《我不是药神》豆瓣影评文本分析 |
您所在的位置:网站首页 › python进行文本分析的结论分析怎么写 › 《我不是药神》豆瓣影评文本分析 |
《我不是药神》豆瓣影评文本分析
|
《我不是药神》影评文本分析
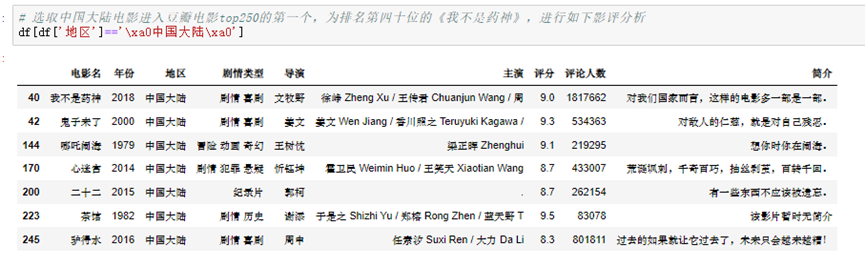
对于某一话题的评论进行文本分析,主要为文本数据,进行中文分词、关键词提取、词性句法分析等简单数据分析处理。 1.1 问题确定对豆瓣电影Top250中由中国大陆制片排名最前(第40名)的电影——《我不是药神》,如图1.1所示,进行电影评论文本综合性分析,包含对评论中关键词词频统计、词性分析并可视化展示等,通过分析能够得到该电影跻身豆瓣Top250、成为中国大陆制片排名最高影片的原因,综合得出大众化总评。 图1.1 选取数据 1.2 数据准备 1.2.1 数据爬取爬取豆瓣网《我不是药神》中的短评前15页评论,如图1.2.1(1)所示,共300条数据,如图1.2.1(2)所示,并写入txt文件,如图1.2.1(3)所示。
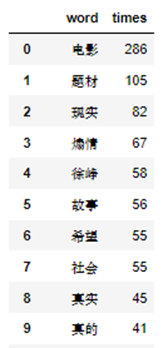
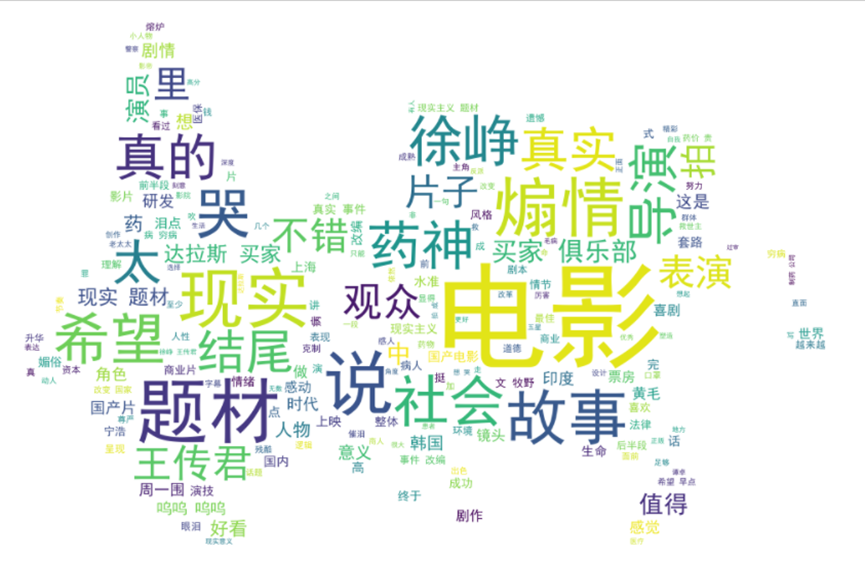
图1.2.1(1) 《我不是药神》部分短评 图1.2.1(2) 爬取数据 图1.2.1(3) 数据txt文件展示 1.2.2 问题处理 在爬取的过程中,遇到了如图1.2.1(4)报错问题,通过查找资料得知虽然我在爬虫代码中设置了UserAgent池来防止反爬虫,但由于我多次访问登录或者这次爬取时没有登录用户,可能IP被封锁,获取的cookie不是实时的,理清解决思路得以成功处理。 图1.2.2 报错问题 1.3 数据探索 1.3.1 数据清洗使用jieba库,将评论文本数据进行中文分词处理,并使用通用停用词表,去除评论中关联词等非关键词以及标点符号、空格、回车等标符,写入txt文件,结果如图1.3.1所示。 图1.3.1 分词处理结果 1.3.2 数据分析 1. 评论词频统计 对评论数据分词后提取的关键词进行词频统计,运用词语前10个结果如图2.3.2(1)所示,并生成词云可视化,如图1.3.2(2)所示,可以看出人们多从电影的题材、意义、演员等方面来评价《我不是药神》这部电影,根据词频说明该电影选择的题材改编自真实故事,非常现实,很贴近人们的社会生活,具有真实性,徐峥、王传君等演员的演技及导演获得人们更多的评价,所表现的社会现实意义得到观众的认可与接受,值得让更多的人看到。 图1.3.2(1) 前10个高频词结果展示
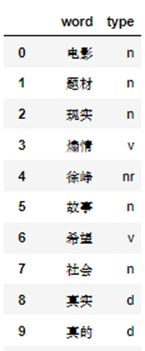
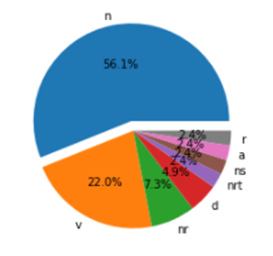
图1.3.2(2) 词频统计词云结果展示 2. 评论词性标注 使用jieba.posseg库做带有词性标注的分词,并通过循环得到每个分词的词语和类别结果,部分结果及词性大致分布如图1.3.2(3)所示,可参照图1.3.2(4)进行理解。从图中可以看出人们的评论关键词多出现在名词、动词、人名中,更能体现人们评论的中心思想。
图1.3.2(3) 词性标注部分展示
图1.3.2(4) 词性标注部分分类 1.4 评论文本分析结论综上所述,《我不是药神》这部电影于2018年7月上映,电影在大众心中的地位、在豆瓣排名第40位绝非偶然,毕竟电影是对于社会事件的回应,真正的现实主义,并非仅仅只是一个社会事件。该影片中在情与理之间讲述生死,将中国人普遍的道德焦虑置于影片之中,情理间体现了道德的无助,生死间使情感借以表达与依托,更易引起人们的共鸣,也更值得让更多人看到。 这次的数据只有300条,可能缺乏结论得出的可靠性,但都是豆瓣最新评论数据,具有时效性、真实性。实验对评论文本分析时可以考虑建立LDA等情感分析模型对评论数据进行情感性分析,考虑的因素会更多,但此次实验的结论也可以作为大众电影总评为更多的观影者和电影制片方参考。 1.5 附部分代码1. 中文分词 import jieba # 创建停用词list def stop_wordslist(filepath): stop_words = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()] return stop_words # 对评论数据进行分词 def seg_sentence(sentence): # 使用jieba库进行分词 sentence_seged = jieba.cut(sentence.strip()) # 加载停用词 stopwords = stop_wordslist('stop_words.txt') outstr = '' # 去除停用词 for word in sentence_seged: if word not in stopwords: if word != '\t': outstr += word outstr += " " return outstr m = open('我不是药神.txt', 'r', encoding='utf-8') n = open('我不是药神(关键词).txt', 'w', encoding='utf-8') for line in inputs: line_seg = seg_sentence(line) # 这里的返回值是字符串 n.write(line_seg + '\n') m.close() n.close() # 显示处理后的文本数据 fname = '我不是药神(关键词).txt' file = open(fname,'r', encoding='utf-8') for eachLine in file: print(eachLine) file.close()
2. 评论词频统计 import pandas as pd # 对分词后提取的关键词进行词频统计 # 读取处理后的文件 file = open(fname, "r", encoding='utf-8').read() # 进行分词 words =jieba.lcut(file) counts ={} for word in words: # 去掉空格等其他单字符 if len(word) == 1: continue else: # 计数 counts[word] = counts.get(word,0) + 1 # 把对象对象转化为列表形式,利于下面操作 items =list(counts.items()) # sort() 函数用于对原列表进行排序,如果指定参数,则使用比较函数指定的比较函数 # reverse 排序规则,reverse = True 降序, reverse = False 升序(默认) # key 是用来比较的参数 items.sort(key=lambda x:x[1], reverse=True) df=pd.DataFrame(columns=['word', 'times']) x=[] y=[] # 显示前20个高频词与其频数 for i in range(40): word, count =items[i] x.append(word) y.append(count) df['word'] = x df['times'] = y print(df)
3. 评论词性分析 # 使用jieba.posseg做带有词性标注的分词 import jieba.posseg as pseg # 进行词性标注 # 使用jieba.posseg做带有词性标注的分词,并通过循环得到每个分词的词语和类别结果 df1=pd.DataFrame(columns=['word', 'type']) a=[] b=[] for i in range(len(df)): words = pseg.cut(df.ix[i][0]) ##我这里对第一列即A列进行分词 for word,flag in words: a.append(word) b.append(flag) df1['word']=a df1['type']=b print(df1)
|



【本文地址】
今日新闻 |
推荐新闻 |