python分析QQ群聊天记录全过程,从获取到可视化 |
您所在的位置:网站首页 › qq群消息删除了后还会出现部分内容 › python分析QQ群聊天记录全过程,从获取到可视化 |
python分析QQ群聊天记录全过程,从获取到可视化
|
随着社交媒体的兴起,QQ群成为了人们交流的重要平台,而提取这些数据可以帮助我们了解用户关注的重点和行为,那么如何获取QQ群聊天记录呢?如何对其进行处理并分析呢? 这是一套完整的流程,从选定的QQ群中获取记录,并对其进行处理及可视化。 其中包括: 共有多少人发过言,分别是谁 谁发表的言论最多 聊天密度周、日期、小时分布 活跃天数最多的用户(在群里说话天数最多的用户) 用户连续活跃天数(用户在群里连续说话天数) 每个用户在群里连续说话最长天数以及时间段 群里聊的最多的话题 目录 1 聊天记录获取2 聊天记录读取并查看3 数据处理3.1 使用正则提取信息3.2 拆分记录头并处理记录内容3.2.1 将日期、用户名、QQ号分离出来3.2.2 处理内容3.2.3 删除无用内容 4 探索分析4.1 共有多少人发过言,分别是谁4.2 谁说话做多,说了什么4.3 聊天密度分布4.3.1 聊天密度周分布4.3.2 聊天密度日期分布4.3.3 聊天密度小时分布 4.4 在群里说话天数最多的用户4.5 用户在群里连续说话天数4.6 每个用户在群里连续说话最长天数以及时间段4.6 群里聊的最多的话题 1 聊天记录获取 选中需要进行分析的群聊,鼠标右击——查看消息记录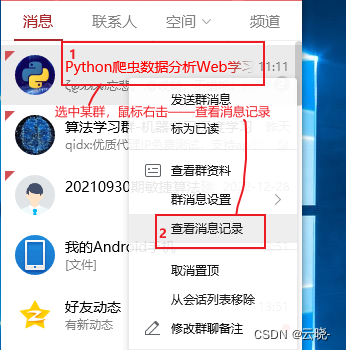 在“消息管理器”中,在选中的群上面右击——导出消息记录 在“消息管理器”中,在选中的群上面右击——导出消息记录 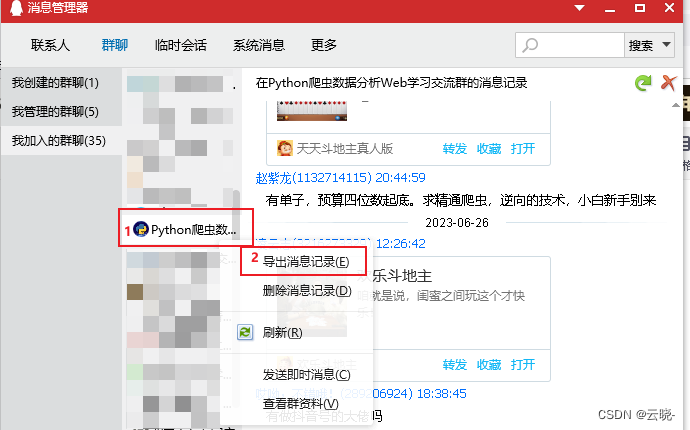 将消息记录保存为txt文件 将消息记录保存为txt文件 ![[点击并拖拽以移动]](https://img-blog.csdnimg.cn/5b49a8fc5dac4682b8bcb2c021e43a5f.png) 2 聊天记录读取并查看
import pandas as pd
import numpy as np
#上下文管理语句
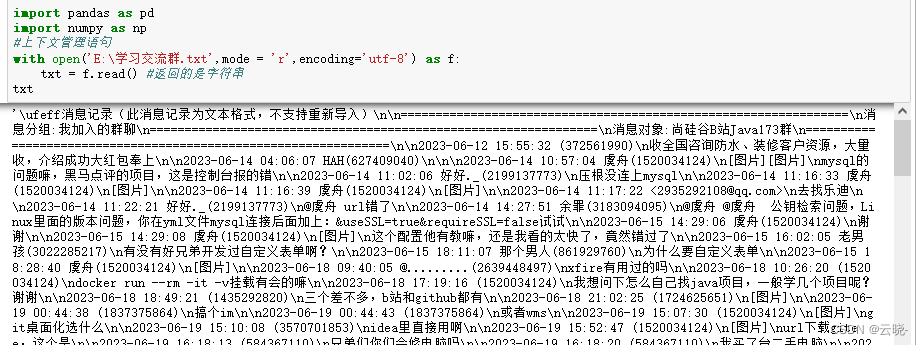
with open('E:\学习交流群.txt',mode = 'r',encoding='utf-8') as f:
txt = f.read() #返回的是字符串
txt #所有内容组成的字符串
2 聊天记录读取并查看
import pandas as pd
import numpy as np
#上下文管理语句
with open('E:\学习交流群.txt',mode = 'r',encoding='utf-8') as f:
txt = f.read() #返回的是字符串
txt #所有内容组成的字符串
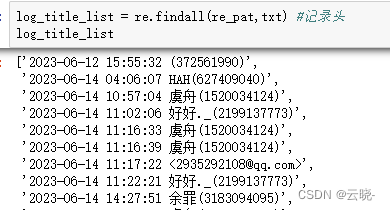
从源文件中我们可以看到内容中有以下几部分且比较直观,时间、用户名、QQ号以及聊天内容,而python读取的文件内容看起来极不方便。 为了后面更好的分析探索数据,我们需要将读取到的字符串进行处理,存储为dataframe import re #正则表达式 re_pat = '[\d-]{10}\s[\d:]{8}\s.*[\)>]'#数字或者'-'共出现10位,\s(匹配任意的空白符)分开,数字或':'共8位,\s分开,任意字符以')'或'>'结尾 log_title_list = re.findall(re_pat,txt) #记录头 log_title_list
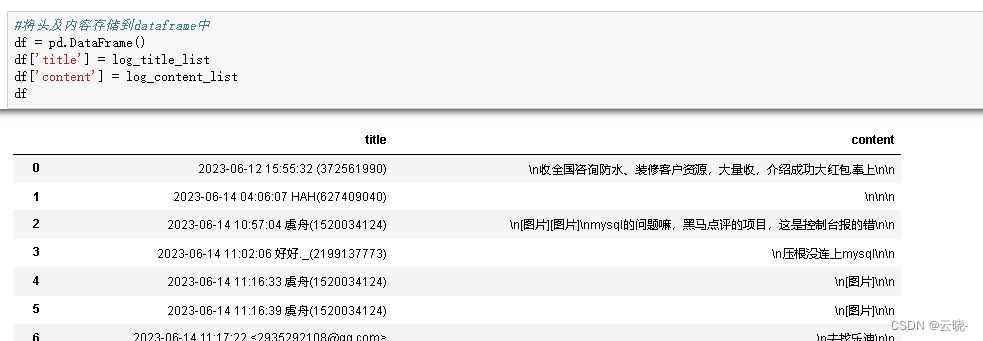
两个数据量并不一致,因为内容导出时,会有最前面的一行消息记录故需要做删除处理 #头与内容数量应保持一致,现发现内容多1,是因为多了第1行 log_content_list.pop(0) #删除第一行 len(log_content_list)
删除后,记录头与记录内容的数量已一致,将其存储到dataframe中 #将记录头及记录内容存储到dataframe中 df = pd.DataFrame() df['title'] = log_title_list df['content'] = log_content_list df
|



【本文地址】
今日新闻 |
推荐新闻 |