HDF5数据的打包与使用(以图像数据为例) |
您所在的位置:网站首页 › python读取hdf5气象文件 › HDF5数据的打包与使用(以图像数据为例) |
HDF5数据的打包与使用(以图像数据为例)
|
文章目录
1 什么是HDF5数据2 HDF5数据格式的生成3 HDF5数据的查看
注:此篇内容主要作为使用PyTorch构建GAN生成对抗网络博客中,HDF5数据类型的补充介绍。 1 什么是HDF5数据HDF5 数据是存储在一种名为 Hierarchical Data Format version 5 (HDF5) 的二进制文件格式中的数据。这种文件格式可以用来存储大量的多维数据,并且提供了很多的功能来帮助用户组织和管理数据。 HDF5 数据文件中包含了一系列的数据集,每个数据集都是一个多维数组。数据集的维度可以是任意的数量,并且每个数据集都可以有自己的属性。这使得 HDF5 文件格式非常适合用来存储大量的数值型数据,比如图像、音频、视频等。 以CelebA数据集为例,在官网下载时,我们将会得到一个压缩包,里面包含人脸图片与属性标注,如果希望将人脸图片转入到HDF5中的数据集中,可参考的代码如下: hdf5_file = '你希望的h5py存放地' Celeba_file='你的数据存放地' total_images = 10000 # 你需要打包的图片数量 with h5py.File(hdf5_file, 'w') as hf: count = 0 with zipfile.ZipFile(Celeba_file, 'r') as zf: for i in zf.namelist(): if (i[-4:] == '.jpg'): # 图片提取 ofile = zf.extract(i) img = imageio.imread(ofile) os.remove(ofile) # 添加数据到HDF5文件 hf.create_dataset('img_align_celeba/' + str(count) + '.jpg', data=img, compression="gzip", compression_opts=9) # 停止控制 if (count == total_images): break对上面的代码进行一下讲解:首先我们打开了你下载的人脸数据 zip 文件(官方提供的数据格式就是压缩包的形式,我们下载后也不需要对其解压),并遍历文件中的所有文件名。如果文件名的扩展名是 .jpg,则提取该文件并将其读取为一个图像数组。将图像数组写入一个 HDF5 文件中,保存在你希望的h5py存放地目录下,文件名为递增的数字。 当读取了指定数量的图像时,停止读取过程。之所以设置了停止功能,是因为这个数据集的数据量比较大,有时实验并不需要数据集的全部内容。在处理大型数据集时,也可以添加计数器功能,每处理一定量的文件进行打印进程。 3 HDF5数据的查看打开数据集可以使用常规的with…as语法: with h5py.File('数据集位置.h5py', 'r') as file_object: for group in file_object: print(group)这段代码用于查看HDF5文件中的数据组名,输出是img_align_celeba,这是因为我们前面在制作HDF5文件时,指定的路径就是保存在img_align_celeba下,所以这些保存进去的数据都被认为是img_align_celeba组中的数据。 with h5py.File('数据集位置.h5py', 'r') as file_object: dataset = file_object['img_align_celeba'] image = numpy.array(dataset['1.jpg']) plt.imshow(image, interpolation='none') plt.show()前面我们制作数据集时,指定了数据集中数据的命名规则是图片序号+‘jpg’,所以可以通过类似字典的方式,打开img_align_celeba数据组中的第一张图片。再通过plt绘制出图片,以判断数据集读取是否成功。执行成功后,应该能看到如下图片: 输出的是(218, 178, 3)。说明这个图片的像素是218*178,3代表的是RGB三层数据。 |
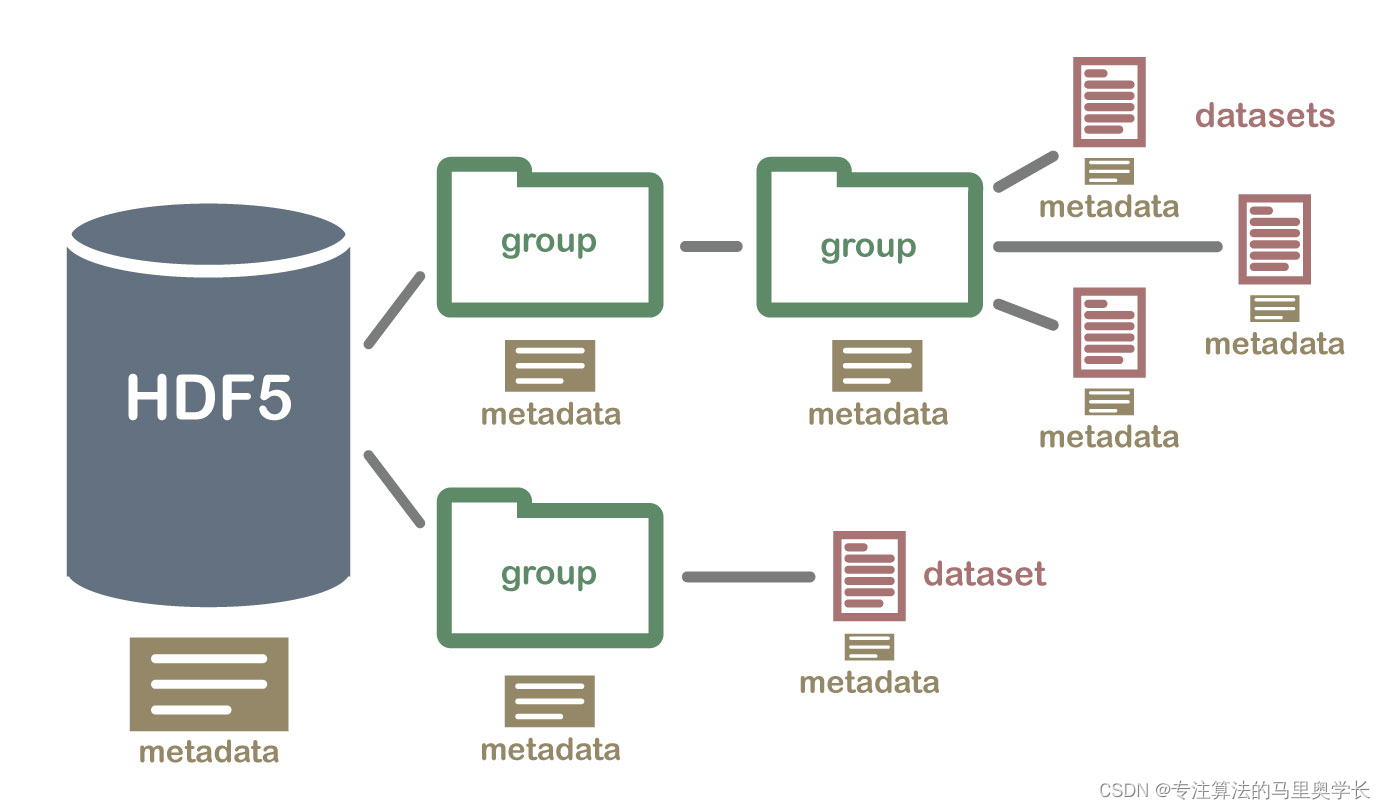 HDF5文件格式主要有以下特点:
HDF5文件格式主要有以下特点: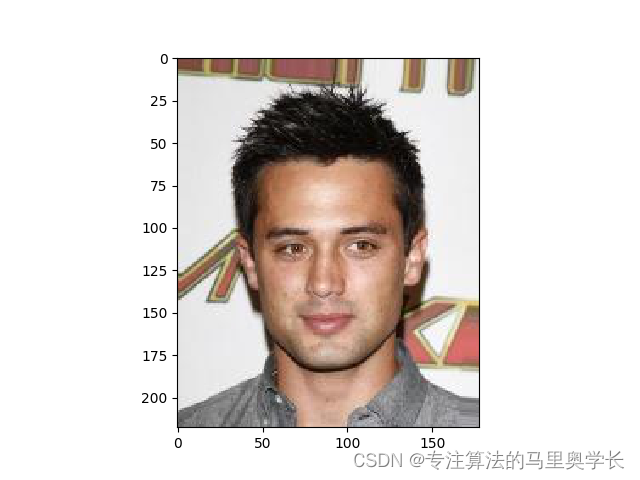 同时,我们可以看一下这个数据的大小:
同时,我们可以看一下这个数据的大小:【本文地址】
今日新闻 |
推荐新闻 |