【深度学习】U |
您所在的位置:网站首页 › pytorch分割框架 › 【深度学习】U |
【深度学习】U
|
文章目录
前言一、U-net网络结构复现(上采样部分采用转置卷积nn.ConvTranspose2d)1.1、整体结构介绍1.2、encoder部分实现(左边网络部分)1.3、decoder部分实现(右边网络部分)1.4、整个网络搭建
二、U-net网络结构复现(上采样部分采用上采样nn.Upsample)
前言
U-net论文地址:U-net论文 参考的一个还不错的开源项目地址:U-net开源项目地址 参考视频:视频1 视频2 一、U-net网络结构复现(上采样部分采用转置卷积nn.ConvTranspose2d) 1.1、整体结构介绍首先我们看看论文里面的网络结构: 左边的网洛其实和VGG16比较类似,接下来我们具体看一下每部分的构造:
1)上图中,黄色框里为连续两次的311卷积(当然弄310卷积也可),我们可以定义为如下代码: #搭建双倍卷积块 class doubleconv(nn.Module): def __init__(self,in_channels,out_channels): super(doubleconv,self).__init__() self.conv2=nn.Sequential( nn.Conv2d(in_channels,out_channels,3,1,1,bias=False), nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True), nn.Conv2d(out_channels, out_channels, 3, 1, 1,bias=False), nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True), ) def forward(self, x): return self.conv2(x) #更加简洁这种打黄色的部分在左边网络中出现了5次,右边的网络出现了4次 2)这种双倍卷积块,加上一个向下2倍池化,就可以合成我们红色框里的内容了: #搭建下采样模块(里面包含了双倍卷积块) class down(nn.Module): def __init__(self,in_channels,out_channels): super(down, self).__init__() self.pool_conv2=nn.Sequential( nn.MaxPool2d(2), doubleconv(in_channels,out_channels) ) def forward(self,x): x=self.pool_conv2(x) return x 1.3、decoder部分实现(右边网络部分)3)再看右边的网络,一个向上的311转置卷积,再来一个双倍卷积块,就能合成紫色框里的内容了: #搭建上采样模块(里面包含了双倍卷积块) class up(nn.Module): def __init__(self,in_channels,out_channels): super(up, self).__init__() self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2) self.conv = doubleconv(in_channels, out_channels) def forward(self,x1,x2): x1=self.up(x1) diffY = x2.size()[2] - x1.size()[2] diffX = x2.size()[3] - x1.size()[3] x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2, diffY // 2, diffY - diffY // 2]) x = torch.cat([x2, x1], dim=1) x=self.conv(x) return x好了,这部分的代码是有点绕的,突然多了很多看不懂的东西出来,我们一步步看: 首先是 self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2) self.conv = doubleconv(in_channels, out_channels)明明这里前面nn.ConvTranspose2dd(in_channels, in_channels // 2, kernel_size=2, stride=2)已经将通道数减半了,为什么后面使用双倍卷积块时,初始的通道块依然是in_channels呢? 我们看看现场图,以最下面的灰色箭头为例子吧: 然后是 diffY = x2.size()[2] - x1.size()[2] diffX = x2.size()[3] - x1.size()[3] x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2, diffY // 2, diffY - diffY // 2])为何会无缘无故有这一步操作呢?: 我们再回到案发现场: 我们在实操一下代码就知道了”: import torch import torch.nn.functional as F x1=torch.rand(1,512,56,56) x2=torch.rand(1,512,64,64) diffY = x2.size()[2] - x1.size()[2] diffX = x2.size()[3] - x1.size()[3] print(x2.size()[2]) print(x1.size()[2]) print(x2.size()[3]) print(x1.size()[3]) print(diffX) print(diffY) x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2, diffY // 2, diffY - diffY // 2]) print(x1.shape) x = torch.cat([x2, x1], dim=1) print(x.shape)
4)在网络的最后,有一个1X1卷积块,用以调整最后的特征图的输出通道数 class outconv(nn.Module): def __init__(self,in_channels, out_channels): super(outconv, self).__init__() self.outconv=nn.Conv2d(in_channels, out_channels,1) def forward(self,x): return self.outconv(x)1X1卷积块不改变宽高,只改变通道数。 1.4、整个网络搭建之前的模块搭建完毕后,即可完成最后网络的搭建: class UNet(nn.Module): def __init__(self, n_channels, n_classes): super(UNet, self).__init__() self.inc = doubleconv(n_channels, 64) self.down1 = down(64, 128) self.down2 = down(128, 256) self.down3 = down(256, 512) self.down4 = down(512, 1024 ) self.up1 = up(1024, 512) self.up2 = up(512, 256) self.up3 = up(256, 128) self.up4 = up(128, 64) self.outc = outconv(64, n_classes) def forward(self, x): x1 = self.inc(x) x2 = self.down1(x1) x3 = self.down2(x2) x4 = self.down3(x3) x5 = self.down4(x4) x = self.up1(x5, x4) x = self.up2(x, x3) x = self.up3(x, x2) x = self.up4(x, x1) out = self.outc(x) return out其中n_channels是输入图片的通道数,一般我们就为3,最后n_classes为需要分类的数量,也就是最后输出的通道数。 特征融合一共进行了四次,发生在如下代码处: x = self.up1(x5, x4) x = self.up2(x, x3) x = self.up3(x, x2) x = self.up4(x, x1)我们实例化网络验证一下,假设输入的图像为3通道的572X572图像,我们最后分类的个数为2: unet=UNet(3,2) A =torch.rand(1,3,572,572) B=unet(A) print(B.shape)最后输出的形状为 这个下次来写,要赶回去洗头了。 |
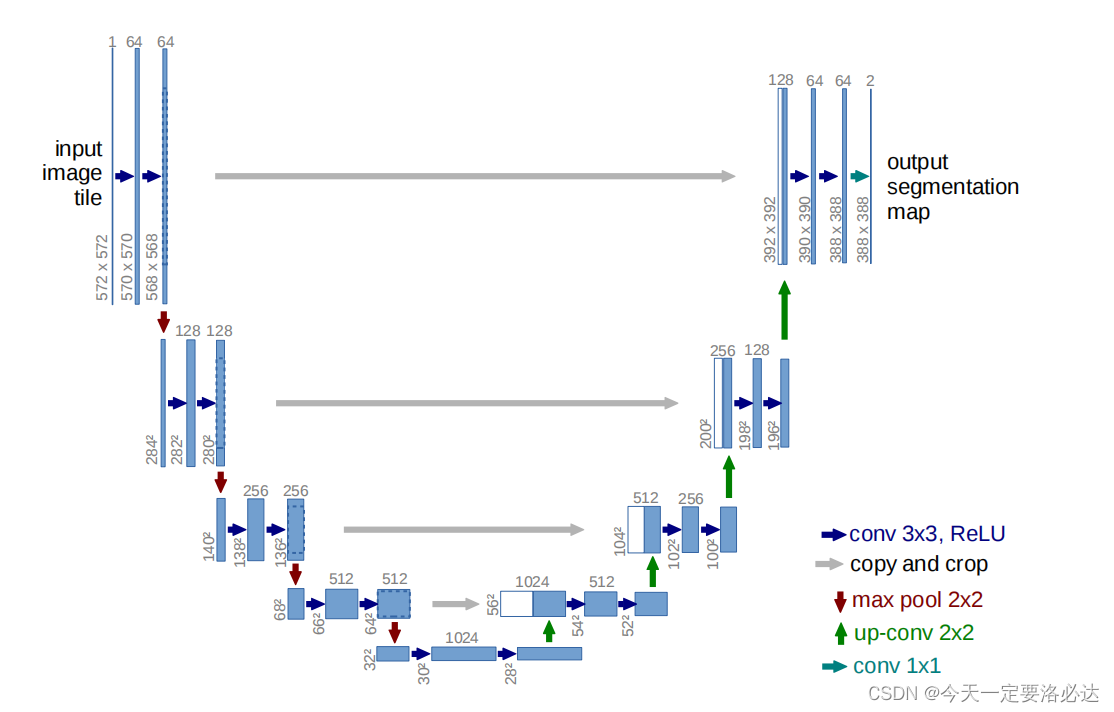 U-net网络是典型的encoder-decoder,整个呈U字形 1)左边的网络,随着不断向下,宽高减小,通道数增加 2)右边的网络,随着不断向上,宽高变大,通道数减少,最后恢复到和原来差不多的形状 3)最后输出的通道数是需要分类的个数 4)网络里使用的都是3X3卷积,如果想使得最后的输出图和原图宽高一致,可以使用311卷积(卷积核大小为3,步长1,扩充1) 5)灰色的线一共有4根,指的是“特征融合”,即两次卷积后生成的特征图与箭头指向的特征图进行torch.cat()操作,在通道维度进行拼接(dim=1,因为图片输入的维度为4,通道维数正好为1,b,c,h,w:0,1,2,3) 6) 右边decoder结构中,对宽高进行增大恢复的操作有两种:上采样nn.Upsample和转置卷积nn.ConvTranspose2d。在开源项目中,两种对应的方法代码是不一样的,解下来的部分我们首先讨论转置卷积nn.ConvTranspose2d进行扩大。
U-net网络是典型的encoder-decoder,整个呈U字形 1)左边的网络,随着不断向下,宽高减小,通道数增加 2)右边的网络,随着不断向上,宽高变大,通道数减少,最后恢复到和原来差不多的形状 3)最后输出的通道数是需要分类的个数 4)网络里使用的都是3X3卷积,如果想使得最后的输出图和原图宽高一致,可以使用311卷积(卷积核大小为3,步长1,扩充1) 5)灰色的线一共有4根,指的是“特征融合”,即两次卷积后生成的特征图与箭头指向的特征图进行torch.cat()操作,在通道维度进行拼接(dim=1,因为图片输入的维度为4,通道维数正好为1,b,c,h,w:0,1,2,3) 6) 右边decoder结构中,对宽高进行增大恢复的操作有两种:上采样nn.Upsample和转置卷积nn.ConvTranspose2d。在开源项目中,两种对应的方法代码是不一样的,解下来的部分我们首先讨论转置卷积nn.ConvTranspose2d进行扩大。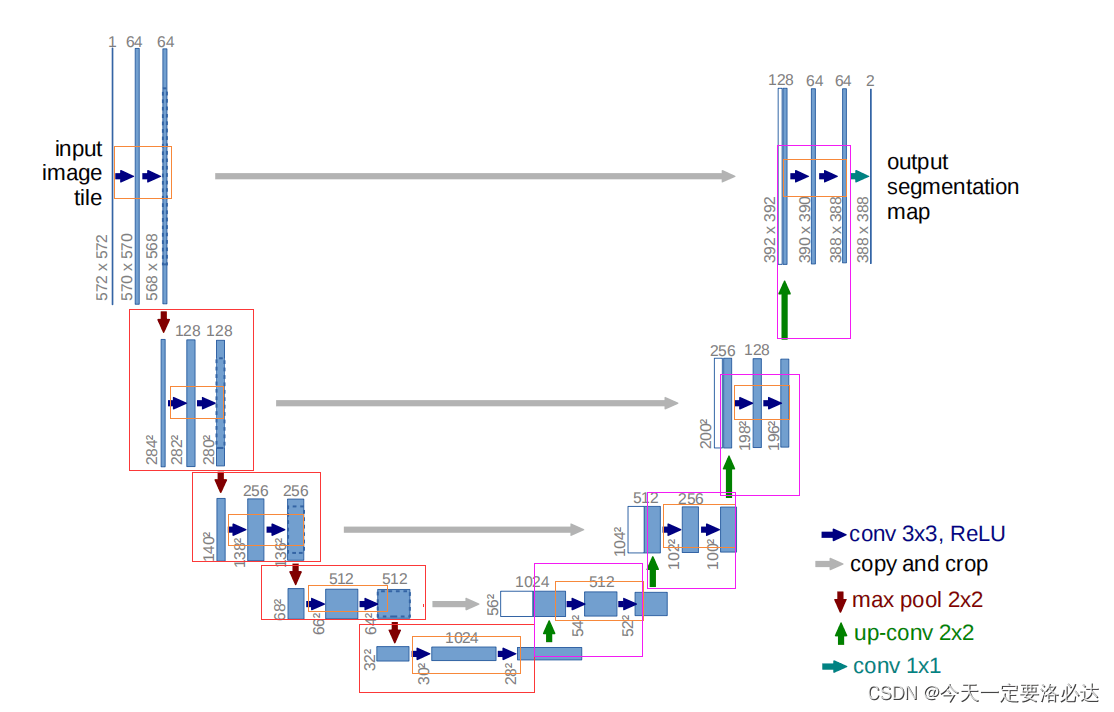
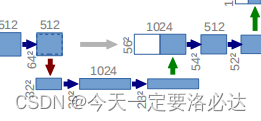 绿色的箭头正是nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2),转置卷积完成之后生成的特征图,会和之前左边网络的特征图发生特征融合,正是因为这个原因,特征图的通道数翻倍了,所以才会出现self.conv = doubleconv(in_channels, out_channels)里初始通道数依然是in_channels的情况。
绿色的箭头正是nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2),转置卷积完成之后生成的特征图,会和之前左边网络的特征图发生特征融合,正是因为这个原因,特征图的通道数翻倍了,所以才会出现self.conv = doubleconv(in_channels, out_channels)里初始通道数依然是in_channels的情况。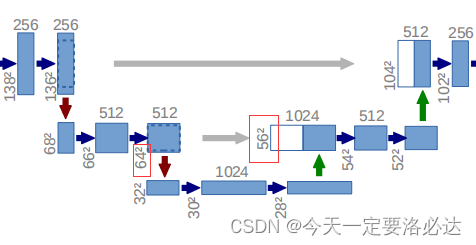 注意看我打红色圈的部分,这是两个进行特征融合的特征图宽高,一个是64X64,一个是56X56。正常情况下这肯定是无法融合的(有关特征图的融合具体可以参考我之前的博客:特征融合的方法),需要对特征图进行一定裁剪;同时左边网络是向下16倍采样,56不能被16整除,为防止后续计算出现问题,我们需要将56X56的特征图进行一定操作变成64X64 ,这段代码的作用的就是这样的。
注意看我打红色圈的部分,这是两个进行特征融合的特征图宽高,一个是64X64,一个是56X56。正常情况下这肯定是无法融合的(有关特征图的融合具体可以参考我之前的博客:特征融合的方法),需要对特征图进行一定裁剪;同时左边网络是向下16倍采样,56不能被16整除,为防止后续计算出现问题,我们需要将56X56的特征图进行一定操作变成64X64 ,这段代码的作用的就是这样的。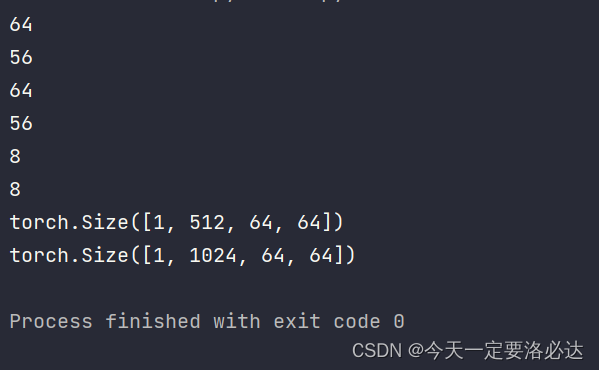 融合完成后,最后通道数翻倍了,宽高为64X64
融合完成后,最后通道数翻倍了,宽高为64X64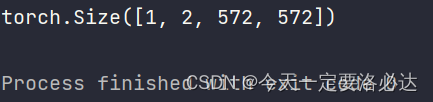 当然因为我们这里使用的是311卷积,和论文里的输出特征图有一定区别(文章里的特征图宽高不断-2,应该使用的是310卷积块)
当然因为我们这里使用的是311卷积,和论文里的输出特征图有一定区别(文章里的特征图宽高不断-2,应该使用的是310卷积块)【本文地址】
今日新闻 |
推荐新闻 |