TensorRT(二)使用教程 |
您所在的位置:网站首页 › pytorch模型转ncnn › TensorRT(二)使用教程 |
TensorRT(二)使用教程
|
Jetson Xavier NX CUDA、Cudnn、TensorRT与pytorch1 NX系统烧录 如果买来的板子已经装好系统请忽略。直接df查看内存,如果只有16G,建议加装固态。 df -h第一步:首先装备一台Ubuntu18.04的电脑,也可以用虚拟机,但是虚拟机可能会比较慢。第二步:安装SDKmanager,需要NVIDIA的账号密码,注册一个就行。  安装: sudo dpkg -i xxxx.deb可能会报错。Errors were encountered while processing sudo apt-get update sudo apt-get upgrade sudo apt --fix-broken install第三步:系统烧录,首先进入SDKmanager,按着Rec,再点击Rst,进入Recovery模式,下图红框内会自动检测到板子型号。 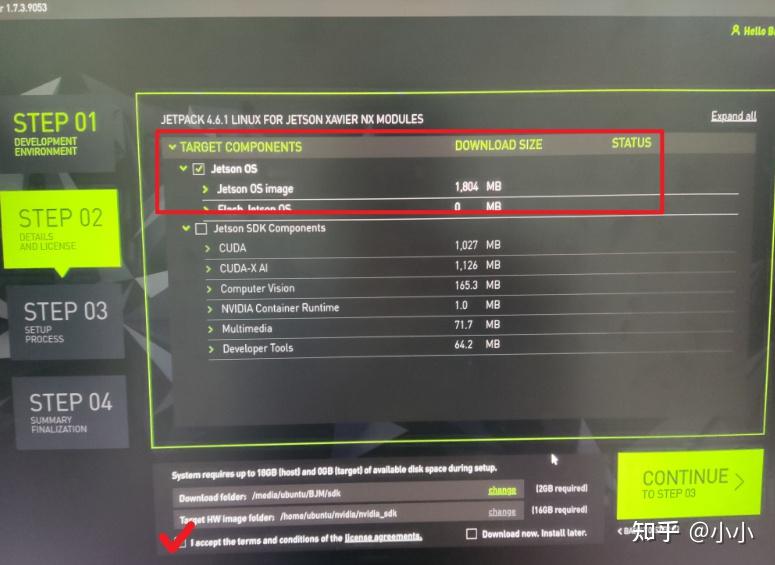 第四步:选择好之后进入STEP 03,因为NX的内置sd卡只有16GB,所以只能安装裸系统,不能有其他复杂的包,选择Jetson OS,进行下载和安装。 第四步:选择好之后进入STEP 03,因为NX的内置sd卡只有16GB,所以只能安装裸系统,不能有其他复杂的包,选择Jetson OS,进行下载和安装。 第五步:等待下载和安装结束。 第五步:等待下载和安装结束。 烧录完成,点击FINISH,然后关闭软件,这是系统已经烧录进NX的内置SD卡。2 迁移系统到固态格式化安装好的SSD固态硬盘,打开菜单并进行搜索磁盘(disk),然后打开。在终端输入命令克隆项目,git clone https://github.com/jetsonhacks/rootOnNVMe.git下载好之后切换输入cd rootOnNVMe切换目录,然后再输入bash ./copy-rootfs-ssd.sh
# 将源文件复制到SSD固态硬盘,就完成了系统的迁移。迁移好之后,还需要将SSD设置为第一启动盘,系统才能从SSD启动,输入bash ./setup-service.sh
# 重启生效,至此,整个系统安装完成,并且已经迁移到SSD固态。 烧录完成,点击FINISH,然后关闭软件,这是系统已经烧录进NX的内置SD卡。2 迁移系统到固态格式化安装好的SSD固态硬盘,打开菜单并进行搜索磁盘(disk),然后打开。在终端输入命令克隆项目,git clone https://github.com/jetsonhacks/rootOnNVMe.git下载好之后切换输入cd rootOnNVMe切换目录,然后再输入bash ./copy-rootfs-ssd.sh
# 将源文件复制到SSD固态硬盘,就完成了系统的迁移。迁移好之后,还需要将SSD设置为第一启动盘,系统才能从SSD启动,输入bash ./setup-service.sh
# 重启生效,至此,整个系统安装完成,并且已经迁移到SSD固态。注意:迁移之后原sd卡的系统不能擦除,否则会无法启动。 然后开始安装CUDA,Cudnn,TensorRT等组件  至此,安装完成! 在这个过程中可能会报错,access to apt repository check failure. 还有可能的报错:sudo apt update报错: Could not get lock /var/lib/dpkg/lock-frontend 3 检查CUDA,CUDNN,TensorRT检查cuda nvcc -V验证cudnn: whereis cudnn_version.h # /usr/include/cudnn_version.h cat /usr/include/cudnn_version.h | grep CUDNN_MAJOR #define CUDNN_MAJOR 8 #define CUDNN_VERSION (CUDNN_MAJOR * 1000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL)如果没能正常返回的话,手动安装 可以先查看仓库提供的cuDNN有哪些: sudo apt-cache policy libcudnn8由于Jetson Xavier NX使用JetPack4.6.2安装Cuda-10.2之后需要cudnn8.2.1.32-1+cuda10.2版本,根据提示进行手动安装 sudo apt-get install libcudnn8=8.2.1.32-1+cuda10.2再次验证: whereis cudnn_version.h # /usr/include/cudnn_version.h cat /usr/include/cudnn_version.h | grep CUDNN_MAJOR #define CUDNN_MAJOR 8 #define CUDNN_VERSION (CUDNN_MAJOR * 1000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL)p至此,CUDA和CUDNN彻底安装成功!!!! 查看tensorrt是否安装成功: python3 import tensorrt安装成功! 4 安装torchtorch安装下载torch:  直接安装torch会报错,首先安装Cpython pip3 install Cpython sudo pip3 install torch-1.7.0-cp36-cp36m-linux_aarch64.whl检查torch安装是否成功: python3 import torchImportError: libopenblas.so.0: cannot open shared object filesudo apt-get install libopenblas-dev安装torchvision# 安装一些必要的包 sudo apt-get install libjpeg-dev zlib1g-devpytorch与torchvision对应关系:  下载torchvision:GitHub - pytorch/vision at v0.9.0 配置: sudo vi ~/.bashrc安装torchvision cd torchvision export BUILD_VERSION=0.9.0 sudo python3 setup.py install测试torchvision: import torchvision导入 torchvision 时报错如下: SyntaxError: future feature annotations is not defined在安装torchvision的时候会自动安装 pillow 9.2.0版本,这时候pillow 的版本过高,卸载pillow重新装8.4.0版本 pip3 install pillow==8.4.0再次验证: import torchvision print(torch.__version__)至此,torch和torchvision安装完毕。 联合测试: import torch import torchvision print(torch.cuda.is_available())5 TensorRT预习模型部署其实就是采用推理后端或推理框架进行模型转换 CPU端:ONNXruntime,OpenVINO,libtorch,Caffe,NCNNGPU端:TensorRT,OpenPPL,AITemplateONNX是一种针对机器学习所涉及的开放式文件格式,用于存储训练好的模型。ONNX的规范及代码由微软、亚马逊、Facebook和IBM公司共同开发。  使用TensorRT进行嵌入式部署 训练好自己的模型,需要tensorRT转换,正常来说Pytorch->ONNX->TensorRT,但是这样会经过ONNX这个中间模型结构,可能会对最终精度产生不确定性,也可以直接从pytorch转为TensorRT, torch2trttorch.fx2trttorchscript2trt这是因为对于pytorch框架支持比较好,所以能一步到位,对于一些新框架,可能要是要走ONNX这个路。 自定义插件 如果模型中保存TensorRT不支持的算子,就需要自己实现cuda操作并且集成到TensorRT中。可以生成插件的工具: TensorRT需要输入网络的结构和参数,支持三种转换入口: TF-TRT,要求TensorFlow模型ONNX模型格式TensorRT API手动搭建模型,然后吧参数加载进去第一种不够灵活,第三种比较麻烦。ONNX是一个通用的神经我哪里过格式,.onnx文件内包含了网络参数和结构。ONNX格式还没有被优化,只是被转换为统一形式,需要再使用TensorRT将其优化成TensorRT Engine,优化参数也在这一步指定。得到的这个Engine需要使用TensorRT Runtime API调用。 所以第二种方法的完整流程: 将模型导出成ONNX格式把ONNX格式输入给TensorRT并指定优化参数使用TensorRT优化得到TensorRT Engine使用TensorRT Engine进行inference5.1 onnx转换pytorch自带导出方法torch.onnx.export; Tensorflow推荐使用这个 https://github.com/onnx/tensorflow-onnx,从 checkpoint (.meta 后缀)导出只需要 python -m tf2onnx.convert --checkpoint XXX.meta --inputs INPUT_NAME:0 --outputs OUTPUT_NAME:0 --output XXX.onnx这里一定要注意 INPUT_NAME 和 OUTPUT_NAME 有没有写对,它决定了网络的入口和出口,转换 ONNX 错误/导出 Engine 错误很有可能是这个没指定对。不确定的话可以用 onnxruntime 看一看对不对. import onnxruntime as rt sess = rt.InferenceSession(onnx_model_path) inputs_name = sess.get_inputs()[0].name outputs_name = sess.get_outputs()[0].name outputs = sess.run([outputs_name], {inputs_name: np.zeros(shape=(batch_size, xxx), dtype=np.float32)})还可以在这个网站可视化导出的 ONNX:https://netron.app/ 5.2 TensorRT优化经过TensorRT加速的模型速度能够得到提升,但精度如何,还是调用TensorRT的API: 可以使用C++API,Python API,TF_TRT Runtime,因为TF_TRT有局限性,C++API比Python API块。 |
【本文地址】
今日新闻 |
推荐新闻 |