Python数据集处理之数据归一化原理介绍及模块化代码实现 |
您所在的位置:网站首页 › python预测值反归一化 › Python数据集处理之数据归一化原理介绍及模块化代码实现 |
Python数据集处理之数据归一化原理介绍及模块化代码实现
|
1. 什么是归一化
在现实生活中,我们采集到的数据会由于含义的不同,导致数据之间差别很大,例如采集车辆行驶信息时,车辆的速度、油门踏板深度、方向盘转角等都不在一个数量级,如果直接对这些原始数据进行分析,那么往往会影响最后数据分析的结果。通常我们将车辆速度这些变量称为评价指标,不同的评价指标之间往往具有不同的量纲,为了消除指标之间量纲的影响,需要进行数据归一化处理,原始数据经过数据归一化处理后,各指标处于同一数量级,适合进行综合对比评价。 通常进行归一化的方法有两种:(1)最值归一化。(2)均值方差归一化 1.1 最值归一化最值归一化适用于数据有明显边界的情况,例如考试成绩。该方法是将所有数据映射到[0,1]之间,其计算公式如下所示: 均值方差归一化适用性要强于最值归一化,因此,如果要对数据进行归一化操作时,建议使用均值方差归一化。该方法是将原始数据集归一化为均值为0、方差1的数据集,其计算公式如下: 本文依旧以鸢尾花数据集为例,对其进行归一化处理。 2.1 最值归一化 from sklearn.datasets import load_iris from sklearn.preprocessing import MinMaxScaler # 加载鸢尾花数据集 iris = load_iris() # 调取鸢尾花样本集 X = iris.data # 创建一个最值归一化对象 scaler = MinMaxScaler() # 归一化之后,进行赋值 X_MinMax = scaler.fit_transform(X) print(X) print(X_MinMax) 2.2 均值方差归一化 from sklearn.datasets import load_iris from sklearn.preprocessing import StandardScaler # 加载鸢尾花数据集 iris = load_iris() # 调取鸢尾花样本集 X = iris.data # 创建一个均值方差归一化对象 std_scaler = StandardScaler() # 计算均值和方差 std_scaler.fit(X) # 归一化转化 X_std = std_scaler.transform(X) print(X_std) 3. 结果输出由于篇幅有限,本文只列举部分结果。 3.1 原始数据
|
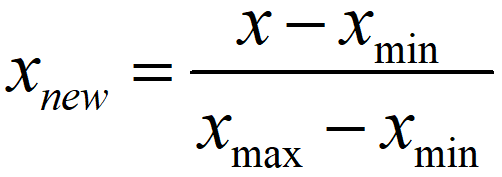
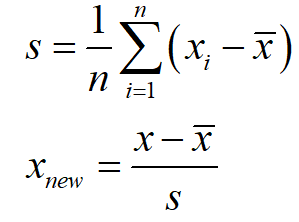 式中,s为方差。
式中,s为方差。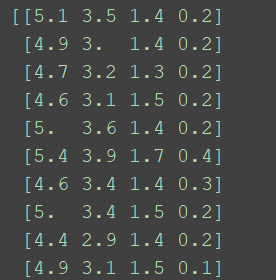


【本文地址】
今日新闻 |
推荐新闻 |