Google Colab 训练很慢原因 |
您所在的位置:网站首页 › rar压缩很慢 › Google Colab 训练很慢原因 |
Google Colab 训练很慢原因
|
前言
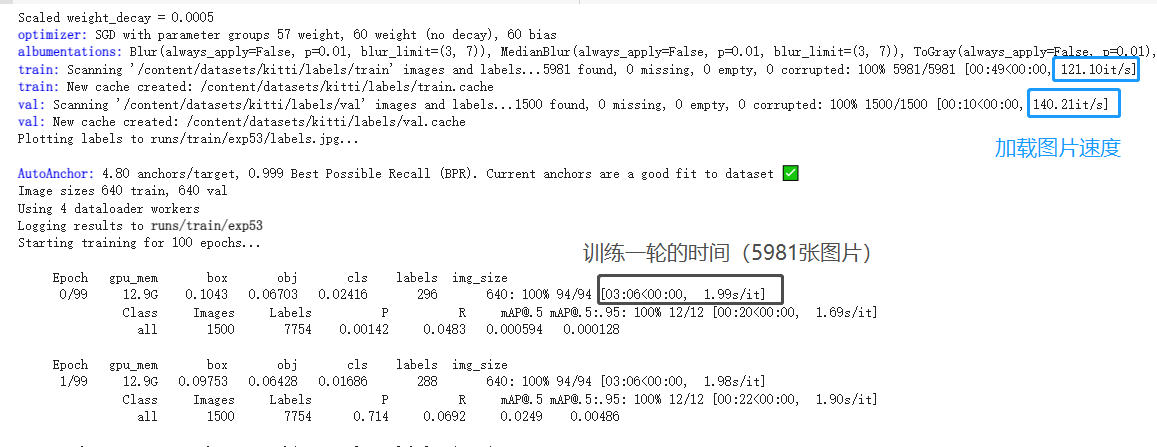
最近在使用Google Colab 训练模型,分配的是 Tesla P100-PCIE-16G 显卡;这个显卡也不是很弱啊,但在训练模型时,发现很慢。比我本地的两张1080ti显卡(合起来也是16G)慢几倍了,感到非常困惑,后来看了很多文章,发现了是谷歌网盘驱动器读取数据集慢 导致的。。。。。。 关于之前使用Google Colab(错误示范)首先是把代码和数据集也下载放到了谷歌网盘;想着下载处理好数据集后,下次能直接训练,不用重新下载数据集和重新处理数据了。 然后是挂载谷歌网盘;Google Colab中进入谷歌网盘的代码目录。 最后进行训练模型。 后来发现从谷歌网盘驱动器读取文件是非常慢的,训练过程处理需要GPU的计算,还需读取训练集的数据;如果读取数据速度很慢,GPU再怎么强,也体现出不优势了。比如:GPU处理一张图片可能只需0.001ms,但读取一张图片却要1.0ms。 解决思路既然我们知道了是数据集放到了谷歌网盘,从谷歌网盘读取过来时很慢,导致训练时间增大;那可以不把数据集放到谷歌网盘,直接放到 Colab 中存储,这样能有效解决读取数据集慢的问题了。 或者把数据集放到了谷歌网盘,然后使用某种内存映射文件(如 hdf5 或 lmdb)来解决此问题。这样 I\O 操作要快得多。 思路1——直接把数据集放到Colab 中存储打开Colab 后,默认来到 /content 目录下,这是Colab中存储目录;我们可以在/content 目录下创建文件夹,来存放数据集。 比如/content 目录下创建datasets文件夹,然后用ls 查看创建好的目录。 !mkdir datasets !ls训练Kitti数据集,训练集:5981张;验证集:1500张;测试:7518张。
训练一轮大约3分钟,还是挺快的了。对比之前把数据集放到谷歌网盘,然后直接读取的方式,训练时间需要24分钟左右。 这种方法的缺点:每次需要重新下载数据集,处理数据;造成重复操作效率降低。(不过在Colab 下载数据集也是很快的,通常有40M/s;有时慢的10M/s) 思路2——hdf5方式内存映射文件这是把谷歌网盘中的数据集通过hdf5方式进行内存映射,然后训练时加载hdf5文件,从而减少读取数据时间,提高训练速度。 HDF5 优点:它的层次结构(类似于文件夹/文件)、与每个项目一起存储的可选的任意元数据;以及它的灵活性(例如压缩);另一个优点是数据集可以是固定大小的或灵活的尺寸。因此,可以轻松地将数据附加到大型数据集,而无需创建全新的副本。 有关 hdf5 格式的速度增益参考:python - Is there an analysis speed or memory usage advantage to using HDF5 for large array storage (instead of flat binary files)? - Stack Overflow 详细操作参考这篇文章:https://medium.com/@oribarel/getting-the-most-out-of-your-google-colab-2b0585f82403 案例步骤: 1、挂载谷歌网盘 from google.colab import drive drive.mount('/content/drive')运行后上面的代码片段后,须要点击链接,在你的谷歌网盘帐户来验证你Colab:登录后得到一串“码”,复制粘贴到运行处。 2、更新数据挂载谷歌网盘后,Colab将不会遇到对网盘目录的任何更改(编辑代码、添加文件等)。这是由于 Colab 缓存机制造成的。为了克服这个问题,应该在使用新文件之前清除缓存,命令如下: !google-drive-ocamlfuse -cc 3、hdf5方式映射数据集Python 提供了 h5py 和 lmdb 库来处理这些文件格式。h5py 可以轻松地以 NumPy 数组的形式存储和操作现有数据,我们使用hdf5内存映射文件格式。 此代码创建一个新的 .h5 文件,其中包含用于训练、开发和测试数据集的占位符。 import h5py from PIL import Image fileName = 'data.h5' numOfSamples = 10000 with h5py.File(fileName, "w") as out: out.create_dataset("X_train",(numOfSamples,256,256,3),dtype='u1') out.create_dataset("Y_train",(numOfSamples,1,1),dtype='u1') out.create_dataset("X_dev",(numOfSamples,256,256,3),dtype='u1') out.create_dataset("Y_dev",(numOfSamples,1,1),dtype='u1') out.create_dataset("X_test",(numOfSamples,256,256,3),dtype='u1') out.create_dataset("Y_test",(numOfSamples,1,1),dtype='u1')要将我们的数据加载到这些“关键字”中,以 Python 字典样式访问“关键字”。在这里,我们将训练图像加载到X_train“关键字”,训练标签加载到Y_train“关键字”等等。 out.create_dataset("X_train",(numOfSamples,256,256,3),dtype='u1') 这行代码是将训练图像加载到X_train“关键字”,图片宽高分别是256x256,3通道RGB。 with h5py.File(fileName, "a") as out: img = Image.open("X_train_1.jpg") # X_train_1.jpg is 256 x 256 RGB image out['X_train'] = numpy.asarray(img)使用 PyTorch,编写自己的 .h5Dataset供 PyTorch 使用DataLoader: import torch import numpy as np import torch.optim as optim import torch.utils.data import torchvision.datasets as dset import torchvision.transforms as transforms import torchvision.utils as vutils from PIL import Image import h5py class dataset_h5(torch.utils.data.Dataset): def __init__(self, in_file, transform=None): super(dataset_h5, self).__init__() self.file = h5py.File(in_file, 'r') self.transform = transform def __getitem__(self, index): x = self.file['X_train'][index, ...] y = self.file['Y_train'][index, ...] # Preprocessing each image if self.transform is not None: x = self.transform(x) return (x, y), index def __len__(self): return self.file['X_train'].shape[0]下面是调用 dataset_h5( ) 函数,然后加载数据集。 dataset = dataset_h5("PATH_TO_YOUR_.h5_FILE",transform=transform) dataloader = torch.utils.data.DataLoader( dataset, batch_size=8, drop_last=True, shuffle=bshuffle, num_workers=1)本文只供大家参考与学习,谢谢。 |
【本文地址】