《Read, Listen, and See: Leveraging Multimodal Information Helps Chinese Spell Checking》阅读记录 |
您所在的位置:网站首页 › realise名词英语 › 《Read, Listen, and See: Leveraging Multimodal Information Helps Chinese Spell Checking》阅读记录 |
《Read, Listen, and See: Leveraging Multimodal Information Helps Chinese Spell Checking》阅读记录
|
论文地址:https://arxiv.org/abs/2105.12306 来源:ACL (国际计算语言学协会年会)Findings 2021 时间:2021.5.26 摘要 中文拼写检查(Chinise Spell Checking, CSC): 目的:检测和纠正用户生成的中文文本中的错误字符。大多数汉语拼写错误误用方面如下,使用相似关系解决,大多为启发式或人工困惑集: 语义语音图形这篇论文提出REALISE,利用了汉字的多模式信息,预测正确的输出。 捕捉输入字符的语义、语音和图形信息有选择地混合这些形式的信息 结论REALISE模型使用特定的语义、语音和图形编码器捕捉这些形式的信息,并提出一种选择性模态融合机制控制这些模态的信息流。 SIGHAN基准显示,提出的算法比仅适用文本信息的基线模型具有更大优势,使用听觉和视觉信息有助于汉语拼写检查任务。 介绍 CSC广泛应用 搜索查询校正 (Martins and Silva, 2004; Gao et al., 2010)光学字符识别 (Afli et al., 2016)论文自动评分 (Dong and Zhang, 2016) CSC进展 (Zhang et al., 2020; Cheng et al.,2020) 取得很大进展。(Devlin et al., 2019; Liu et al., 2019; Y ang et al., 2019)应用了大型预处理语言模型 中文拼写检查难点相比于英语中拼写错误为单词无效,汉字都是有效的,拼写错误是误用(语义、语音、图形)。 REALIES模型简介 思想:使用文本、声音、视觉三个编码器学习信息表示。构成: 采用BERT(Devlin et al., 2019) 作为语义编码器的主干捕获文本信息。对于声音(声学)形态,使用汉语拼音作为特征。使用分层编码器处理字符级和句子拼音字母。对于视觉形态,构建了多通道字符图像作为图形特征,每个通道对应一个特定的中文字体,使用ResNet对图像进行分块编码,得到字符图形标识。选择性模态融合机制(融合为紧凑的多模态表示,每个模态有多少信息流向混合表示)预测在相应模态中给定输入的正确字符预训练语音和图形编码器(预训练-微调被证明为有用(Devlin et al.,2019; Dong et al., 2019; Sun et al., 2020))。 实验简介SIGHAN基准,远远超过了所有以前最先进的模型。 使用混淆集 (Lee et al., 2019)捕捉字符相似关系的方法,如达到SOTA的SpellGCN: REALISE在检测和校正水平上,F1平均提高2.4%和2.6%REALISE对混淆集中未定义的错误表现的更好。 本文贡献我们建议除了文字语义之外,还利用汉字的语音和图形信息来完成CSC任务 引入选择性融合机制整合多模态信息 我们提出声学和视觉预处理任务,以进一步提高模型性能 在SIGHAN CSC基准上取得了最佳结果。 相关工作 Chinese Spell Checking研究历程 使用规则处理错误(Chang et al.,2015; Chu and Lin, 2015)传统机器学习方法——条件随机场、隐马尔科夫模型l (Wang and Liao, 2015; Zhang etal.,2015)基于神经的方法——将CSC任务视为一个序列标注问题,双向LSTM预测正确字符(Wang et al. (2018))大规模预处理语言模型(BERT),并使用一些经验度量来选择最可能的字符——(Hong et al. (2019)FASpell) Soft-Masked BERT Model利用级联(串联)结构,其中GRU用于检测错误的位置,BERT用于预测正确的字符 (Zhang et al.,2020)。 使用手工制作的汉字混淆集(Lee et al., 2019) 旨在通过发现容易被误用的汉字的相似性来纠正错误 (Y u and Li, 2014; Wang et al., 2019; Cheng et al., 2020) 。 利用指针网络(Vinyals等人,2015),从混淆集中挑选正确的字符。 Wang et al. (2019) SpellGCN模型,该模型通过图卷积网络(GCNs)对混淆集上的字符相似性进行建模(Cheng et al. (2020) ) 混淆集预先定义和固定的,它不能覆盖所有的相似关系,也不能区分相似性中的差异 多模态学习(Multimodal Learning) 整合不同模式信息,实现更好性能的研究 Multimodal Sentiment Analysis,多模态情感分析 (Zadeh et al., 2016; Zhang et al., 2019)Visual Question Answering ,视觉问答(Antol et al., 2015; Chao et al., 2018Multimodal Machine Translation ,多模态机器翻译 (Hitschler et al., 2016; Barrault et al., 2018) 多模态预处理模型 VL-BERT (Su et al., 2020)Unicoder-VL (Li et al.,2020)LXMERT (Tan and Bansal, 2019) 与本文类似思路 Tianzige-CNN,将汉字视觉信息融入到语言模型中 Meng et al. (2019)本文是第一个利用多模态信息来解决CSC任务的工作。 模型
然后,我们开发了一个选择性模态融合模块来获得上下文感知的多模态表示。 最后,输出层预测错误纠正的概率。 需要信息:上下文(语义)、字符本身的语音和图形 Semantic EncoderBERT作为语义编码器主干(BERT通过对大型语料库的无监督预处理,提供了丰富的上下文词表示。)。 X = (
L:Transformer层的数量,每层:多头注意力机制模块和带有残差链接的前向传播网络,最后为层归一化。 最后一层的输出 拼音组成:声母、韵母和声调。首字母(总共21个)和末字母(总共39个)是用英文字母写的,有五个声调。 思路:使用字母序列来捕捉汉字之间细微的语音差异。输入句中的第i个字符拼音表示为 实现中,我们设计了一个分层语音编码器,它由一个字符级编码器和一个句子级编码器组成。 The Character-level Encoder模拟基本的发音,捕捉字符之间细微的声音差异。是单层单向GRU (Cho et al., 2014)。 第i个字符
4层Transformer,隐藏大小和语义的一样。 获得每个汉字的语境化语音表示。由于独立的语音向量没有按顺序区分,预先将位置嵌入添加到每个向量中。将这些语音向量打包在一起,并应用Transformer层来计算声学模态中的上下文化表示,表示为 由于Transformer的结构,这种表示也是标准化的。 The Graphic EncoderRetNet5(5层ResNet块),然后进行层归一化。
为了有效地提取图形信息,ResNet5中的每个块将图像的宽度和高度减半,并增加通道的数量。因此,最终的输出是一个长度等于输出通道数的向量,即高度和宽度都为1。 为了后续的模态融合,将输出通道的数量设置为语义编码器中的隐藏大小。 输入句的视觉形式:
字符图像从预设的字体文件中读取,选择了黑体的简繁体和小篆,分别对应字符图像三个通道,大小设置为32 × 32像素。 Selective Modality Fusion Module 选择性模态融合模块经过上面的语义、语音和图形编码器之后,得到了表示向量 选择性模态融合模块将这些向量集成到不同的模态中。该模块将信息融合为两个层次,即字符层和句子层。 对于每个模态,使用一个选择门单元来控制有多少信息可以流向混合多模态表示。 例如,如果一个字符由于与正确的发音相似而拼错,那么声学模态中的更多信息应该流入混合表示中。 门值由一个全连接层和一个sigmoid函数来计算。 在形式上,我们将文本、声音和视觉形式的门值表示为 第i个字符的混合多模态计算表示:(W,b由学习得来,[·]表示向量的连接)
使用Transformer在句子级别充分学习语义、语音和视觉信息。 所有字符的混合表示被打包成H0 = L'是Transformer层的数量, 目的:学习声学-文本和视觉-文本的关系,我们建议对语音和图形编码器进行预处理 语音编码器:设计了一个输入法预处理目标,即编码器在给定输入拼音序列的情况下恢复汉字序列。在编码器的顶部添加了一个线性层,将隐藏状态转换为汉字词汇上的概率分布。我们用训练数据中有拼写错误的句子的拼音对语音编码器进行预处理,使其恢复出没有拼写错误的字符序列。 图形编码器:设计了一个光学处理识别目标,在给定汉字图像的情况下,图形编码器学习视觉信息来预测汉字词汇上的相应字符。识别只在字符级别和键入的脚本上进行。在预处理过程中,我们还会在顶部添加一个线性层来执行分类 实验 数据 训练集: SIGHAN训练数据生成的伪数据测试集: SIGHAN2013、2015、2015(使用OpenCC工具转化为了简体) 评价说明在检测级别,当且仅当句子中的所有拼写错误都被成功检测到时,句子才被认为是正确的。 在纠正级别,模型不仅要检测到错误字符,还要将所有错误字符纠正到正确的字符。 我们报告了两个级别的准确性、准确性、召回率和F1成绩。 实现细节 PyTorch(Transformer库)语义编码器的架构与BERTBASE模型相同(12个注意头,12个Transformer层,隐层大小为768)用BERT-wwm模型的权重初始化语义编码器 语音句级编码器,我们将层数设置为4层,并用BERT的位置嵌入初始化其位置嵌入。 选择性模态融合模块有3个Transformer层,即L'= 3,预测矩阵 Pillow库提取汉字图像 当处理特殊记号(例如,BERT的[CLS]和[SEP])时,使用零值张量作为它们的图像输入 AdamW作为优化器 10 Epoches 学习率: 5e-5 (learning rate warming up and linear decay.) batch size: 32 SIGHAN13有很多“的”, “地”, “得”混用,即使是好模型结果也不会很好,措施:简单地删除所有检测到的和纠正的”的", "地“,还有”得模型输出的字符,然后用SIGHAN13测试集的基本事实进行评估。 基线 主要利用启发式或传统的机器学习算法,如n-gram语言模型、条件随机场和隐马尔可夫模型。 KUAS (Chang et al., 2015),NTOU (Chu and Lin, 2015),NCTU-NTUT (Wang and Liao,2015),HanSpeller++ (Zhang et al., 2015),LMC (Xie et al., 2015)将CSC视为序列标记问题,并应用BiLSTM模型 Sequence Labeling (Wang et al., 2018)利用去噪自动编码器生成候选字符 FASPell(Hong et al., 2019)检测模型帮助校正模型学习正确的上下文 Soft-Masked BERT (Zhang et al., 2020)通过图形卷积网络将预定义的字符混淆集合并到基于BERT的校正模型中 SpellGCN (Cheng et al., 2020) 使用CSC训练数据直接微调BERTBASEmodel BERT (Devlin et al., 2019) 实验结果
REALISE模型的性能明显优于所有以前的最先进的模型。 通过从听觉和视觉模式中捕捉有价值的信息,比BERT的表现好了很多。 Correction级别: REALISE在SIGHAN13上,F1超过 BERT 5.2% , 在SIGHAN14超过3.8% 在SIGHAN15超过 4.4% 相对于SpellGCN,detection级别,REALISE的F1提升了2.4%,correction级别提升了2.6% 与其他扩展的BERT相比,汉字多模态信息的显式利用更有利于CSC任务。 经过处理后,REALISE模型领先于所有基线模型。 消融研究1)移除语音编码器, 2)移除图形编码器, 3)仅使用一种字体(简体中文中的黑体)作为图形编码器, 4)移除听觉和视觉预处理目标, 5)用简单求和代替选择性模态融合机制。
表内数据为SIGHAN的平均得分。 如果去掉语音或图形编码器,我们可以看到模型性能下降了两个级别,但仍然明显优于BERT。这表明检查模型可以受益于多模态信息。无论我们移除哪个组件,implement的性能都会下降,这充分证明了我们模型中每个部分的有效性。 选择性模态融合模块分析
第一个例子中 第二个例子中 SIGHAN15上每个模态错误字符的平均门限值,最大的值几乎等于1.0的文本形态。声学模态平均值为0.334,最小的为视觉模态是0.229。说明这意味着来自语义编码器的信息对于纠正拼写错误是最重要的。声学模态比视觉模态更重要,这与相似发音导致的拼写错误比相似字符形状导致的拼写错误更频繁的事实相一致。 有些错误SpellGCN不能识别出来,因为手工制作的混淆集没有被定义为混淆字符对。 在SIGHAN15测试集中,有16%的错误字符对不在预定义的混淆集中。SpellGCN纠正了64.6%的错误,但REALISE73.5%的纠正效果更好。 对于预定义集合中容易混淆的配对,拼写纠正率为82.5%,REALISE纠正率为85.8%,有助于模型更好地概括捕获字符相似关系。 |
 首先使用多个编码器从文本、声音和视觉形式中获取有价值的信息。
首先使用多个编码器从文本、声音和视觉形式中获取有价值的信息。

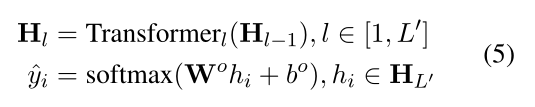



【本文地址】
今日新闻 |
推荐新闻 |