HDF5快速上手全攻略 |
您所在的位置:网站首页 › python读取hdf5文件的数据值与属性 › HDF5快速上手全攻略 |
HDF5快速上手全攻略
|
HDF5快速上手全攻略
1. HDF5简介
Hierarchical Data Format(HDF)是一种针对大量数据进行组织和存储的文件格式。经历了20多年的发展,HDF格式的最新版本是HDF5,它包含了数据模型,库,和文件格式标准。以其便捷有效,移植性强,灵活可扩展的特点受到了广泛的关注和应用。 很多大型机构的数据存储格式都采用了HDF5,比如NASA的地球观测系统,MATLAB的.m文件,流体细算软件CDF,都将HDF5作为标准数据格式。现在HDF5还支持了大数据技术和NoSQL技术,并广泛用于科研,金融,以及其他科学和工程领域。 HDF5在技术上提供了丰富的接口,包含C,C++,Fortran, Python, Java等,能够在不同的语言间完美兼容。 当然批评者也认为HDF5格式具有以下缺点: 设计古老,定制化设置冗长尽管有150多页的公开标准,但HDF5的非官方实现非常少HDF5没有强制使用UTF8编码,因此客户为了兼容型只好采用ASCII编码存储的数据不能没有外部工具(如h5repack)的情况下自由的提取和复制。 2. HDF5在Windows上的安装和使用我们采用Windows 10 x64操作系统和Visual Studio 2015 x64作为C++编译环境进行说明,如何安装和配置HDF5,并使用HDF5静态和动态库将数据存储为HDF5格式,以及如何查看和读取这些数据。 HDF5软件的安装: 从官方网站下载下载安装包,可以32位和64位都下载安装,安装在不同的文件夹中,如Program Files和Program Files (x86)文件夹下。注意,这里添加的HDF5库的是32位的,该位数应该和要编译的程序的位数相同。将HDF5安装目录下的bin文件夹地址添加到系统的PATH变量中,用英文分号隔开Visual Studio 2015中使用HDF5需要进行的配置如下 打开Project属性页,在[配置属性]->[C/C++]选项卡中,将HDF5安装目录下的include文件夹地址填入附加包含目录项目中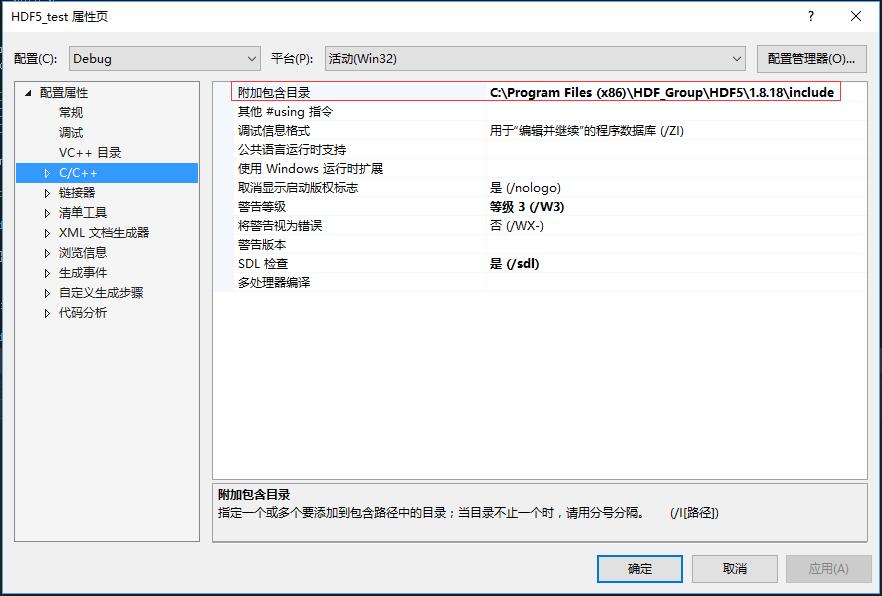 在[配置属性]->[链接器]选项卡中,将HDF5安装目录下的lib文件夹地址填入附加库目录项目中 在[配置属性]->[链接器]选项卡中,将HDF5安装目录下的lib文件夹地址填入附加库目录项目中 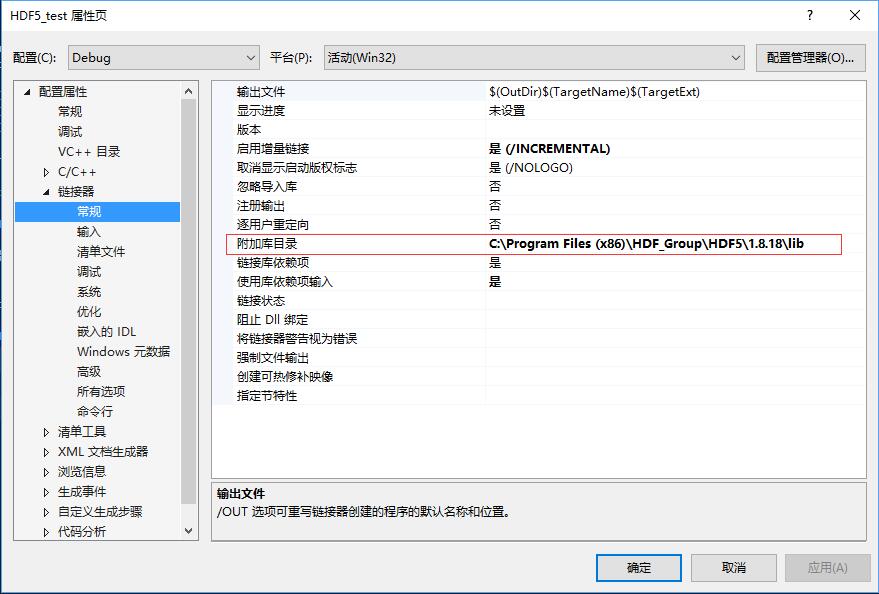 在[配置属性]->[链接器]->[输入]选项卡中,将链接的库文件添加到附加依赖项中。。这里需要主要,对于动态链接和静态链接添加的库不同
动态链接:szip.lib;zlib.lib;hdf5.lib;hdf5_cpp.lib(最后一项针对用C++方法调用HDF5的项目)静态链接:libszip.lib;libzlib.lib;libhdf5.lib;libhdf5_cpp.lib 在[配置属性]->[链接器]->[输入]选项卡中,将链接的库文件添加到附加依赖项中。。这里需要主要,对于动态链接和静态链接添加的库不同
动态链接:szip.lib;zlib.lib;hdf5.lib;hdf5_cpp.lib(最后一项针对用C++方法调用HDF5的项目)静态链接:libszip.lib;libzlib.lib;libhdf5.lib;libhdf5_cpp.lib 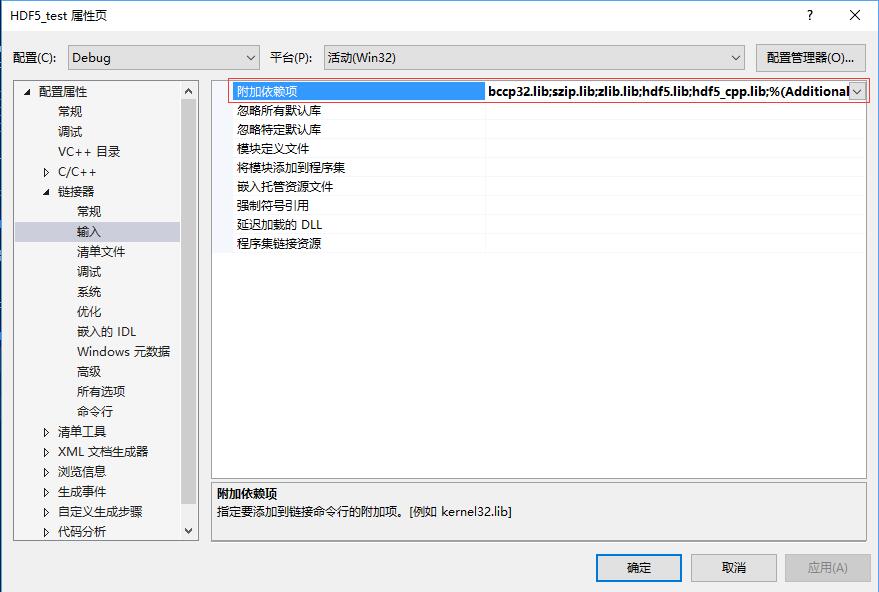 在[配置属性]->[C/C++]->[代码生成]选项卡中,调整运行库项目。动态链接采用[多线程DLL(/MD)]模式,而调试时选择采用[多线程调试DLL(/MDd)]模式。
在[配置属性]->[C/C++]->[代码生成]选项卡中,调整运行库项目。动态链接采用[多线程DLL(/MD)]模式,而调试时选择采用[多线程调试DLL(/MDd)]模式。 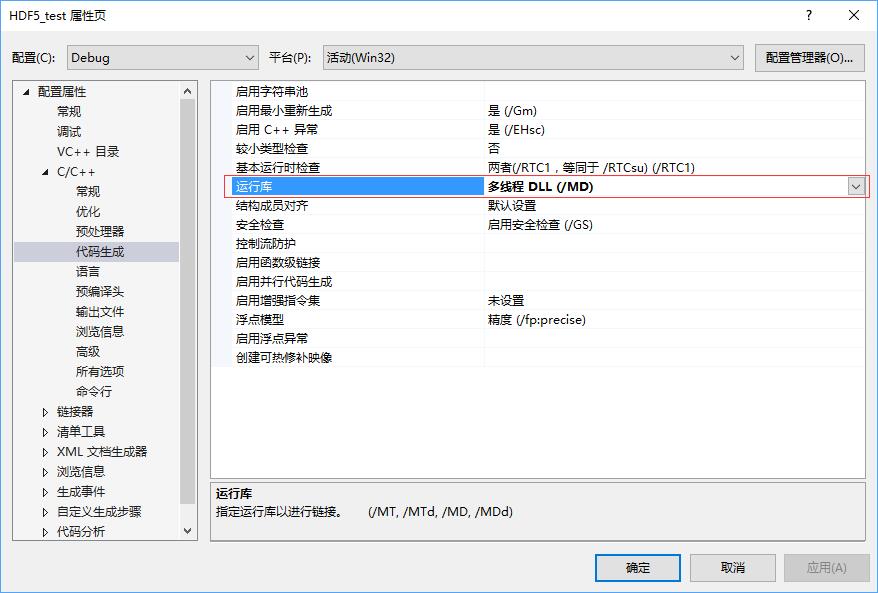 在采用动态链接时,一定注意最后在[配置属性]->[C/C++]->[预处理器]选项卡中,在预处理器定义项目中定义符号H5_BUILT_AS_DYNAMIC_LIB。否则程序有可能出先000007b错误,或者出现LINK2001无法解析的外部符号_H5T_NATIVE_DOUBLE_g等外部符号无法解析的情况。 在采用动态链接时,一定注意最后在[配置属性]->[C/C++]->[预处理器]选项卡中,在预处理器定义项目中定义符号H5_BUILT_AS_DYNAMIC_LIB。否则程序有可能出先000007b错误,或者出现LINK2001无法解析的外部符号_H5T_NATIVE_DOUBLE_g等外部符号无法解析的情况。 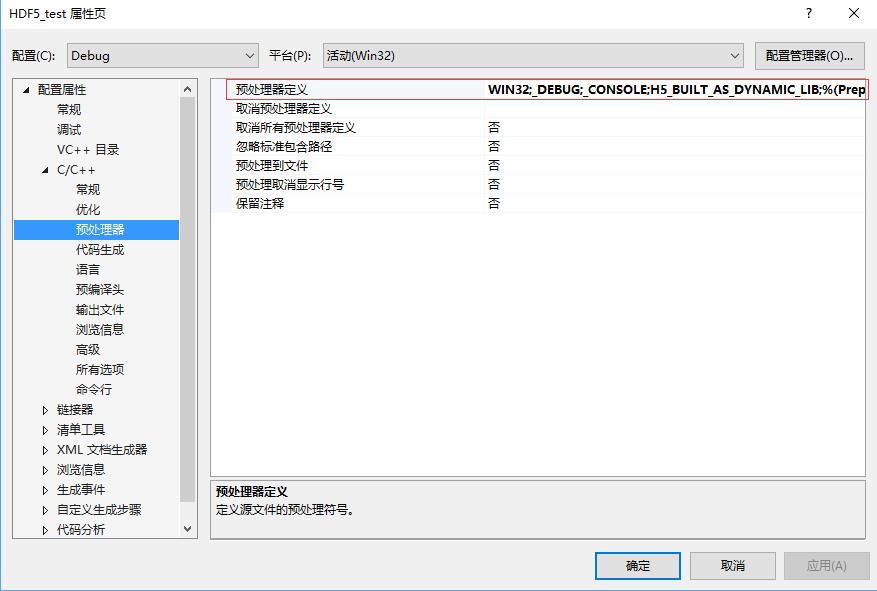
至此,我们的Visual Studio环境搭建已经完成,接下来我们开始学习HDF5库使用的学习。 3. HDF5文件结构 3.1 HDF5文件格式
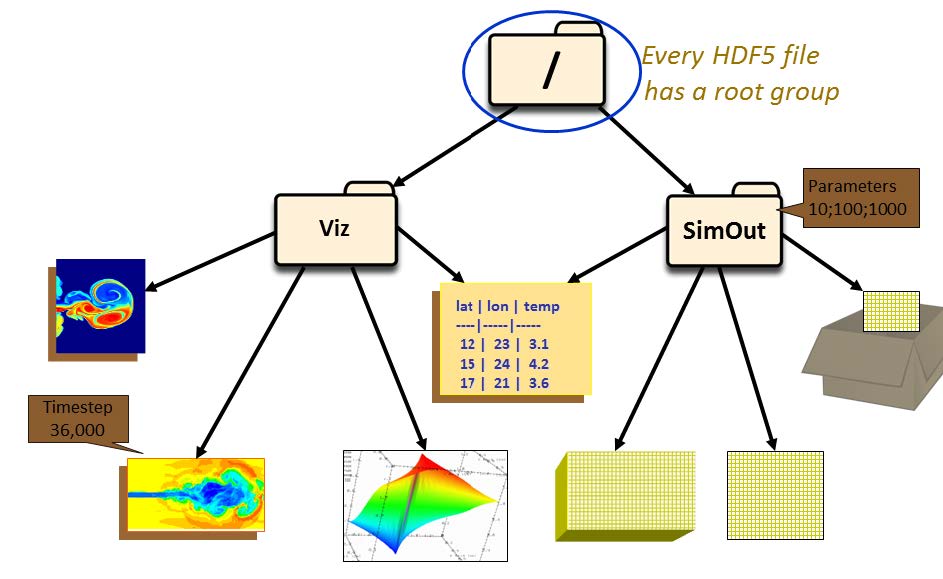
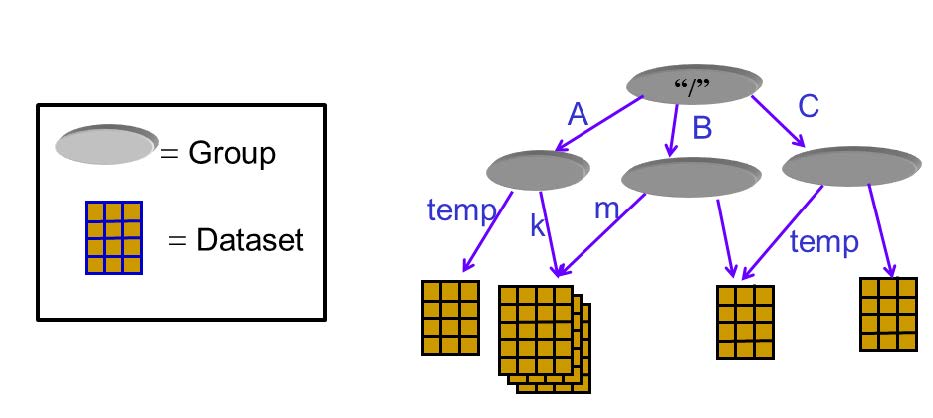
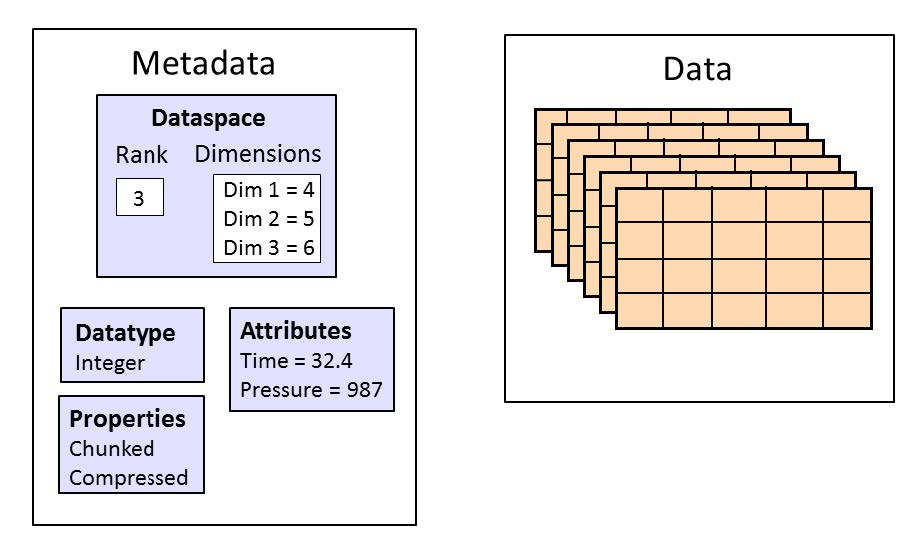
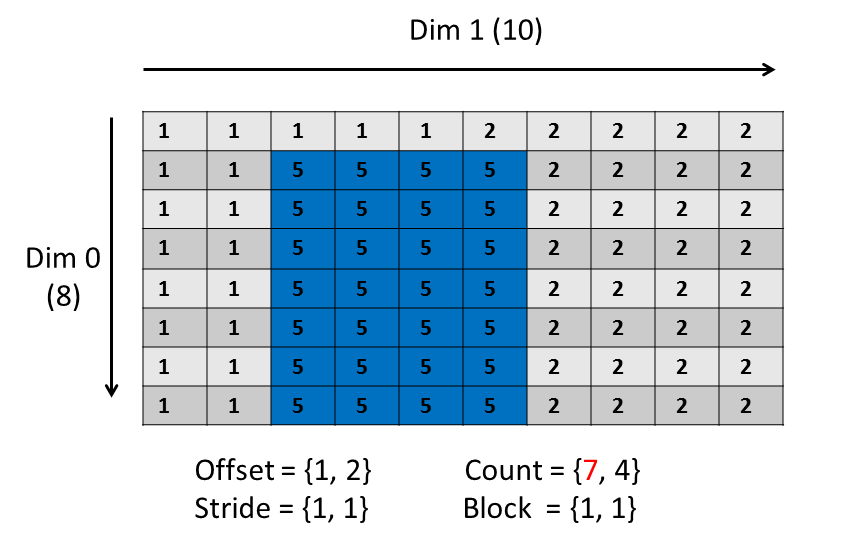
为了方便数据的组织,HDF5文件通过group的方式组织成树状结构,每个group都是树的节点。 每一个dataset包含两部分的数据,Metadata和Data。其中Metadata包含Data相关的信息,而Data则包含数据本身。 一般的操作一个HDF5对象的步骤是 打开这个对象;对这个对象进行操作;关闭这个对象。特别要注意的是,一定要在操作结束后关闭对象。因为之前的操作只是生成操作的流程,并不真正执行操作,只有关闭对象操作才会真正出发对对象进行的修改。 4.1 文件(Files)创建/打开/关闭Python代码 import h5py # 以写入方式打开文件 # r 只读,文件必须已存在 # r+ 读写,文件必须已存在 # w 新建文件,若存在覆盖 # w- 或x,新建文件,若存在报错 # a 如存在则读写,不存在则创建(默认) file = h5py.File('file.h5', 'w') file.close() # 打开文件 file_open = h5py.File('file.h5', 'r+') file_open.close()C代码 #include "hdf5.h" int main(){ // hid_t是HDF5对象id通用数据类型,每个id标志一个HDF5对象 hid_t file_id; // herr_t是HDF5报错和状态的通用数据类型 herr_t status; // 文件id = H5Fcreate(const char *文件名, // unsigned 是否覆盖的flags, // - H5F_ACC_TRUNC->能覆盖 // - H5F_ACC_EXCL->不能覆盖,报错 // hid_t 建立性质,hid_t 访问性质); file_id = H5Fcreate("file.h5", H5F_ACC_TRUNC, H5P_DEFAULT, H5P_DEFAULT); status = H5Fclose(file_id); // 打开刚建立的HDF文件并关闭 // 文件id = H5Fopen(const char *文件名, // unsigned 读写flags, // - H5F_ACC_RDWR可读写 // - H5F_ACC_RDONLY只读 // hid_t 访问性质) hit_t file_open_id; file_id = H5Fopen("file.h5", H5F_ACC_RDWR, H5P_DEFAULT); status = H5Fclose(file_id); return 0; } 4.2 群(Group)的建立Python中将文件树表述成一个dict,keys值是groups成员的名字,values是成员对象(groups或者datasets)本身。文件对象本身作为root group。 Python代码 import h5py f = h5py.File('foo.hdf5','w') f.name # output = '/' [k for k in f.keys()] # output = [] # 创建一个group # 1. 相对地址方法 grp = f.create_group("bar") grp.name # output = '/bar' subgrp = grp.create_group("baz") subgrp.name # output = '/bar/baz' # 2. 绝对地址创建多个group grp2 = f.create_group("/some/long/path") grp2.name # output = '/some/long/path' grp3 = f['/some/long'] grp3.name # output = '/some/long' # 3. 删除一个group del f['bar'] # 最终一定要记得关闭文件才能保存 f.close()在C/C++中组的创建使用一个宏H5Gcreate(),这个宏将调用不同版本的组创建函数H5Gcreate1()和H5Gcreate2(),其中1.8.x版本的宏指向H5Gcreate2()。 注意: 在C库中,group只能一层一层创建,子group只有在创建好父group后才能创建,不能一次创建多层group。 C代码 #include #include #include "hdf5.h" int main(int argc, char* argv[]) { // 打开HDF5文件 hid_t file_id; herr_t status; file_id = H5Fcreate("my_file.h5", H5F_ACC_TRUNC, H5P_DEFAULT, H5P_DEFAULT); // 创建groups hid_t group_id, group2_id; // new_group_id = H5Gcreate2(group_id, // 绝对或者相对group链接名, // 链接(link)创建性质, // group创建性质, // group访问性质); group_id = H5Gcreate(file_id, "/MyGroup1", H5P_DEFAULT, H5P_DEFAULT, H5P_DEFAULT); group2_id = H5Gcreate(group_id, "/MyGroup1/MyGroup2"), H5P_DEFAULT, H5P_DEFAULT, H5P_DEFAULT); // 上面绝对路径也可用下面的相对路径替代 //group2_id = H5Gcreate(group_id, "MyGroup2"), H5P_DEFAULT, H5P_DEFAULT, H5P_DEFAULT); //group2_id = H5Gcreate(group_id, "./MyGroup2"), H5P_DEFAULT, H5P_DEFAULT, H5P_DEFAULT); // 关闭group组 status = H5Gclose(group2_id); status = H5Gclose(group_id); // 利用H5Gopen打开一个组 // group_id = H5Gopen2(父group_id, // 绝对或者相对group链接名, // group访问性质); group_id = H5Gopen(file_id, "MyGroup1/MyGroup2", H5P_DEFAULT); status = H5Gclose(group_id); // 关闭文件,保存更改 status = H5Fclose(file_id); return 0; }那么对于一个组,我们想知道它是否存在在,应该如何检测呢?如果直接进行读取,那么HDF5会进行报错,所以,我们需要先关闭报错机制,然后进行检验。代码如下 #include #include "hdf5.h" int main(int argc, char* argv[]) { // 打开HDF5文件 hid_t file_id; herr_t status; file_id = H5Fcreate("my_file.h5", H5F_ACC_TRUNC, H5P_DEFAULT, H5P_DEFAULT); // 创建"/MyGroup1/MyGroup2" hid_t group_id, group2_id; group_id = H5Gcreate(file_id, "/MyGroup1", H5P_DEFAULT, H5P_DEFAULT, H5P_DEFAULT); group2_id = H5Gcreate(group_id, "/MyGroup1/MyGroup2"), H5P_DEFAULT, H5P_DEFAULT, H5P_DEFAULT); // 关闭group组 status = H5Gclose(group2_id); status = H5Gclose(group_id); // 检查"/MyGroup1/MyGroup2"是否存在 // 临时关闭错误堆栈自动打印功能 // herr_t H5Eset_auto2( hid_t estack_id, 要设置的错误堆栈,当前堆栈是H5E_DEFAULT // H5E_auto2_t func, 遇到错误时调用的,默认是类型转换为(H5E_auto2_t)后的H5Eprint2,将错误堆栈打印 // void *client_data 传递给错误处理函数的数据,默认是标准错误流stderr) status = H5Eset_auto(H5E_DEFAULT, NULL, NULL); // 获取组的信息 // H5Lget_info( hid_t link_loc_id, 连接(link)位置id // const char *link_name, 连接名字id // H5L_info_t *link_buff, 连接的信息结构体buffer,详见H5L_info_t // hid_t lapl_id 访问性质列表) status = H5Lget_info(file_id, "MyGroup1/MyGroup2", NULL, H5P_DEFAULT); printf("/MyGroup1/MyGroup2: "); if (status == 0) printf("The group exists.\n"); else printf("The group either does NOT exist or some other error occurred.\n"); // 检查"/MyGroup1/MyGroupABC"是否存在 status = H5Lget_info(file_id, "MyGroup1/MyGroupABC", NULL, H5P_DEFAULT); printf("/MyGroup1/GroupABC: "); if (status == 0) printf("The group exists.\n"); else printf("The group either does NOT exist or some other error occurred.\n"); // 开启错误堆栈自动打印功能 status = H5Eset_auto(H5E_DEFAULT, (H5E_auto2_t)H5Eprint2, stderr); // close the file status = H5Fclose(file_id); return 0; } 4.3 数据集(Dataset)的创建H5py中的dataset很类似与Numpy中的array,但支持一些列透明(针对连续存储的选择操作对分块存储同样有效)的存储特性,还支持分块,压缩,和错误校验。 新的数据集可以通过group.create_dateset()或者group.require_dateset()记性创建。已经存在的数据已可以通过群的所以语法进行访问dset = group[“dset_name”]。 python代码 import h5py import numpy as np f = h5py.File('file.h5','w') #创建数据集 # dataset = group.create_dateset(name, # shape=None, # dtype=None, # data=None) dset = f.create_dateset("default", (100,)) dset = f.create_dateset("ints", (100,), dtype='i8') dset = f.create_dateset("init", data=np.arange(100)) # 读取数据集可以采用索引操作 read_dset = f["default"] # 数据集的删除,注意这样做只是删除链接,但文件中所申请的空间无法收回 f.__delitem__("ints") # version 1 del f['init'] # version 2 f.close()在C/C++语言中,dataspace一共有三种形式 H5S_SCALAR: 标量,只有一个元素,rank为0H5S_SIMPLE:正常的数组形式的元素H5S_NULL:没有数据元素 其中最常用的是H5S_SIMPLE类型,它有一个直接的生成函数H5Screate_simple()其中H5Dwrite()函数匹配内存spaceid和文件spaceid的行为如下, mem_space_idfile_space_idBehavior有效id有效idmem_space_id specifies the memory dataspace and the selection within it. file_space_id specifies the selection within the file dataset’s dataspace.H5S_ALL有效idThe file dataset’s dataspace is used for the memory dataspace and the selection specified with file_space_id specifies the selection within it. The combination of the file dataset’s dataspace and the selection from file_space_id is used for memory also.有效idH5S_ALLmem_space_id specifies the memory dataspace and the selection within it. The selection within the file dataset’s dataspace is set to the “all” selection.H5S_ALLH5S_ALLThe file dataset’s dataspace is used for the memory dataspace and the selection within the memory dataspace is set to the “all” selection. The selection within the file dataset’s dataspace is set to the “all” selection.写入程序 #include #include #include "hdf5.h" int main(int argc, char* argv[]) { // 为矩阵matrix进行内存分配,这里采用了技巧分配了连续内存 int rows = 10; int columns = 8; double* data_mem = new double[rows*columns]; double** matrix = new double*[rows]; for (int i = 0; i matrix[r][c] = r + 0.01*c; } } // 打开HDF5文件 hid_t file_id; herr_t status; file_id = H5Fcreate("my_file.h5", H5F_ACC_TRUNC, H5P_DEFAULT, H5P_DEFAULT); // 创建数据集的metadata中的dataspace信息项目 unsigned rank = 2; hsize_t dims[2]; dims[0] = rows; dims[1] = columns; hid_t dataspace_id; // 数据集metadata中dataspace的id // dataspace_id = H5Screate_simple(int rank, 空间维度 // const hsize_t* current_dims, 每个维度元素个数 // - 可以为0,此时无法写入数据 // const hsize_t* max_dims, 每个维度元素个数上限 // - 若为NULL指针,则和current_dim相同, // - 若为H5S_UNLIMITED,则不舍上限,但dataset一定是分块的(chunked). dataspace_id = H5Screate_simple(rank, dims, NULL); // 创建数据集中的数据本身 hid_t dataset_id; // 数据集本身的id // dataset_id = H5Dcreate(loc_id, 位置id // const char *name, 数据集名 // hid_t dtype_id, 数据类型 // hid_t space_id, dataspace的id // 连接(link)创建性质, // 数据集创建性质, // 数据集访问性质) dataset_id = H5Dcreate(file_id, "/dset", H5T_NATIVE_DOUBLE, dataspace_id, H5P_DEFAULT, H5P_DEFAULT, H5P_DEFAULT); // 将数据写入数据集 // herr_t 写入状态 = H5Dwrite(写入目标数据集id, // 内存数据格式, // memory_dataspace_id, 定义内存dataspace和其中的选择 // - H5S_ALL: 文件中dataspace用做内存dataspace,file_dataspace_id中的选择作为内存dataspace的选择 // file_dataspace_id, 定义文件中dataspace的选择 // - H5S_ALL: 文件中datasapce的全部,定义为数据集中dataspace定义的全部维度数据 // 本次IO操作的转换性质, // const void * buf, 内存中数据的位置 status = H5Dwrite(dataset_id, H5T_NATIVE_DOUBLE, H5S_ALL, H5S_ALL, H5P_DEFAULT, matrix[0]); // 关闭dataset相关对象 status = H5Dclose(dataset_id); status = H5Sclose(dataspace_id); // 关闭文件对象 status = H5Fclose(file_id); // 释放动态分配的内存 delete[] matrix; delete[] data_mem; return 0; }读出程序 #include #include #include "hdf5.h" int main(int argc, char* argv[]) { // 为矩阵matrix进行内存分配,这里采用了技巧分配了连续内存 int rows = 10; int columns = 8; double* data_mem = new double[rows*columns]; double** matrix = new double*[rows]; for (int i = 0; i >> dset = f.create_dataset("MyDataset", (10,10,10), 'f') >>> dset[0,0,0] >>> dset[0,2:10,1:9:3] >>> dset[:,::2,5] >>> dset[0] >>> dset[1,5] >>> dset[0,...] >>> dset[...,6] >>> # 对于符合数据 >>> dset["FieldA"] >>> dset[0,:,4:5, "FieldA", "FieldB"] >>> dset[0, ..., "FieldC"] >>> # 广播在索引中依然被支持 >>> dset[0,:,:] = np.arange(10) # 广播到(10,10) >>> # 对于标量数据集,采用和numpy相同的语法结果,利用空tuple做索引,即 >>> scalar_result = dset[()]花式索引(Fancy Indexing) 一部分numpy花式索引在HDF5中也支持,比如 >>> dset.shape (10, 10) >>> result = dset[0, [1,3,8]] >>> result.shape (3,) >>> result = dset[1:6, [5,8,9]] >>> result.shape (5, 3)单使用受到一些限制 选择列表不能为空选择坐标必须要以升序方式给出重复项忽略长列表(>1k元素)将速度很慢numpy的逻辑索引可以用来进行选择,比如 >>> arr = numpy.arange(100).reshape((10,10)) >>> dset = f.create_dataset("MyDataset", data=arr) >>> result = dset[arr > 50] >>> result.shape (49,)和numpy一样,*len()函数返回dataset中第一个轴的长度。但是如果在32位平台上第一个轴长度超过2^32时len(dataset)将失效,因此推荐使用dataset.len()*方法。 4.4.2 C/C++部分在C语言中,访问原数据集子集的关键在于构造内存的dataspace,通过内存和文件中dataspace的配合实现访问选择子集的效果。在HDF5中,有两种选择,元素(element)选择和超块(hyperslab)选择,分别通过函数*H5Sselect_elements()和H5Sselect_hyperslab()*两个函数实现。这两个函数都会修改传入dataspace_id对应的dataspace空间性质,以此实现选择的子集。 和MPI的子集选择方法相同,HDF5的子集选择定义子集四大件: offset: 位置补偿stride: 间隙count: 块数block: 块大小例如想要从一个(8,10)的dataspace中选择一个如图(7,4)的dataspace,需要定义的四大件如下。 C/C++代码 #include "hdf5.h" #define FILE "subset.h5" #define DATASETNAME "IntArray" #define RANK 2 #define DIM0_SUB 3 // 子集的维度 #define DIM1_SUB 4 #define DIM0 8 // 原集的维度 #define DIM1 10 int main(int argc, char* argv[]){ // 先创建一个文件并写入原始数据集 hid_t file_id; file_id = H5Fcreate(FILE, H5F_ACC_TRUNC, H5P_DEFAULT, H5P_DEFAULT); hsize_t dims[2]; dims[0] = DIM0; dims[1] = DIM1; hid_t dataspace_id, dataset_id; dataspace_id = H5Screate_simple(RANK, dims, NULL); dataset_id = H5Dcreate2(file_id, DATASETNAME, H5T_STD_I32BE, dataspace_id, H5P_DEFAULT, H5P_DEFAULT, H5P_DEFAULT); // 创建写入数据集 /* 写入文件中的数据为 [1, 1, 1, 1, 1, 2, 2, 2, 2, 2; 1, 1, 1, 1, 1, 2, 2, 2, 2, 2; 1, 1, 1, 1, 1, 2, 2, 2, 2, 2; 1, 1, 1, 1, 1, 2, 2, 2, 2, 2; 1, 1, 1, 1, 1, 2, 2, 2, 2, 2; 1, 1, 1, 1, 1, 2, 2, 2, 2, 2; 1, 1, 1, 1, 1, 2, 2, 2, 2, 2; 1, 1, 1, 1, 1, 2, 2, 2, 2, 2] */ int i, j; int data[DIM0][DIM1]; for (j = 0; j for (i = 0; i // 开启压缩锁等级为6的ZLIB / DEFLATE压缩,算法和gzip相同 // H5Pset_deflate()将创建性质列表中压缩方法设为H5Z_FILTER_DEFLATE过滤器,并设置压缩等级 // herr_t H5Pset_deflate( hid_t plist, 数据集创建性质列表的id // uint level ) 压缩等级0-9,压缩等级越高,目标体积越小,压缩率越高,耗时越长 status = H5Pset_deflate(plist_id, 6); } else if (method == 's') { // 设置szip压缩 // H5Pset_szip将创建数据集性质列表中压缩方法设为H5Z_FILTER_SZIP过滤器,并设置压缩像素大小 // herr_t H5Pset_szip(hid_t plist, 数据集创建性质列表的id // unsigned int options_mask, 编码方法设置 // - H5_SZIP_EC_OPTION_MASK 采用熵编码方法:适合处理过的数据,适合小数字 // - H5_SZIP_NN_OPTION_MASK 采用最近邻编码:最近邻处理后再调用熵编码处理 // unsigned int pixels_per_block) 分块中的像素数,必须比分块小,典型值8,10,16,32,64. // 像素值变化越小,该值应该越小,为了得到最优化表现,推荐数据集变化最快的维度应等于128*分块中像素数 status = H5Pset_szip(plist_id, H5_SZIP_NN_OPTION_MASK, 32); } else { std::cerr |
【本文地址】
今日新闻 |
推荐新闻 |