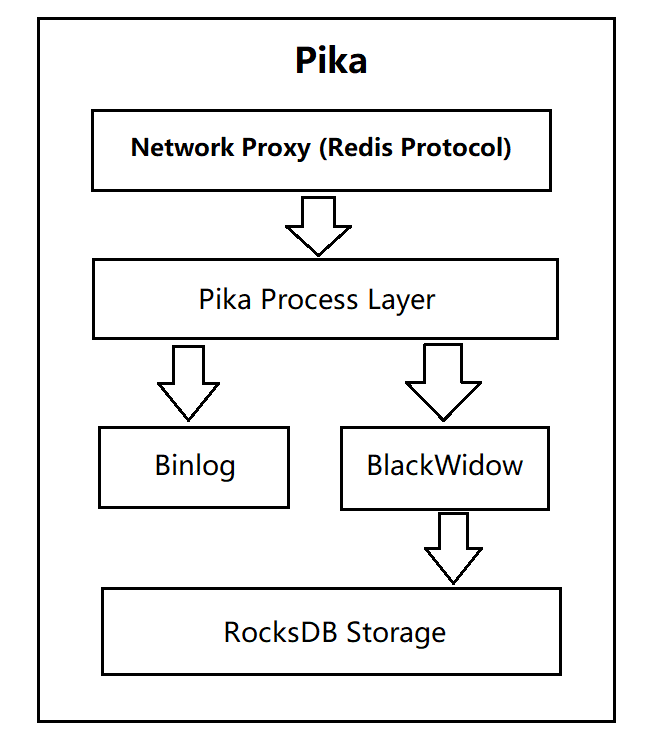 pika pikapika是一个类redis数据库:实现了redis协议,底层数据存储使用rocksdb。 实现一个类redis数据库的原因是因为内存数据库的缺陷: 重启需要加载所有的数据,这个过程非常的慢。redis的主从复制,当内存中存在非常大的数据时(比如50G),全量复制会占用整个内网的带宽,影响主数据库的性能。优势: pika可以达到redis的80%的性能,前提是少用list。 二、特点 容量大,支持百G数据量的存储。兼容 Redis ,不用修改代码即可平滑从 Redis 迁移到 Pika 。支持主从 (slaveof) 。完善的运维命令。使用pika的场景:项目非常依赖redis,而内存又不够用,大数据量容易出现问题,那么可以将redis迁移到pika;目前在腾讯、京东、微博等都有使用。三、Pika 安装编译centos: # 安装必要的 lib sudo yum install gflags-devel snappy-devel glogdevel protobuf-devel sudo yum install gcc-c++ # 安装可选的 lib sudo yum install zlib-devel lz4-devel libzstddevel # 确保 gcc 在4.8或者以上 # 获取源代码 git clone https://github.com/OpenAtomFoundation/pika.git cd pika git submodule update --init git checkout -b v3.4.0 makeubuntu: # 安装必要的 lib sudo apt-get install libgflags-dev libsnappy-dev sudo apt-get install libprotobuf-dev protobufcompiler sudo apt install libgoogle-glog-dev # 确保 gcc 在4。8或者以上 # 获取源代码 git clone https://github.com/OpenAtomFoundation/pika.git cd pika git submodule update --init git checkout -b v3.4.0 make使用: ./output/bin/pika -c ./conf/pika.conf四、BlackwidowBlackwidow 本质上是基于 RocksDB 的封装,使本身只支持 kv存储的 RocksDB 能够支持多种数据结构,目前 Blackwidow 支持五种数据结构的存储: string 结构(实际上就是存储 key,value)。hash 结构。list 结构。set 结构。zset 结构。因为 RocksDB 的存储方式只有 kv 一种, 所以上述五种数据结构最终都要落盘到 RocksDB 的 kv 存储方式上,下面展示Blackwidow 和 RocksDB 的关系并且说明是如何用 kv 来模拟多数据结构的。 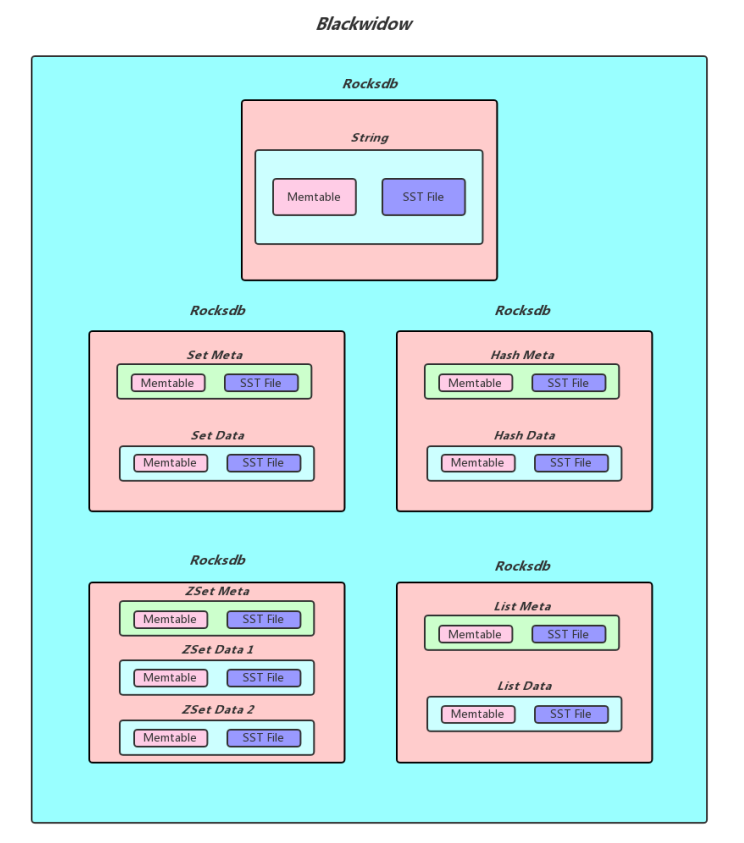 blackwidow blackwidow实现: redis的对象类型对应着 db;因为db可以单独配置。key和value分离存储,分别对应着列族;因为列族也可以单独配置。4.1、string 结构的存储String 本质上就是 Key,Value,我们知道 RocksDB 本身就是支持 kv 存储的,为了实现 Redis 中的 expire 功能,所以在value 后面添加了 4 Bytes 用于存储 timestamp,作为最后RocksDB 落盘的 kv 格式,下面是具体的实现方式:  timestamp不放在key后面的原因:如果timestamp和key放在一起,那么每次都要把整个key提取出来然后截取前面的字段进行判断是否是目标key。 如果我们没有对该 String 对象设置超时时间,则 timestamp 存储的值就是默认值 0, 否则就是该对象过期时间的时间戳, 每次我们获取一个 String 对象的时候, 首先会解析 Value 部分的后四字节, 获取到timestamp 做出判断之后再返回结果。 4.2、Hash 结构的存储Blackwidow 中的 Hash 表由两部分构成,元数据(meta_key,meta_value) ,和普通数据 (data_key,data_value),元数据中存储的主要是 Hash 表的一些信息,比如说当前 Hash 表的域的数量以及当前 hash 表的版本号和过期时间(用做秒删功能),而普通数据主要就是指的同一个Hash 表中一一对应的 field 和value,作为具体最后 RocksDB落盘的 kv 格式,下面是具体的实现方式: (1)每个 Hash 表的 meta_key 和 meta_value 的落盘方式:  meta_key 实际上就是 hash 表的 key,而 meta_value 由三个部分构成:4Bytes 的 Hash size (用于存储当前hash表的大小) + 4Bytes 的 Version (用于秒删功能) + 4Bytes 的 Timestamp (用于记录我们给这个Hash 表设置的超时时间的时间戳, 默认为0)。 (2) Hash 表中 data_key 和 data_value 的落盘方式:  data_key由四个部分构成:4Bytes 的 Key size (用于记录后面追加的key的长度,便与解析) + key的内容 + 4Bytes 的 Version + Field 的内容, 而 data_value 就是 Hash 表某个 field 对应的 value。 如果我们需要查找一个 Hash 表中的某一个 field 对应的value,我们首先会获取到 meta_value 解析出其中的timestamp 判断这个 hash 表是否过期, 如果没有过期, 我们可以拿到其中的 version,然后我们使用key,version,和field 拼出 data_key,进而找到对应的 data_value(如果存在的话)。 (3)Hash结构不需要timestamp的原因:timestamp是为了实现expire,只能对结构的key有效,不能作用于单个节点(value)expire。 4.3、List 结构的存储Blackwidow 中的 List 由两部分构成,元数据(meta_key,meta_value),和普通数据(data_key,data_value),元数据中存储的主要是 List 链表的一些信息, 比如说当前 List 链表结点的的数量以及当前 List 链表的版本号和过期时间(用做秒删功能),还有当前 List 链表的左右边界(由于 nemo 实现的链表结构被吐槽 lrange 效率低下,所以 Blackwidow 底层用数组来模拟链表,这样 lrange 速度会大大提升,因为结点存储都是有序的),普通数据实际上就是指的list中每一个结点中的数据,作为具体最后 RocksDB 落盘的 kv 格式,下面是具体的实现方式: (1)每个 List 链表的 meta_key 和 meta_value 的落盘方式:  meta_key实际上就是 List 链表的 key,而 meta_value 由五个部分构成: 8Bytes 的 List size(用于存储当前链表中总共有多少个结点) + 4Bytes 的 Version (用于秒删功能) + 4Bytes 的 Timestamp (用于记录我们给这个List链表设置的超时时间的时间戳, 默认为0) + 8Bytes 的 Left Index (数组的左边界) + 8Bytes 的Right Index (数组的右边界)。 (2)List 链表中 data_key 和 data_value 的落盘方式:  data_key由四个部分构成:4Bytes 的 Key size (用于记录后面追加的 key 的长度,便与解析) + key 的内容 + 4Bytes 的 Version + 8Bytes 的 Index (这个记录的就是当前结点的在这个 List 链表中的索引), 而data_value 就是 List 链表该 node 中存储的值。 存在两个version的原因:不仅可能对整个key删除,也可能需要删除某一个节点。 4.4、Set 结构的存储Blackwidow 中的 Set 由两部分构成,元数据 (meta_key, meta_value),和普通数据 (data_key,data_value),元数据中存储的主要是 Set 集合的一些信息, 比如说当前 Set 集合member 的数量以及当前 Set 集合的版本号和过期时间(用做秒删功能),普通数据实际上就是指的 Set 集合中的member,作为具体最后 RocksDB 落盘的 kv 格式,下面是具体的实现方式: (1)每个 Set 集合的 meta_key 和 meta_value 的落盘方式:  meta_key 实际上就是 Set 集合的 key,而 meta_value 由三个部分构成:4Bytes 的 Set size(用于存储当前 Set 集合的大小) + 4Bytes 的 Version(用于秒删功能) + 4Bytes 的Timestamp(用于记录我们给这个 Set 集合设置的超时时间的时间戳, 默认为0)。 (2) Set 集合中 data_key 和 data_value 的落盘方式:  data_key 由四个部分构成:4Bytes 的 Key size(用于记录后面追加的 key 的长度,便与解析) + key 的内容 + 4Bytes 的 Version + member 的内容,由于 Set 集合只需要存储member,所以 data_value 实际上就是空串。 因为set结构不要求数据有序,所以不需要index。 4.5、ZSet 结构的存储Blackwidow中 的 ZSet 由两部部分构成,元数据(meta_key,meta_value),和普通数据(data_key,data_value),元数据中存储的主要是 ZSet 集合的一些信息, 比如说当前 ZSet 集合 member 的数量以及当前 ZSet 集合的版本号和过期时间(用做秒删功能),而普通数据就是指的 ZSet 中每个 member以及对应的 score,由于 ZSet 这种数据结构比较特殊,需要按照 member 进行排序,也需要按照 score 进行排序, 所以我们对于每一个 ZSet 我们会按照不同的格式存储两份普通数据,在这里我们称为 member to score 和score to member,作为具体最后 RocksDB 落盘的 kv 格式,下面是具体的实现方式: (1)每个 ZSet 集合的 meta_key 和 meta_value 的落盘方式:  meta_key 实际上就是 ZSet 集合的 key,而 meta_value 由三个部分构成:4Bytes 的 ZSet size(用于存储当前zSet集合的大小) + 4Bytes 的 Version (用于秒删功能) + 4Bytes的 Timestamp (用于记录我们给这个Zset 集合设置的超时时间的时间戳, 默认为0)。 (2)每个 ZSet 集合的 data_key 和 data_value 的落盘方式(member to score):  member to socre的 data_key由四个部分构成:4Bytes 的Key size (用于记录后面追加的 key 的长度,便与解析) + key 的内容 + 4Bytes的 Version + member 的内容,data_value 中存储的其 member 对应的 score 的值,大小为 8 个字节,由于 RocksDB 默认是按照字典序进行排列的,所以同一个zset中不同的 member 就是按照 member的字典序来排列的 (同一个 ZSet 的 key size,key,以及version,也就是前缀都是一致的,不同的只有末端的member)。 (3) 每个 ZSet 集合的 data_key 和 data_value的落盘方式(score to member): 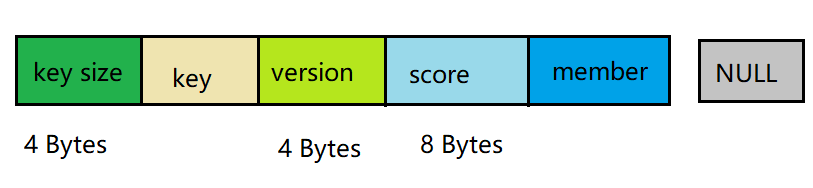 score to member 的 data_key 由五个部分构成:4Bytes 的Key size(用于记录后面追加的 key 的长度,便与解析) + key 的内容 + 4Bytes 的 Version + 8Bytes 的 Score + member 的内容, 由于 score 和 member 都已经放在data_key 中进行存储了所以 data_value 就是一个空串,无需存储其他内容了,对于 score to member中 的 data_key我们自己实现了 RocksDB 的 comparetor,同一个 ZSet 中score to member 的 data_key 会首先按照 score 来排序,在 score 相同的情况下再按照 member 来排序。  后言 后言本专栏知识点是通过的系统学习,进行梳理总结写下文章,对c/c++linux系统提升感兴趣的读者,可以点击链接查看详细的服务:C/C++服务器开发。 |
【本文地址】
今日新闻 |
推荐新闻 |