[ICLR'23 简读] Encoding Recurrence into Transformers |
您所在的位置:网站首页 › recurrence是什么意思 › [ICLR'23 简读] Encoding Recurrence into Transformers |
[ICLR'23 简读] Encoding Recurrence into Transformers
|
TL;DR 方法:基本上是element-wise linear recurrence (类似于s4d, linear diagonal rnn等. sonta:RNN最简单有效的形式是什么?) 和attention这两个token mixing方法的线性组合 实验非常solid。(吐槽: 我感觉非要把recurrence写成Multihead attention的形式过于强行。非要这么硬套的话,所有的linear的token mixing都能这么写。下一篇名字我已经起好了:Encoding Convolution into Transformers) 动机为什么要结合attention和recurrence? 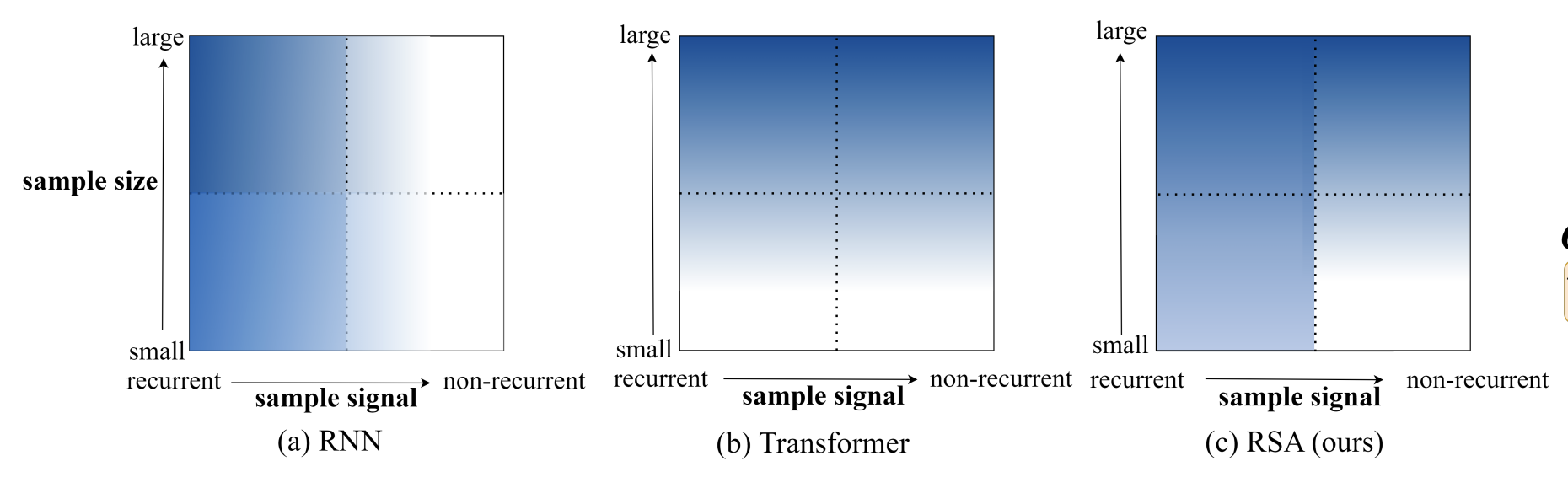 颜色越深表现越好Transformer sample inefficiency(需要喂大量数据)。 在recurrent的场景下除非数据量很大,否则很可能不如RNN(如很多时间序列分析任务)RNN 在nonrecurrent的场景下效果不好。 方法 颜色越深表现越好Transformer sample inefficiency(需要喂大量数据)。 在recurrent的场景下除非数据量很大,否则很可能不如RNN(如很多时间序列分析任务)RNN 在nonrecurrent的场景下效果不好。 方法 我感觉不太surprising 我感觉不太surprising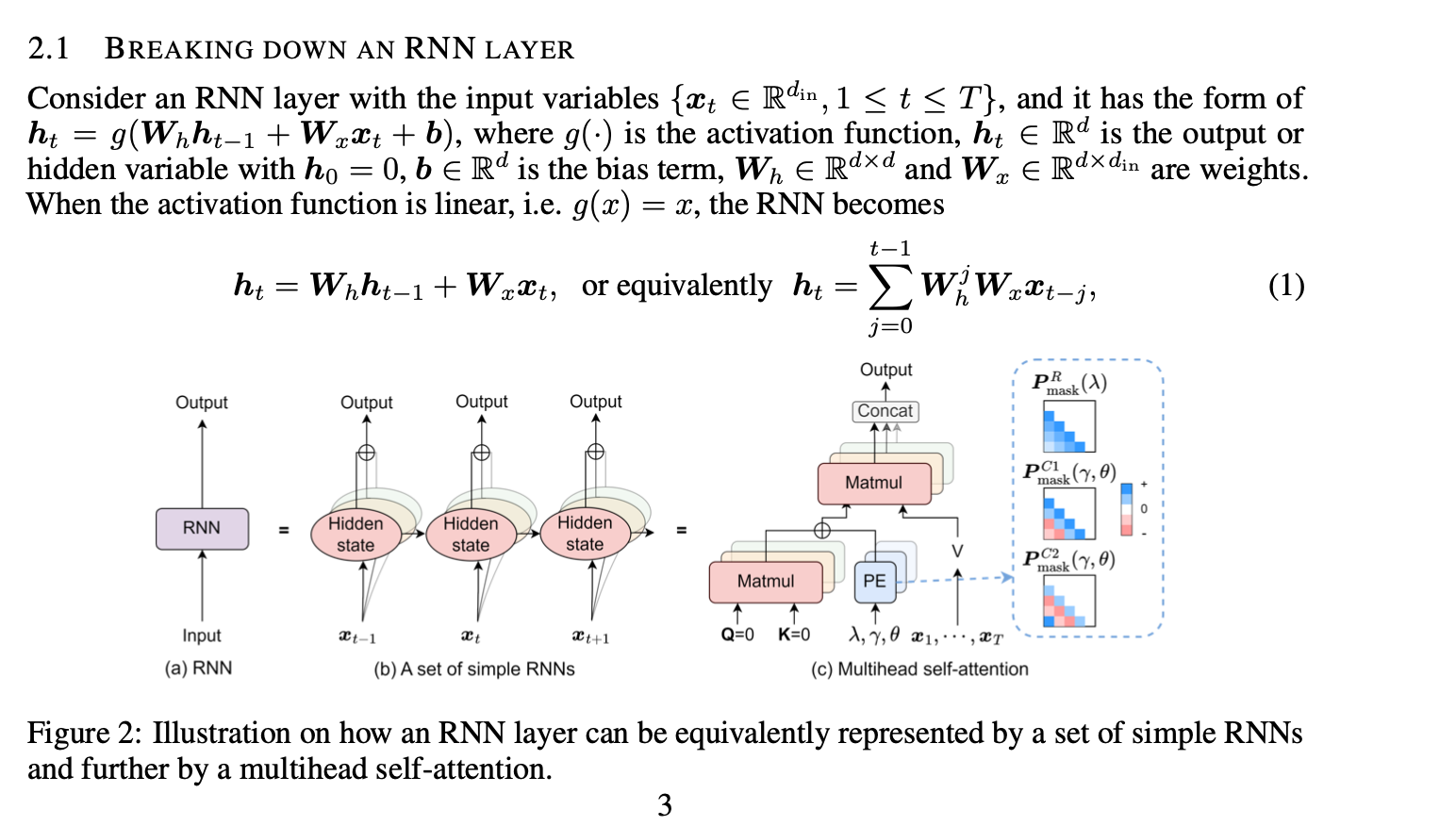 每个维度都独立的RNN。跟https://zhuanlan.zhihu.com/p/616357772这个系列一样 每个维度都独立的RNN。跟https://zhuanlan.zhihu.com/p/616357772这个系列一样 考虑了复数 https://hazyresearch.stanford.edu/blog/2022-06-11-simplifying-s4#2b 考虑了复数 https://hazyresearch.stanford.edu/blog/2022-06-11-simplifying-s4#2b (1)这里是把循环展开了,写成了o(n^2)的形式(2)下面那个说把rnn表示成SA的形式我感觉是错的,softmax(QK')就算Q K‘是0, 算出来也是均匀分布, 有点迷惑, 感觉得在P_mask上面减掉这个term来fix一下? (1)这里是把循环展开了,写成了o(n^2)的形式(2)下面那个说把rnn表示成SA的形式我感觉是错的,softmax(QK')就算Q K‘是0, 算出来也是均匀分布, 有点迷惑, 感觉得在P_mask上面减掉这个term来fix一下? 最后的模型就是attention和recurrence线性加权 最后的模型就是attention和recurrence线性加权 dilated rnn,有点意思,感觉是一个增强rnn的long term memory的一个很好的办法实验 dilated rnn,有点意思,感觉是一个增强rnn的long term memory的一个很好的办法实验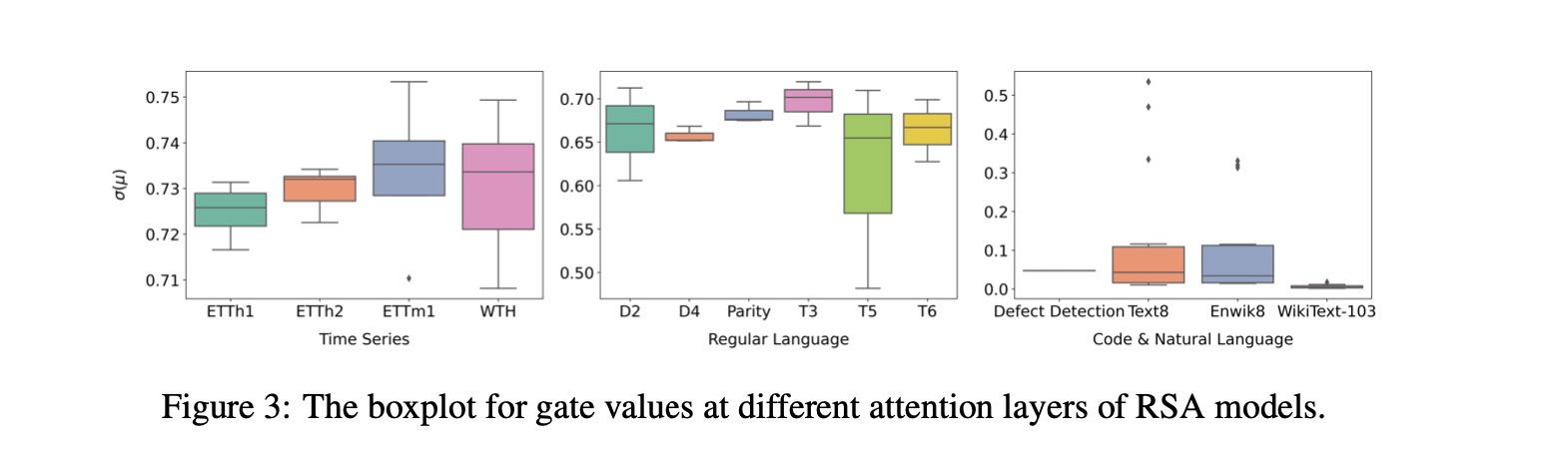 不同的任务学出来的rnn的gate的weight。我们可以看出,time series对recurrence的依赖程度最高(很符合直觉),regular language其次,code & natural language最不依赖recurrence(所以可能是rnn的lm效果依然落后attn的原因 不同的任务学出来的rnn的gate的weight。我们可以看出,time series对recurrence的依赖程度最高(很符合直觉),regular language其次,code & natural language最不依赖recurrence(所以可能是rnn的lm效果依然落后attn的原因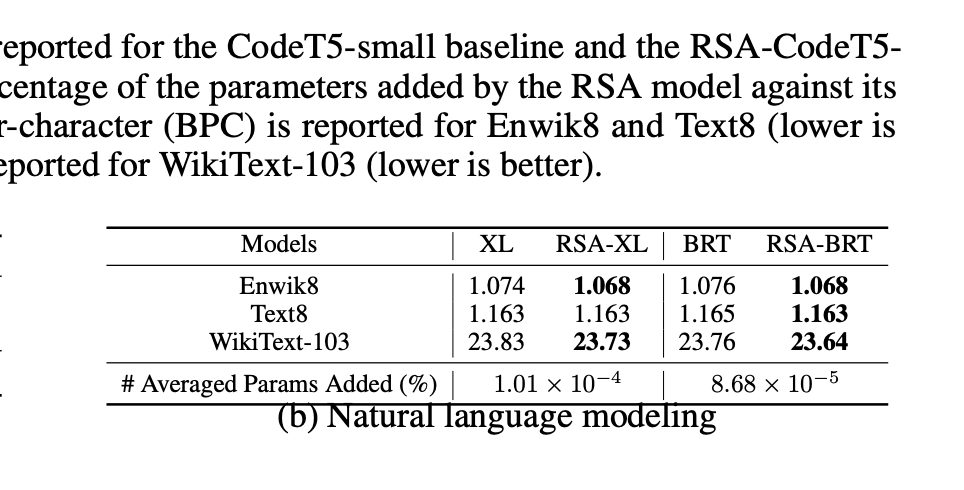 比BRT(sonta:[NIPS'22 简读] Block-Recurrent Transformer + Temporal Latent Bottleneck https://zhuanlan.zhihu.com/p/617481526)要好点 比BRT(sonta:[NIPS'22 简读] Block-Recurrent Transformer + Temporal Latent Bottleneck https://zhuanlan.zhihu.com/p/617481526)要好点 效果更好,data efficiency也更好。 效果更好,data efficiency也更好。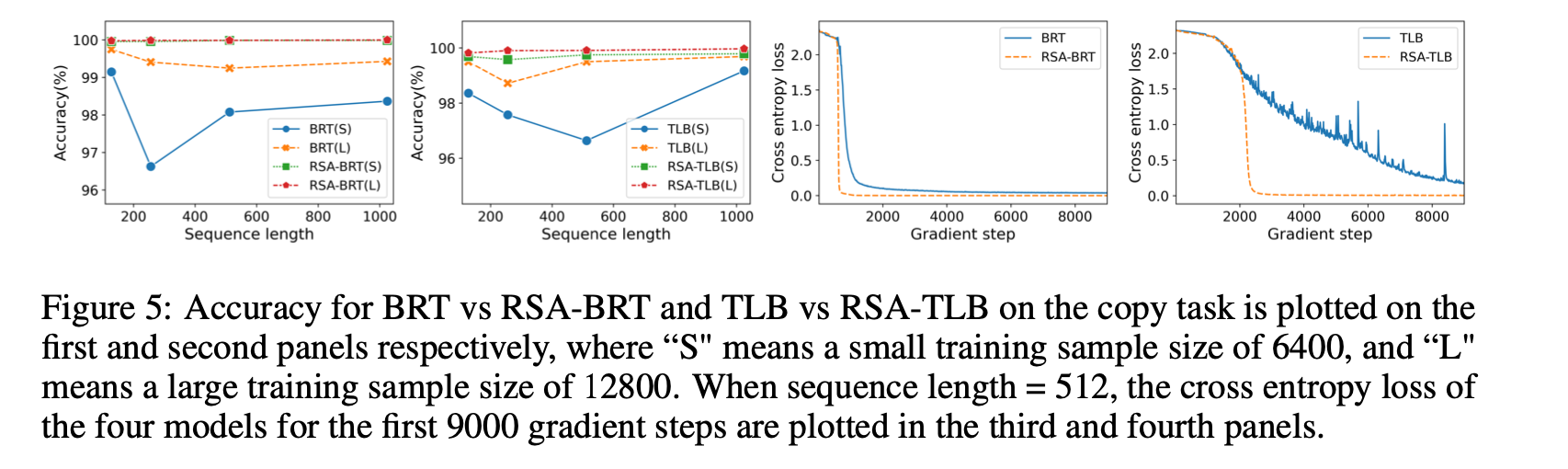 copy task几乎完美。 最右边的图有意思,converge的速度快很多 copy task几乎完美。 最右边的图有意思,converge的速度快很多  dilation很有用 dilation很有用
|
【本文地址】
今日新闻 |
推荐新闻 |