Redis数据结构:Zset类型全面解析 |
您所在的位置:网站首页 › redis中zset做差集的效率 › Redis数据结构:Zset类型全面解析 |
Redis数据结构:Zset类型全面解析
|
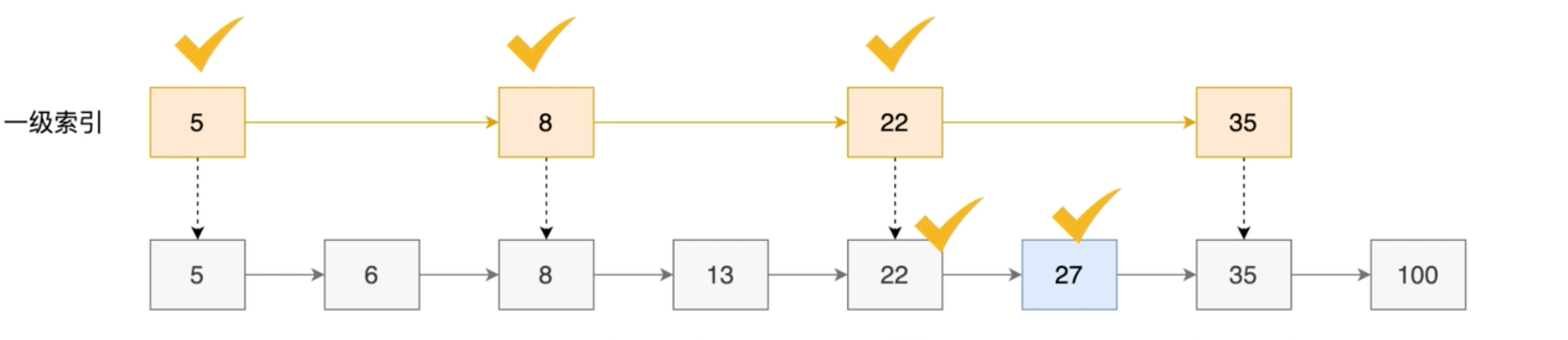
Redis,作为一种高性能的键值对数据库,因其丰富的数据类型和高效的性能而受到了广泛的关注和使用。在 Redis 的五种主要数据类型中,Zset(有序集合)类型可能是最复杂,但也是最强大的一种。Zset 不仅可以存储键值对,还可以为每个元素分配一个分数,然后根据这个分数进行排序。这使得 Zset 非常适合用于实现排行榜、时间线等功能。 在这篇文章中,我们将全面解析 Redis 的 Zset 类型。我们将从 Zset 的基本概念和特性开始,然后深入到它的内部实现和性能优化。我们还将通过实际的示例来展示如何在实际应用中使用 Zset。无论你是刚接触 Redis,还是已经有一定经验的开发者,我相信你都能从这篇文章中学到一些有用的知识。 文章目录 1、Zset数据类型1.1、Zset类型简介1.2、Zset应用场景 3、Zset底层结构3.1、Zset底层结构介绍3.2、压缩列表(ziplist)3.3、跳跃表(skiplist)3.4、Redis跳表与MySQLB+树 3、ZSet 常用命令2.1、添加操作2.2、返回指定成员分数2.3、返回指定成员排名2.4、其他Zset命令 1、Zset数据类型 1.1、Zset类型简介Zset,即有序集合(Sorted Set),是 Redis 提供的一种复杂数据类型。Zset 是 set 的升级版,它在 set 的基础上增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列。 在 Zset 中,集合元素的添加、删除和查找的时间复杂度都是 O(1)。这得益于 Redis 使用的是一种叫做跳跃列表(skiplist)的数据结构来实现 Zset。 Zset 的主要特性包括: 唯一性:和 set 类型一样,Zset 中的元素也是唯一的,也就是说,同一个元素在同一个 Zset 中只能出现一次。 排序:Zset 中的元素是有序的,它们按照 score 的值从小到大排列。如果多个元素有相同的 score,那么它们会按照字典序进行排序。 自动更新排序:当你修改 Zset 中的元素的 score 值时,元素的位置会自动按新的 score 值进行调整。 1.2、Zset应用场景Redis 的 Zset(有序集合)类型在许多场景中都非常有用,以下是一些常见的应用场景: 排行榜:Zset 非常适合用于实现各种排行榜。例如,你可以将用户的 ID 作为元素,用户的分数作为分数,然后使用 Zset 来存储和排序所有用户的分数。你可以很容易地获取到分数最高的用户,或者获取到任何用户的排名。 时间线:你可以使用 Zset 来实现时间线功能。例如,你可以将发布的消息作为元素,消息的发布时间作为分数,然后使用 Zset 来存储和排序所有的消息。你可以很容易地获取到最新的消息,或者获取到任何时间段内的消息。 带权重的队列:Zset 可以用于实现带权重的队列。例如,你可以将任务作为元素,任务的优先级作为分数,然后使用 Zset 来存储和排序所有的任务。你可以很容易地获取到优先级最高的任务,或者按优先级顺序执行任务。 延时队列:你可以将需要延时处理的任务作为元素,任务的执行时间作为分数,然后使用 Zset 来存储和排序所有的任务。你可以定期扫描 Zset,处理已经到达执行时间的任务。 以上只是 Zset 的一些常见应用场景,实际上,Zset 的应用非常广泛,只要是需要排序和排名功能的场景,都可以考虑使用 Zset。 3、Zset底层结构 3.1、Zset底层结构介绍Redis 的 Zset(有序集合)类型的底层实现会根据实际情况选择使用压缩列表(ziplist)或者跳跃表(skiplist)。Redis 会根据实际情况动态地在这两种底层结构之间切换,以在内存使用和性能之间找到一个平衡。 这主要取决于两个配置参数:zset-max-ziplist-entries 和 zset-max-ziplist-value。 使用压缩列表:当 Zset 存储的元素数量小于 zset-max-ziplist-entries 的值,且所有元素的最大长度小于 zset-max-ziplist-value 的值时,Redis 会选择使用压缩列表作为底层实现。压缩列表占用的内存较少,但是在需要修改数据时,可能需要对整个压缩列表进行重写,性能较低。 使用跳跃表:当 Zset 存储的元素数量超过 zset-max-ziplist-entries 的值,或者任何元素的长度超过 zset-max-ziplist-value 的值时,Redis 会将底层结构从压缩列表转换为跳跃表。跳跃表的查找和修改数据的性能较高,但是占用的内存也较多。 这两个参数都可以在 Redis 的配置文件中进行设置。通过调整这两个参数,你可以根据自己的应用特性,选择更倾向于节省内存,还是更倾向于提高性能。 3.2、压缩列表(ziplist)压缩列表是一种为节省内存而设计的特殊编码结构,它将所有的元素和分数紧凑地存储在一起。这种方式的优点是占用内存少,但是在需要修改数据时,可能需要对整个压缩列表进行重写,性能较低。当 Zset 存储的元素数量较少,且元素的字符串长度较短时,Redis 会选择使用压缩列表作为底层实现。 一个压缩列表的结构如下: +---------+---------+--------+---------+---------+---------+--------+ | zlbytes | zltail | zllen | entry_1 | entry_2 | ... | zlend | +---------+---------+--------+---------+---------+---------+--------+Ps:在 Redis 的源代码中,压缩列表(ziplist)的结构并没有直接定义为一个 C 结构体,而是通过一系列的宏和函数来操作一段连续的内存。 属性说明“zlbytes”一个 4 字节的整数,表示整个压缩列表占用的字节数量,包括 自身的大小。“zltail”一个 4 字节的整数,表示压缩列表中最后一个元素的偏移量。这个偏移量是相对于整个压缩列表的起始地址的。“zllen”一个 2 字节的整数,表示压缩列表中的元素数量。如果元素数量超过 65535,那么这个值就会被设定为 65535,需要遍历整个压缩列表才能获取到实际的元素数量。“entry”压缩列表中的元素,每个元素都由一个或多个字节组成。每个元素的第一个字节(又称为"entry header")用于表示这个元素的长度以及编码方式。“zlend”一个字节,值为 255,表示压缩列表的结束。在 Zset 中,每个元素和它的分数都会作为一个独立的元素存储在压缩列表中,元素和分数会交替存储,即第一个元素是成员,第二个元素是分数,第三个元素是成员,第四个元素是分数,以此类推。 压缩列表的优点是占用内存少,但是在需要修改数据时,可能需要对整个压缩列表进行重写,性能较低。 3.3、跳跃表(skiplist)跳跃表是一种可以进行快速查找的有序数据结构,它通过维护多级索引来实现快速查找。这种方式的优点是查找和修改数据的性能较高,但是占用的内存也较多。当 Zset 存储的元素数量较多,或者元素的字符串长度较长时,Redis 会选择使用跳跃表作为底层实现。 跳跃表(skiplist)是一种可以进行快速查找的有序数据结构,它通过维护多级索引来实现快速查找。 在 Redis 的源代码中,跳跃表的结构定义如下: typedef struct zskiplistNode { robj *obj; double score; struct zskiplistNode *backward; struct zskiplistLevel { struct zskiplistNode *forward; unsigned int span; } level[]; } zskiplistNode; typedef struct zskiplist { struct zskiplistNode *header, *tail; unsigned long length; int level; } zskiplist;其中: zskiplistNode 结构体表示跳跃表中的一个节点,包含元素对象(obj)、分数(score)、指向前一个节点的指针(backward)和一个包含多个层的数组(level)。每一层都包含一个指向下一个节点的指针(forward)和一个表示当前节点到下一个节点的跨度(span)。 zskiplist 结构体表示一个跳跃表,包含头节点(header)、尾节点(tail)、跳跃表中的节点数量(length)和当前跳跃表的最大层数(level)。 跳跃表的查找、插入和删除操作的时间复杂度都是 O(logN),其中 N 是跳跃表中的元素数量。这使得跳跃表在处理大量数据时具有很高的性能。 跳表在链表的基础上增加了多级索引,通过多级索引位置的专跳,实现了快速查找元素 比如下面,查找 27 ,需要遍历 6 次 一级索引(每间隔一个元素):
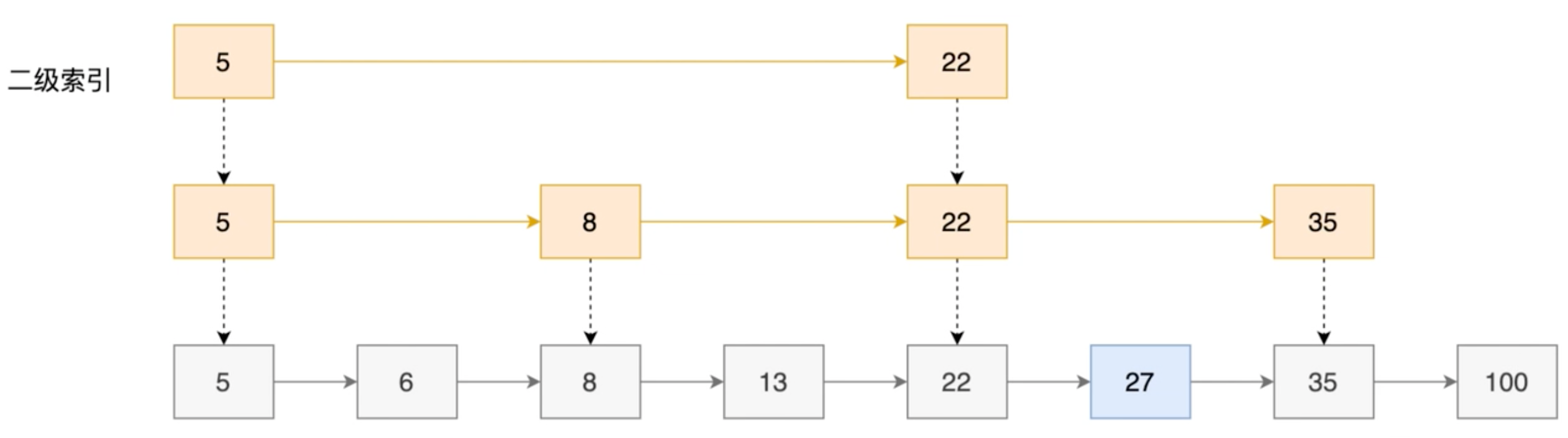
一次索引,遍历 5 个节点 二级索引(一次索引基础上,每间隔一个元素):
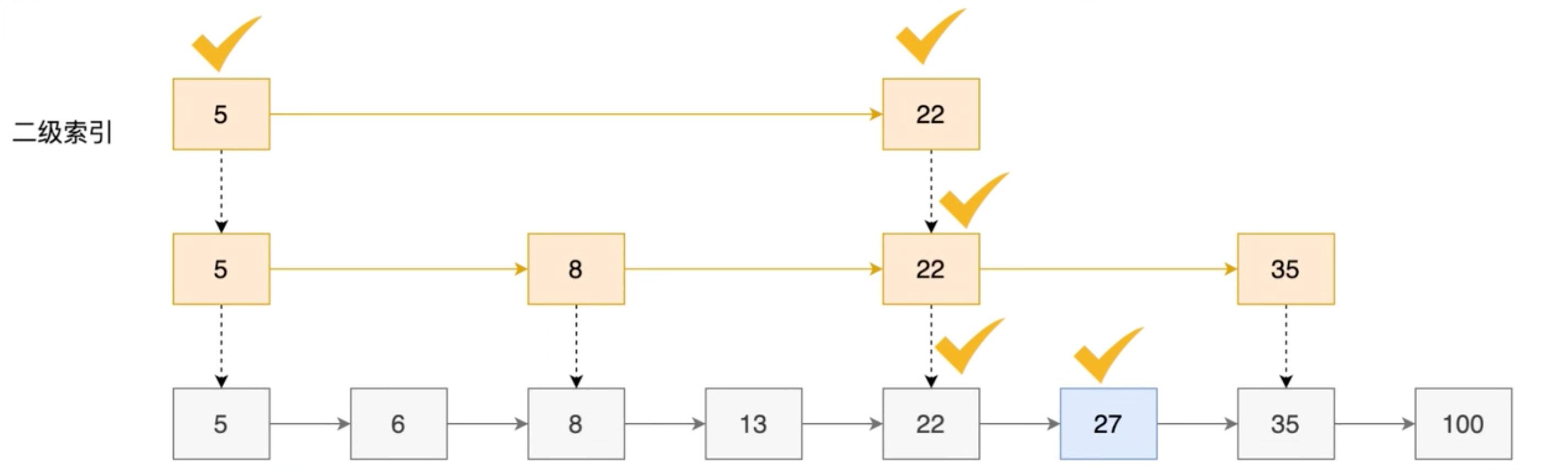
二索引,遍历 5 个节点
本身利用的思想类似于二分法 3.4、Redis跳表与MySQLB+树MySQL 的 B+ 树和 Redis 的跳表都是用于存储有序数据的数据结构,但它们有一些关键的区别,使得它们在不同的场景和用途中各有优势。 结构差异:B+ 树是一种多路搜索树,每个节点可以有多个子节点,而跳表是一种基于链表的数据结构,每个节点只有一个下一个节点,但可以有多个快速通道指向后面的节点。 空间利用率:B+ 树的磁盘读写操作是以页(通常是 4KB)为单位的,每个节点存储多个键值对,可以更好地利用磁盘空间,减少 I/O 操作。而跳表的空间利用率相对较低。 插入和删除操作:跳表的插入和删除操作相对简单,时间复杂度为 O(logN),并且不需要像 B+ 树那样进行复杂的节点分裂和合并操作。 范围查询:B+ 树的所有叶子节点形成了一个有序链表,因此非常适合进行范围查询。而跳表虽然也可以进行范围查询,但效率相对较低。 因此,B+ 树和跳表不能简单地相互替换。在需要大量进行磁盘 I/O 操作和范围查询的场景(如数据库索引)中,B+ 树可能是更好的选择。而在主要进行内存操作,且需要频繁进行插入和删除操作的场景(如 Redis)中,跳表可能更有优势。 Mysql 为什么使用 B +树,而不是跳表? Mysql 数据库是持久化数据库,即是存储到磁盘上的,因此查询时要求更少磁盘 IO,且 Mysql 是读多写少的场景较多,显然 B+ 树更加适合M ysql。 Redis 的 ZSet 为什么使用跳表而不是B+树 Redis 是内存存储,不存在 IO 的瓶颈,所以跳表的层数的耗时可以忽略不计,而且插入数据时不需要开销以平衡数据结构(写多)。 3、ZSet 常用命令 2.1、添加操作在 Redis 中,ZADD 命令用于向有序集合(Zset)中添加一个或多个成员,或者更新已存在成员的分数。它的基本语法如下: ZADD key score member [score member ...]其中,key 是有序集合的名称,score 是成员的分数,member 是成员的值。你可以一次添加一个或多个成员。 例如,你可以使用以下命令向名为 myzset 的有序集合中添加一个成员 one,其分数为 1: ZADD myzset 1 one如果你想要一次添加多个成员,可以在命令后面依次列出它们的分数和值,例如: ZADD myzset 1 one 2 two 3 three这个命令会向 myzset 集合中添加三个成员,它们的分数分别为 1、2 和 3。 如果添加的成员在有序集合中已经存在,那么它的分数会被更新为新的值,同时该成员在集合中的位置也会相应地发生变化。 2.2、返回指定成员分数在 Redis 中,ZSCORE 命令用于返回有序集合(Zset)中,指定成员的分数。它的基本语法如下: ZSCORE key member其中,key 是有序集合的名称,member 是要查询分数的成员。 例如,你可以使用以下命令查询名为 myzset 的有序集合中,成员 one 的分数: ZSCORE myzset one如果指定的成员存在于有序集合中,那么命令会返回该成员的分数。如果指定的成员不存在于有序集合中,那么命令会返回 nil。 需要注意的是,ZSCORE 命令返回的分数是字符串形式的浮点数。 2.3、返回指定成员排名在 Redis 中,ZRANK 命令用于返回有序集合(Zset)中指定成员的排名,其中分数值从低到高排序。它的基本语法如下: ZRANK key member其中,key 是有序集合的名称,member 是要查询排名的成员。 例如,你可以使用以下命令查询名为 myzset 的有序集合中,成员 one 的排名: ZRANK myzset one如果指定的成员存在于有序集合中,那么命令会返回该成员的排名。排名以 0 为底,也就是说,分数最低的成员排名为 0。 如果指定的成员不存在于有序集合中,那么命令会返回 nil。 需要注意的是,ZRANK 命令返回的排名是字符串形式的整数。 2.4、其他Zset命令Redis 中 Zset 其他的一些常用命令还有: ZREVRANK key member:返回有序集合中指定成员的索引,分数值从高到低排序。 ZRANGE key start stop [WITHSCORES]:返回有序集中,指定区间内的成员。 ZREVRANGE key start stop [WITHSCORES]:返回有序集中,指定区间内的成员,通过索引,分数值从高到低。 ZREM key member [member …]:移除有序集合中的一个或多个成员。 ZCARD key:获取有序集合的成员数。 ZCOUNT key min max:计算在有序集合中指定区间分数的成员数。 ZINCRBY key increment member:为有序集合中的成员添加增量。 以上只是 Zse 其他 Hash 命令的一些常用命令,更多的命令和详细的使用方法,可以查阅 Redis 的官方文档。 |

【本文地址】