在 TextCNN 上实验 Dropout 和对比学习 |
您所在的位置:网站首页 › rdrop什么意思 › 在 TextCNN 上实验 Dropout 和对比学习 |
在 TextCNN 上实验 Dropout 和对比学习
|
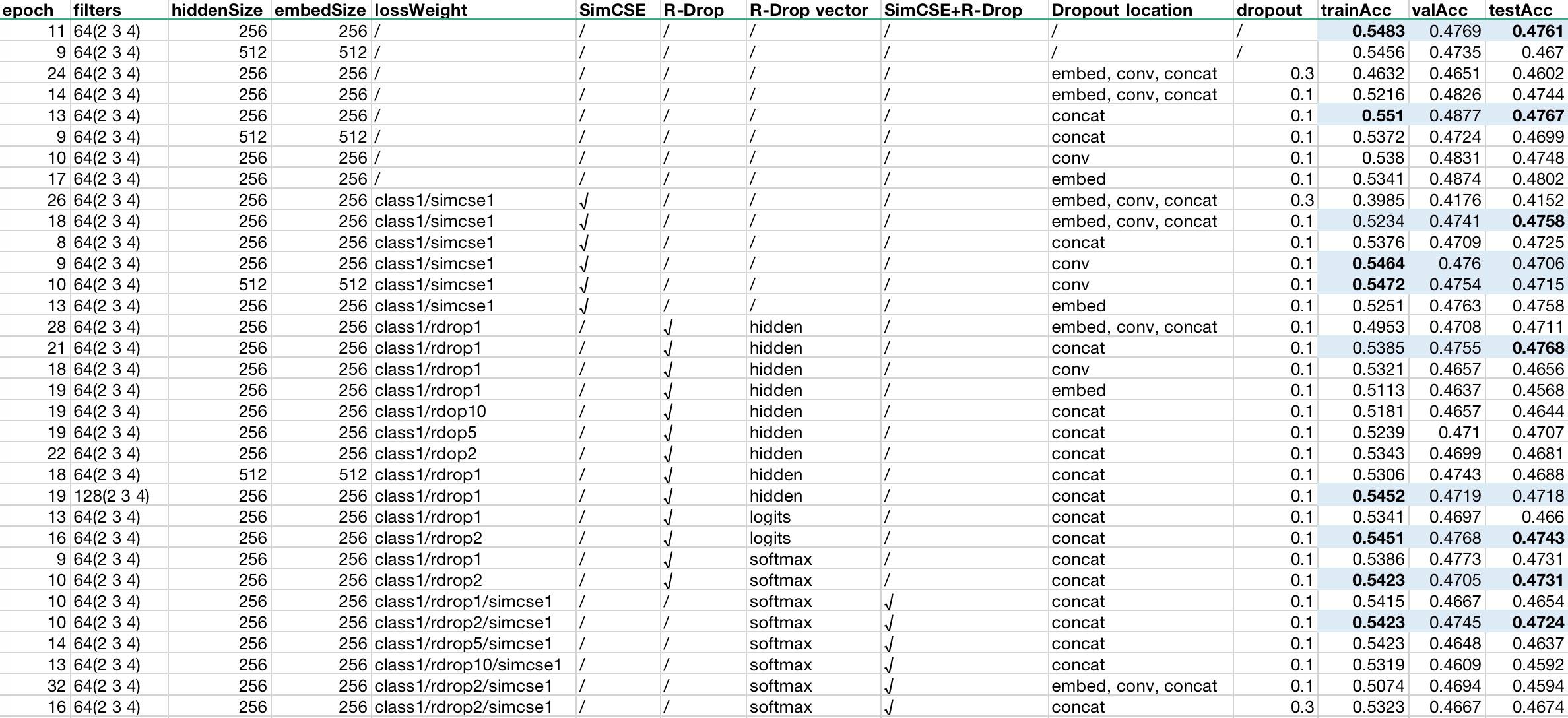
一句话概述:即使在简单模型上,使用 SimCSE 和 R-Drop 也能够起到一定效果,但太简单的模型(类似 TextCNN)效果可能不太明显。如果嫌麻烦也可以不用,但 Dropout 最好使用,主要用在稠密连接,比如 Embedding、Concat、Attention、FC 等层的后面。 如果只想看结论,到这里就可以结束啦。 前一阵子 Dropout 突然成为了对比学习的新宠,简直到了「遇事不决 Dropout」 的程度,其中最具代表性的两篇文章是 SimCSE 和 RDrop。两者的共同点是都对同一个样例跑了两次(因为 Dropout 是随机的,所以可以看成是两个子模型),拿到同一个输入的不同输出做后续处理。不同的是前者使用两次输出特征向量的相似度作为 logits,损失函数为交叉熵,而后者则以输出概率的分布计算 KL 散度作为损失函数。关键是,它们都真的取得了很不错的效果。 两篇论文对这样的现象都做了一些解释甚至证明(也许作者在实验前也没想到会效果好?)。SimCSE 从表征的对齐性(align)和均匀性(uniform)角度进行了比较深入的探讨,结果表明: 无监督 SimCSE 改善了无监督的均匀同时保持良好的对齐 在 SimCSE 中加入监督数据进一步修正了对齐 SimCSE 可以有效地「扁平化」预训练嵌入的奇异值分布R-Drop 则是从正则化的角度出发,使用 KL 散度损失函数对传统 Dropout 做了补充,降低了模型参数的自由度,进而降低了模型的空间复杂度,增强了泛化能力。 不过两种方法都是在 Transformer 架构的模型上做的,很早就冒出过念头,想在简单模型上试试效果,于是就有了这次的实验,纯粹是为了满足好奇心。模型有多简单呢?我们直接用了 TextCNN(当然,主要的原因是没有 GPU,其他模型等不起)。 背景简介本节主要简要介绍 Dropout 相关知识点。 什么是 Dropout? Dropout 简单来说就是在神经网络执行过程中,对得到的隐向量随机丢弃一部分比例(设为0),并对剩余值进行缩放(缩放比例为 1/(1 - rate)),以减少过拟合,提高泛化能力的方法。 需要注意的是,无论哪种学习框架,一般都会带有 Training 参数,用于控制是否启用 Dropout,一般在训练时设置为启用,推理时则不启用,否则每次预测都会得到不同结果的输出。 API 以 Tensorflow 为例,API 为: 123tf.keras.layers.Dropout( rate, noise_shape=None, seed=None, **kwargs)其中: rate:Dropout 的比例 noise_shape:一维整数张量,表示将与输入相乘的二进制 Dropout 掩码的形状,比如输入的 shape 为 (batch_size, timesteps, features),如果想要在每一个 timestep 都 drop 相同的位置,可以将此参数设置为 (batch_size, 1, features)调用的时候则包含两个参数: 输入 inputs 是否启用布尔值 training示例 以官方例子来说明: 1234567891011121314151617181920# From: https://www.tensorflow.org/api_docs/python/tf/keras/layers/Dropouttf.random.set_seed(0)layer = tf.keras.layers.Dropout(.2, input_shape=(2,))data = np.arange(10).reshape(5, 2).astype(np.float32)print(data)outputs = layer(data, training=True)print(outputs)"""[[0. 1.] [2. 3.] [4. 5.] [6. 7.] [8. 9.]]tf.Tensor([[ 0. 1.25] [ 2.5 3.75] [ 5. 6.25] [ 7.5 8.75] [10. 0. ]], shape=(5, 2), dtype=float32)"""源码Tensorflow Keras 的代码最后调用了 nn.dropout,我们直接看这个源码,简化后如下: 12345678910111213141516# From https://github.com/tensorflow/tensorflow/blob/v2.6.0/tensorflow/python/ops/nn_ops.py#L5232-L5364def dropout(x, rate, noise_shape=None, seed=None, name=None): keep_prob = 1 - rate scale = 1 / keep_prob scale = ops.convert_to_tensor(scale, dtype=x_dtype) # x * scale ret = gen_math_ops.mul(x, scale) noise_shape = _get_noise_shape(x, noise_shape) # 0-1 均匀分布 random_tensor = random_ops.random_uniform( noise_shape, seed=seed, dtype=x_dtype) # mask 掉值为 0 的位置 keep_mask = random_tensor >= rate ret = gen_math_ops.mul(ret, gen_math_ops.cast(keep_mask, x_dtype)) return ret可以看到大致分成了两步:缩放、Mask。 有什么作用? 主要目的就是提高模型泛化能力,增加鲁棒性。从直觉上来看,你看这神经网络它又大又宽,啊有点乱入。总之,稠密复杂的网络容易导致过拟合,Dropout 通过极其简单粗暴的方法——丢弃一部分值缩放剩余值,其实等价于抑制某些神经元而强化另外的神经元,来避免过度拟合。从这个角度一看,LSTM 的丢弃门(就是普通门,不是那种门)、残差连接都是类似的套路,甚至 CNN 都可以看作是强行用「几个」神经元去提取特征,不就等于 noise_shape 参数启用时的效果么。这可能也说明了 Dropout 为什么在 Self-Attention 中特别重要。 为什么有效? 最为常见的是从集成学习角度进行解释:即 Dropout 等价于使用多个弱分类器,从而能够有效降低偏差。这当然是没有问题的,其实从根本上说 Dropout 就是让整个模型能够尽量使用「更少」的参数来表征出「更好」的效果,是一种泛化模型的手段。 一般用在哪里? 通过上面的分析探讨,这个问题应该是显而易见的:Dropout 一般应用于「稠密」输出后面,比如: WordEmbedding 输出后 Concat 输出后 Attention 输出后 FC 层输出后 Bert 等得到的 Pool 输出后Dropout 不应该使用在 CNN 的卷积层、Pooling 层后面,因为它们本身已经进行了很大程度的「抽象」,叠加起来效果可能会下降。 实验设置实验任务 使用 TNEWS 数据集(详见:CLUE),多分类模型。数据集概览如下: 123# 数据量:训练集 (12,133),验证集 (2,599),测试集 (2,600){"label": "110", "label_des": "社区超市", "sentence": "朴朴快送超市创立于 2016 年,专注于打造移动端 30 分钟即时配送一站式购物平台,商品品类包含水果、蔬菜、肉禽蛋奶、海鲜水产、粮油调味、酒水饮料、休闲食品、日用品、外卖等。朴朴公司希望能以全新的商业模式,更高效快捷的仓储配送模式,致力于成为更快、更好、更多、更省的在线零售平台,带给消费者更好的消费体验,同时推动中国食品安全进程,成为一家让社会尊敬的互联网公司。, 朴朴一下,又好又快,1. 配送时间提示更加清晰友好 2. 保障用户隐私的一些优化 3. 其他提高使用体验的调整 4. 修复了一些已知 bug"}共 15 个类别,分别为如下: 123456789101112131415{"label": "100", "label_desc": "news_story"}{"label": "101", "label_desc": "news_culture"}{"label": "102", "label_desc": "news_entertainment"}{"label": "103", "label_desc": "news_sports"}{"label": "104", "label_desc": "news_finance"}{"label": "106", "label_desc": "news_house"}{"label": "107", "label_desc": "news_car"}{"label": "108", "label_desc": "news_edu"}{"label": "109", "label_desc": "news_tech"}{"label": "110", "label_desc": "news_military"}{"label": "112", "label_desc": "news_travel"}{"label": "113", "label_desc": "news_world"}{"label": "114", "label_desc": "news_stock"}{"label": "115", "label_desc": "news_agriculture"}{"label": "116", "label_desc": "news_game"}由于测试集本身不带 label,因此我们使用训练集进行训练和验证,使用验证集作为测试集。 参数配置 模型:TextCNN,默认参数如下: 12345678910{ "vocab_size": 8021, "num_oov_buckets": 99, "embed_size": "256", "filters": 64, "filter_size": "2,3,4", "dropout": 0.1, "max_seq_len": 128, "num_labels": 15}分别从以下角度进行了实验: Dropout 的位置 Embedding 维度 Filter 数量 是否使用 Dropout 是否使用 SimCSE 是否使用 R-Drop用到的一些其他配置如下: 优化算法:Adam(LR=0.1),没有 WarmUp 或 LR Decay BatchSize 64,初始 50 个 Epoch,连续 3 个 Epoch 效果没有提升则提前终止损失函数代码 代码均参考苏神的实现(个人感觉比官方实现更简洁易懂): 12345678910111213141516171819202122# From: https://github.com/bojone/SimCSEdef simcse_loss(y_true, y_pred): K = tfk.backend idxs = K.arange(0, K.shape(y_pred)[0]) idxs_1 = idxs[None, :] idxs_2 = (idxs + 1 - idxs % 2 * 2)[:, None] y_true = K.equal(idxs_1, idxs_2) y_true = K.cast(y_true, K.floatx()) y_pred = K.l2_normalize(y_pred, axis=1) similarities = K.dot(y_pred, K.transpose(y_pred)) similarities = similarities - tf.eye(K.shape(y_pred)[0]) * 1e12 similarities = similarities * 20 loss = K.categorical_crossentropy(y_true, similarities, from_logits=True) res = K.mean(loss) return res# From: https://github.com/bojone/r-dropdef rdrop_loss(y_true, y_pred): loss = kld(y_pred[::2], y_pred[1::2]) + kld(y_pred[1::2], y_pred[::2]) res = K.mean(loss) return res编译时指定 loss 权重: 123456789101112131415model.compile( optimizer=tfk.optimizers.Adam(learning_rate=1e-3), loss=[ tfk.losses. SparseCategoricalCrossentropy(from_logits=False), rdrop_loss, simcse_loss ], metrics=[ [tfk.metrics.SparseCategoricalAccuracy(name="class")], [None], [None] ], loss_weights=[1.0, 2.0, 1.0], weighted_metrics=None)当然,直接把所有的 loss 在一个 function 里计算好应该是一样的。 实验结果我们一共做了 33 组实验,结果如下:
由此可以得出以下可能的结论(及可能的解释): 在类似 CNN 这样自带一定程度的 Dropout 的模型上使用 Dropout 效果不明显(可能模型过于简单,表征本身就不会过拟合) 简单模型可以不用 Dropout(在 CNN 上尤其如此) 单使用交叉熵损失 + Dropout 可以取得最好的效果(Dropout 即使在简单模型下依然有效果) Dropout 应加在 concat 后面(拼接后特征可能有冗余),同时在多个地方使用效果反而会下降(可能模型过于简单) Dropout 比例不能太高(可能因为模型本身太简单) 加入 SimCSE 后效果提升不明显(可能 SimCSE 更加侧重相似) 每个位置都加时验证 Acc 最高,对比单使用交叉熵也有所提高(说明可能确实提高了泛化能力) 只在 Conv 后面添加时训练 Acc 最高,但测试 Acc 很低(说明 Conv 可能是关键特征所在,这里 Dropout 再加上 SimCSE 可能导致过拟合,不过也在一定程度上说明 SimCSE 确实有一定效果) 加入 RDrop 后测试效果明显(可能因为它更加关注输出特征表征) 在 hidden(CNN 中即 Concat 后的向量)处使用 RDrop,测试 Acc 在所有实验中最高(可能有强化 hidden 的作用,使其泛化能力较好) 增加卷积核数量可以提升训练 Acc,但没有明显提升测试 Acc(说明表征可能已达到模型上限); 在 logits 处和 softmax 处效果差不多,后者略差,两者都比 hidden 处差(至少说明简单模型下 RDrop 可能并不一定用在最终的概率分布上,也可以用在内部表征上) 越靠近 softmax 处,RDrop 的权重越大效果越好(可能 RDrop 需要努力影响结果) 同时加入 SimCSE 和 RDrop 后效果反而不如单个使用(可能模型本身太简单) RDrop 权重较高(此处为 2)时效果最好,再高或低都不太好(可能因为 RDrop 和 SimCSE 达到了某种平衡) 增加更多的 Dropout 效果下降严重(可能因为 Dropout 过多,再加上 SimCSE 和 RDrop 的限制,导致表征能力不足) 增加 embed size 效果不增反降,可能说明表征空间维度太高导致模型更难以很好地控制。以上,如有不当之处,恳请予以指正,一起探讨。 分析讨论通过实验我们可以发现 SimCSE 和 R-Drop 的确有效,即便只是在简单模型和少量数据下。 由于种种原因,本次实验依然有许多不足之处,包括: 未能尝试更多稍复杂的模型。比如至少还可以尝试 LSTM 或 LSTM+SelfAttention 这样的小模型。 未能尝试更多任务。比如增加相似任务、Token 标注任务等。 未能尝试更多参数。比如没有使用 Warmup、Decay 等策略,没有尝试不同的学习率等。不过通过这个简单的实验,我们还是能够发现不少问题的,简单汇总来说: 如果是简单模型,什么策略不策略的问题不大,Dropout 一些特殊位置即可 如果是复杂模型(尤其是 BERT 时代),SimCSE、RDrop 什么的都可以上,它们本身其实也是可以互补的 Reference 文本分类有哪些论文中很少提及却对性能有重要影响的 tricks? | 机器之心 |
【本文地址】
今日新闻 |
推荐新闻 |