【VAR模型 |
您所在的位置:网站首页 › rac模型 › 【VAR模型 |
【VAR模型
|
向量自回归 (VAR) 是一种随机过程模型,用于捕获多个时间序列之间的线性相互依赖性。 VAR 模型通过允许多个进化变量来概括单变量自回归模型(AR 模型)。 VAR 中的所有变量都以相同的方式进入模型:每个变量都有一个方程式,根据其自身的滞后值、其他模型变量的滞后值和一个误差项来解释其演变。 文章目录 一、简介二、VAR模型公式背后的直觉三、在Python中构建VAR模型3.1 导包3.2 导入数据集3.3 可视化时间序列3.4 使用格兰杰因果关系检验检验因果关系3.5 协整测试3.6 将序列拆分为训练数据和测试数据3.7 检查平稳性并使时间序列保持平稳3.8 如何选择VAR模型的阶数(P)3.9 训练选定订单的VAR模型(p)3.10 使用德宾沃森统计量检查残差(误差)的序列相关性3.11 如何使用统计模型预测VAR模型3.12 反转变换以获得真实预测3.13 预测与实际图3.14 评估预测 一、简介首先,什么是向量自回归(VAR)以及何时使用它? 向量自回归 (VAR) 是一种多变量预测算法,当两个或多个时间序列相互影响时使用。 这意味着,使用 VAR 的基本要求是: 至少需要两个时间序列(变量);时间序列应相互影响。好。那么为什么它被称为“自回归”呢? 它被认为是自回归模型,因为每个变量(时间序列)都建模为过去值的函数,即预测变量只不过是序列的滞后(时间延迟值)。 好的,那么VAR与其他自回归模型(如AR,ARMA或ARIMA)有何不同? 主要区别在于这些模型是单向的,其中预测变量影响 Y,反之亦然。而矢量自动回归 (VAR) 是双向的。也就是说,变量相互影响。 二、VAR模型公式背后的直觉在自回归模型中,时间序列被建模为其自身滞后的线性组合。也就是说,序列的过去值用于预测当前和未来。 典型的 AR(p) 模型方程如下所示:
其中α是截距,一个常数,β1,β2 直到 βp 是 Y 到 p 阶的滞后的系数。阶“p”表示,最多使用 Y 的 p 滞后,它们是方程中的预测因子。ε_{t}是错误,被视为白噪声。 好。那么,VAR模型的公式是什么样的呢? 在VAR模型中,每个变量都被建模为自身过去值和系统中其他变量过去值的线性组合。由于我们有多个相互影响的时间序列,因此将其建模为方程组,每个变量(时间序列)一个方程。 也就是说,如果有5个相互影响的时间序列,我们将拥有一个由5个方程组成的系统。 那么,方程是如何精确构建的? 假设我们有两个变量(时间序列)Y1 和 Y2,需要在时间(t)预测这些变量的值。 为了计算Y1(t),VAR将使用Y1和Y2的过去值。同样,要计算 Y2(t),请使用 Y1 和 Y2 的过去值。 例如,具有两个时间序列(变量“Y1”和“Y1”)的 VAR(2) 模型的方程组如下:
其中,Y{1,t-1} 和 Y{2,t-1} 分别是时间序列 Y1 和 Y2 的第一个滞后。 上述方程称为 VAR(1) 模型,因为每个方程的阶数为 1,也就是说,它最多包含一个预测变量(Y1 和 Y2)的滞后。 由于方程中的 Y 项是相互关联的,因此 Y 被视为内生变量,而不是外生预测因子。 类似地,两个变量的二阶 VAR(2) 模型将为每个变量(Y1 和 Y2)包含最多两个滞后。
能想象一个有三个变量(Y2、Y1和Y2)的二阶VAR(3)模型会是:
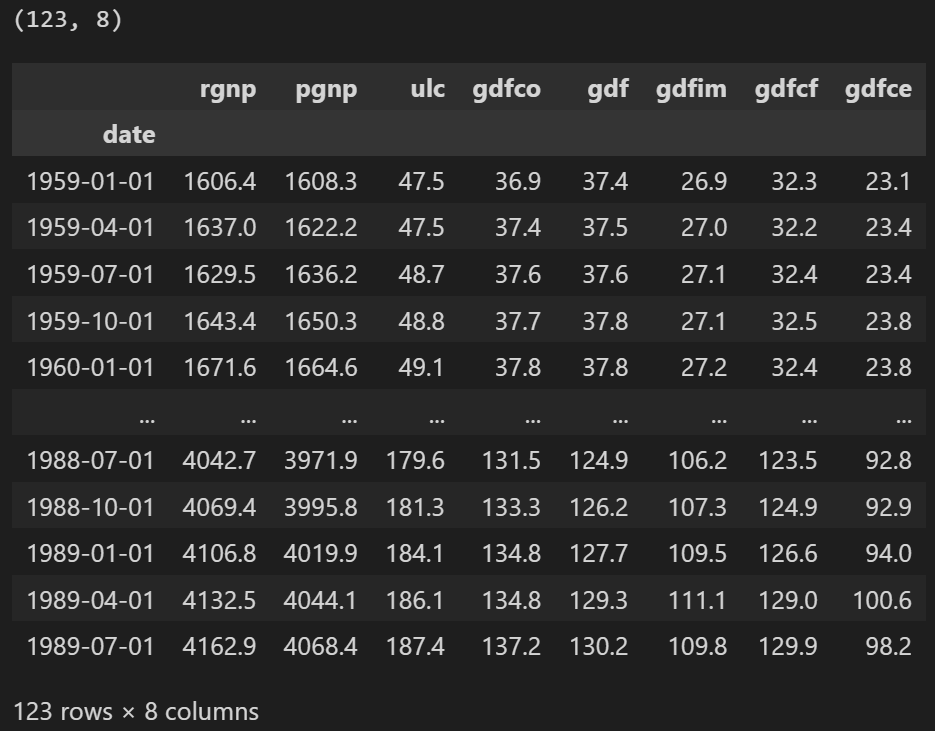
随着模型中时间序列(变量)数量的增加,方程组会变大。 三、在Python中构建VAR模型构建 VAR 模型的过程涉及以下步骤: 分析时间序列特征检验时间序列之间的因果关系平稳性测试如果需要,转换序列以使其静止找到最佳顺序 (p)准备训练和测试数据集训练模型回滚转换(如果有)使用测试集评估模型对未来的预测 3.1 导包 import pandas as pd import numpy as np import matplotlib.pyplot as plt %matplotlib inline # Import Statsmodels from statsmodels.tsa.api import VAR from statsmodels.tsa.stattools import adfuller from statsmodels.tools.eval_measures import rmse, aic 3.2 导入数据集使用Yash P Mehra在1994年的文章“工资增长和通货膨胀过程:一种实证方法”中使用的时间序列。 此数据集具有以下 8 个季度时间序列: rgnp : Real GNP.(实际国民生产总值)pgnp : Potential real GNP.(潜在实际国民生产总值)ulc : Unit labor cost.(单位人工成本)gdfco : Fixed weight deflator for personal consumption expenditure excluding food and energy.(不包括食品和能源的个人消费支出固定权重平减指数)gdf : Fixed weight GNP deflator.(固定权重国民生产总值平减指数)gdfim : Fixed weight import deflator.(固定重量进口平减指数)gdfcf : Fixed weight deflator for food in personal consumption expenditure.(个人消费支出中食品固定权重平减指数)gdfce : Fixed weight deflator for energy in personal consumption expenditure.(个人消费支出能源固定权重平减指数) filepath = 'https://raw.githubusercontent.com/selva86/datasets/master/Raotbl6.csv' df = pd.read_csv(filepath, parse_dates = ['date'], index_col = 'date') print(df.shape) df
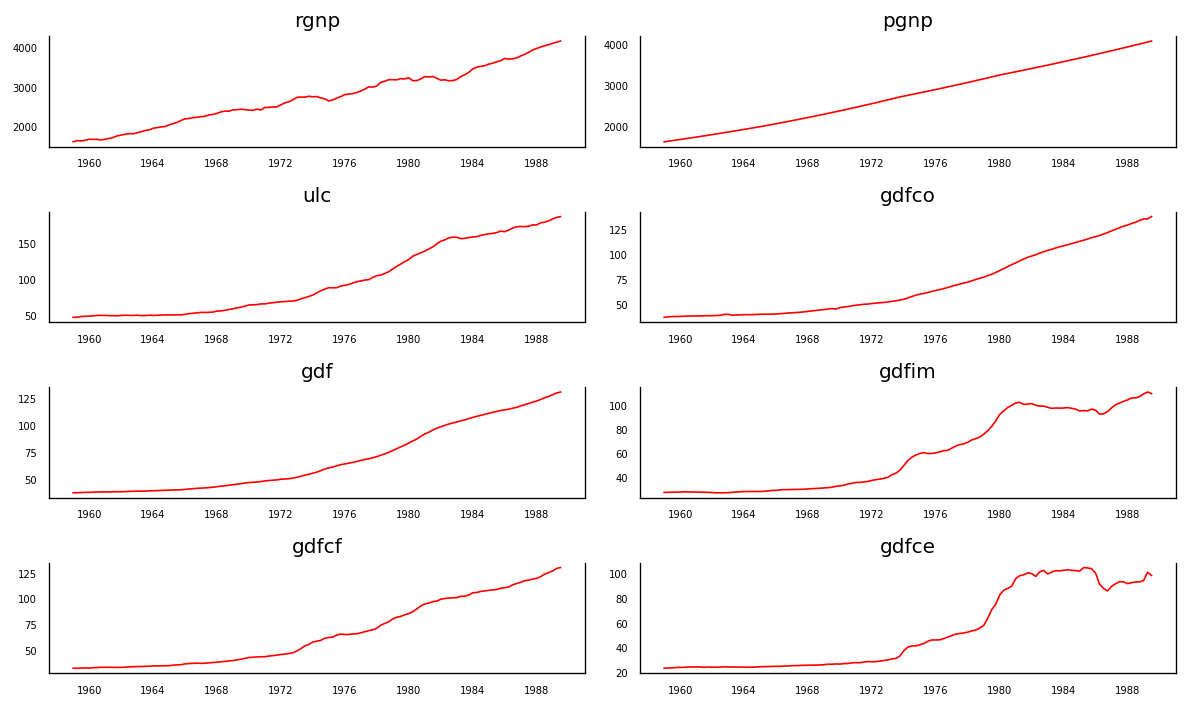
每个系列多年来都有相当相似的趋势模式,除了gdfim和gdfce,从 1980 年开始注意到不同的模式。 好的,分析的下一步是检查这些序列之间的因果关系。格兰杰因果关系检验和协整检验可以帮助我们解决这个问题。 3.4 使用格兰杰因果关系检验检验因果关系矢量自动回归背后的基础是系统中的每个时间序列相互影响。也就是说,可以使用自身的过去值以及系统中的其他序列来预测序列。 使用格兰杰因果关系检验,甚至可以在构建模型之前测试这种关系。 格兰杰的因果关系到底检验的是什么呢? 格兰杰因果关系检验回归方程中过去值的系数为零的原假设。 简单来说,时间序列 (X) 的过去值不会导致其他序列 (Y)。因此,如果从检验获得的 p 值小于显著性水平 0.05,则可以安全地否定原假设。 下面的代码对给定数据帧中时间序列的所有可能组合实现格兰杰因果关系检验,并将每个组合的 p 值存储在输出矩阵中。 from statsmodels.tsa.stattools import grangercausalitytests maxlag = 12 test = 'ssr_chi2test' def grangers_causation_matrix(data, variables, test='ssr_chi2test', verbose=False): df = pd.DataFrame(np.zeros((len(variables), len(variables))), columns=variables, index=variables) for c in df.columns: for r in df.index: test_result = grangercausalitytests(data[[r, c]], maxlag=maxlag, verbose=False) p_values = [round(test_result[i+1][0][test][1],4) for i in range(maxlag)] if verbose: print(f'Y = {r}, X = {c}, P Values = {p_values}') min_p_value = np.min(p_values) df.loc[r, c] = min_p_value df.columns = [var + '_x' for var in variables] df.index = [var + '_y' for var in variables] return df grangers_causation_matrix(df, variables = df.columns)
表中的值是 P 值。 P 值小于显着性水平 (0.05),意味着零假设对应的过去值的系数是零,即 X 不导致 Y 可以被拒绝。 Data: 包含时间序列变量的df数据框 variables : list containing names of the time series variables. 那么如何阅读上面的输出呢?行是响应 (Y),列是预测变量序列 (X)。 例如,如果在(第 0 行,第 0003 列)中取值 1.2,则它是指导致 的 p 值。而 0.000 in (第 2 行,第 1 列) 是指导致 的 p 值。pgnp_x rgnp_y rgnp_y pgnp_x 那么,如何解释p值呢? 如果给定的 p 值'test_statistic':round(r[0], 4), 'pvalue':round(r[1], 4), 'n_lags':round(r[2], 4), 'n_obs':r[3]} p_value = output['pvalue'] def adjust(val, length= 6): return str(val).ljust(length) # Print Summary print(f' Augmented Dickey-Fuller Test on "{name}"', "\n ", '-'*47) print(f' Null Hypothesis: Data has unit root. Non-Stationary.') print(f' Significance Level = {signif}') print(f' Test Statistic = {output["test_statistic"]}') print(f' No. Lags Chosen = {output["n_lags"]}') for key,val in r[4].items(): print(f' Critical value {adjust(key)} = {round(val, 3)}') if p_value |
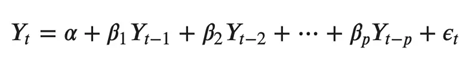
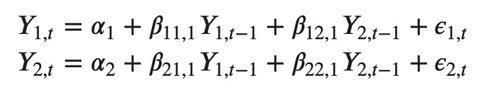
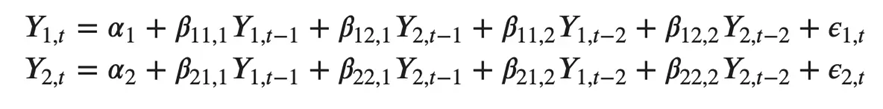
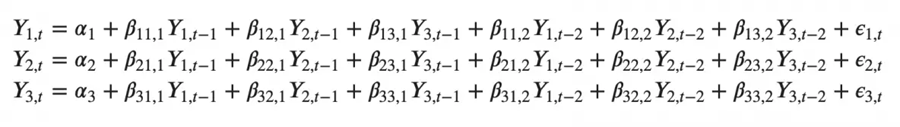
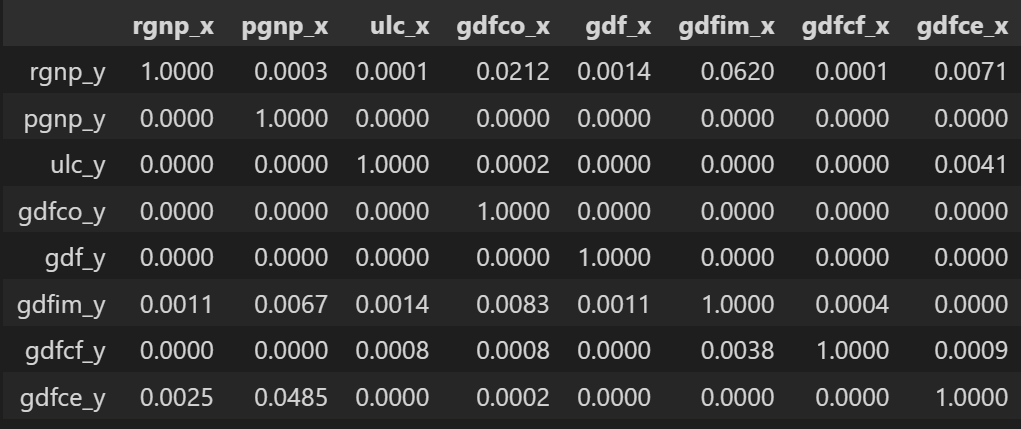 检查时间序列所有可能组合的格兰杰因果关系。行是响应变量,列是预测变量。
检查时间序列所有可能组合的格兰杰因果关系。行是响应变量,列是预测变量。【本文地址】
今日新闻 |
推荐新闻 |