深度学习训练滑动验证码(Yolov5) |
您所在的位置:网站首页 › python训练验证码 › 深度学习训练滑动验证码(Yolov5) |
深度学习训练滑动验证码(Yolov5)
|
注:本文只用于学习,如有问题请联系作者。 场景介绍对于现在网络的大多数滑动验证码如果想用一个通用的方法还是需要用深度学习,用图像处理的方式对于单一类型还是比较好用的,多类型还是难以适用的。例如如下多种类型:
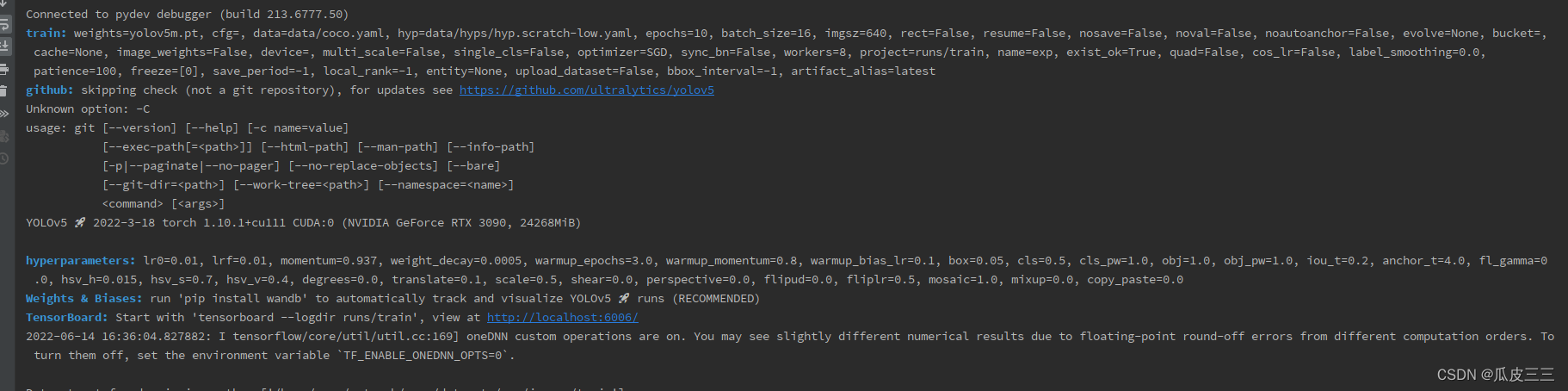
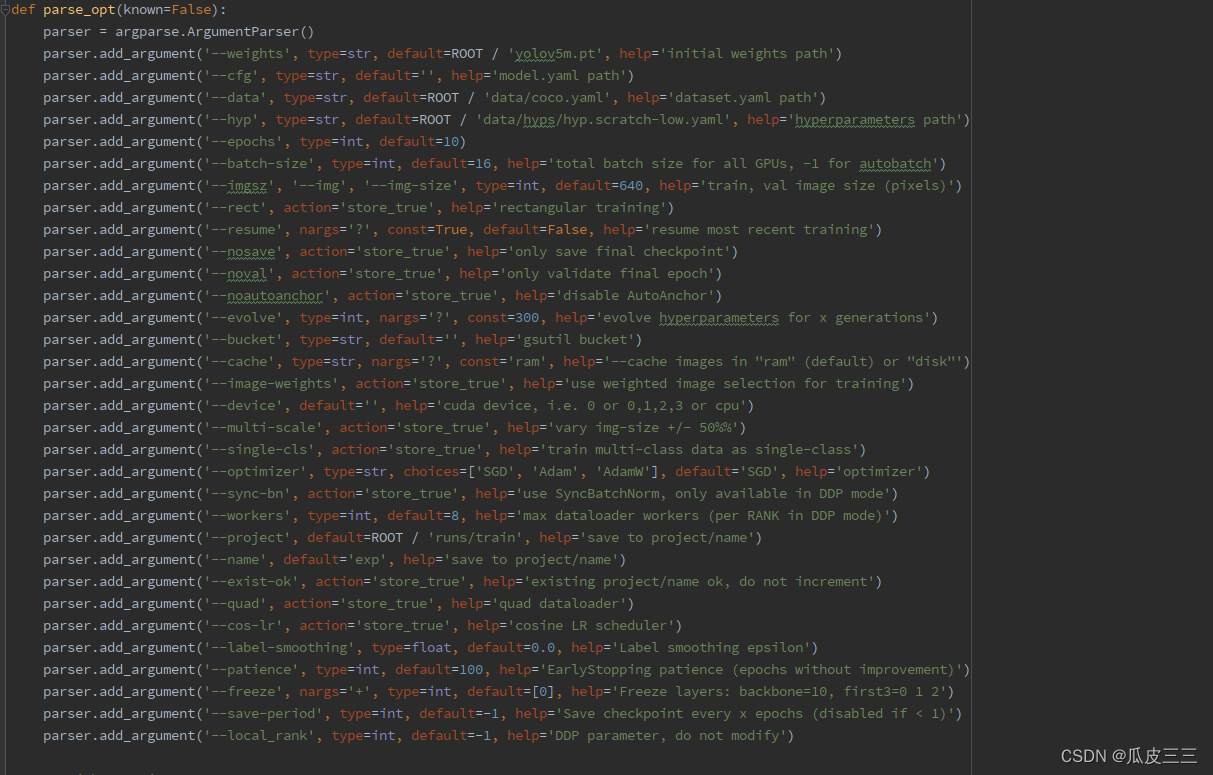
YOLO 是“You only look once”的首字母缩写词,是一种将图像划分为网格系统的对象检测算法。网格中的每个单元都负责检测自身内部的对象。 由于其速度和准确性,YOLO 是最著名的目标检测算法之一。 git clone https://github.com/ultralytics/yolov5.git打开项目 安装后配置环境然后启动train.py出现如下代表yolo配置成功 需要有cuda环境(需要用gpu训练) ,torch,torchvision,numpy等环境(自行解决) train.py文件的454行parse_opt里面有很多启动脚本超参数,接受一下常用的: 如果有感兴趣的自行查询。 滑动验证码数据集yolo有自己数据集的格式 我已经整理好了有4100张上述滑块类型 make-sense 是一个被YOLOv5官方推荐使用的图像标注工具 https://www.makesense.ai/ 这个标注工具,具体使用https://blog.csdn.net/to_chariver/article/details/119619515看这个博主,很详细 配置数据集和超参数在data下面创建一个Sliding.yaml的配置文件 配置好了就可以开始训练了, 可以看到已经有训练信息在跑了,等待训练完50轮我们就可以看结果啦。 这里解释一下信息中的参数都是什么: Epoch 训练轮数 gpu_mem gpu占用内存 box 边界框损失 YOLO V5使用 GIOU Loss作为bounding box的损失,Box推测为GIoU损失函数均值,越小方框越准; obj 目标检测损失 推测为目标检测loss均值,越小目标检测越准; cls 分类损失 推测为分类loss均值,越小分类越准;(缺口只有一个类别所以为0没有浮动) img_size 图片尺寸默认为640 Images 测试集图片个数849张 Labels 测试集标签个数847张 P 精度 R 召回率 一般训练结果主要观察精度和召回率波动情况 详细解读请看 https://blog.csdn.net/sinat_37322535/article/details/117260081 这个博主
项目中的export.py文件中的521行weights超参数将pt模型路径写入列入:
在detect.py文件中配置可以对模型进行检测 211行配置超参数 这里一定要配置成刚刚训练好的,模型路径 然后将想要测试的图片放入data/images下面,然后运行detect.py文件即可。
yolo有接口测试就在utils下的flask_rest_api文件中restapi.py是服务端,example_requset.py是客户端,可以自行测试。 我这里主要介绍脱离yolo,单独脚本进行测试,并返回坐标和预测图片。 代码从yolo源码中debug抠出来的,将pt模型转为onnx模型,在调用此脚本 import os import sys import time from io import BytesIO import onnxruntime import torch import torchvision import numpy as np import cv2 # 图像处理 from PIL import Image def padded_resize(im, new_shape=(640, 640), stride=32): try: shape = im.shape[:2] r = min(new_shape[0] / shape[0], new_shape[1] / shape[1]) new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r)) dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # dw, dh = np.mod(dw, stride), np.mod(dh, stride) dw /= 2 dh /= 2 if shape[::-1] != new_unpad: # resize im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR) top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1)) left, right = int(round(dw - 0.1)), int(round(dw + 0.1)) im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=(114, 114, 114)) # add border # Convert im = im.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB im = np.ascontiguousarray(im) im = torch.from_numpy(im) im = im.float() im /= 255 im = im[None] im = im.cpu().numpy() # torch to numpy return im except: print("123") def xywh2xyxy(x): # Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x) y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y return y def box_iou(box1, box2): """ Return intersection-over-union (Jaccard index) of boxes. Both sets of boxes are expected to be in (x1, y1, x2, y2) format. Arguments: box1 (Tensor[N, 4]) box2 (Tensor[M, 4]) Returns: iou (Tensor[N, M]): the NxM matrix containing the pairwise IoU values for every element in boxes1 and boxes2 """ def box_area(box): # box = 4xn return (box[2] - box[0]) * (box[3] - box[1]) area1 = box_area(box1.T) area2 = box_area(box2.T) # inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2) inter = (torch.min(box1[:, None, 2:], box2[:, 2:]) - torch.max(box1[:, None, :2], box2[:, :2])).clamp(0).prod(2) return inter / (area1[:, None] + area2 - inter) # iou = inter / (area1 + area2 - inter) def non_max_suppression(prediction, conf_thres=0.25, iou_thres=0.45, classes=None, agnostic=False, multi_label=False, labels=(), max_det=300): """Runs Non-Maximum Suppression (NMS) on inference results Returns: list of detections, on (n,6) tensor per image [xyxy, conf, cls] """ nc = prediction.shape[2] - 5 # number of classes xc = prediction[..., 4] > conf_thres # candidates # Checks assert 0 |



 这里展示了5种类型不同的滑块,我们要做的就是准确的找到缺口的位置通过。 我这里使用的yolov5
这里展示了5种类型不同的滑块,我们要做的就是准确的找到缺口的位置通过。 我这里使用的yolov5
 这里目录下分文图片和标签两个目录
这里目录下分文图片和标签两个目录  图片和标签一样下面为一个test和train测试集和训练集
图片和标签一样下面为一个test和train测试集和训练集 
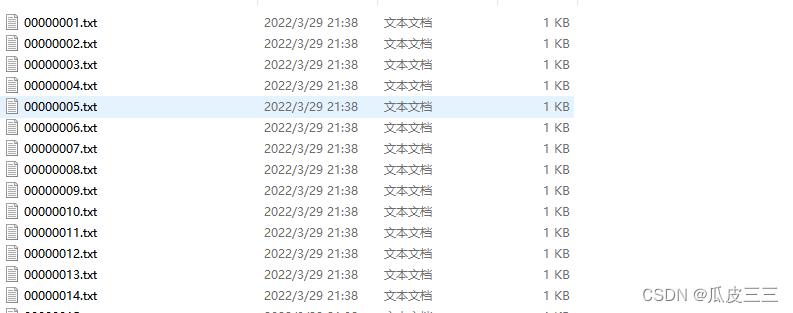 这里是yolo的数据集格式必须这个样子
这里是yolo的数据集格式必须这个样子 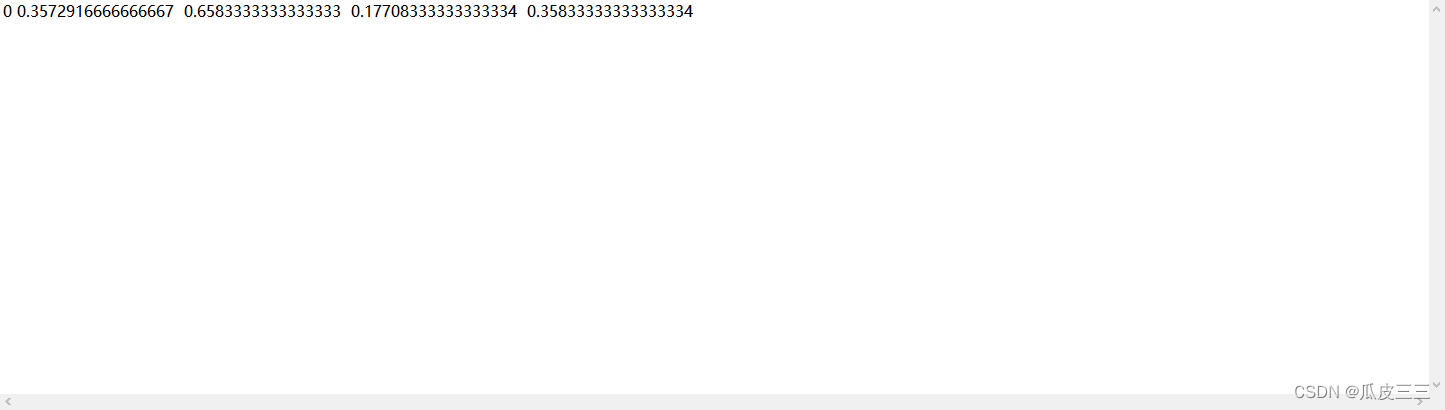 我已经整理好了数据集并标注,如果你想自己训练自己的图片也可以也行标注但是格式必须是这个样子。 推荐一个标注的网站可以直接导出yolo格式
我已经整理好了数据集并标注,如果你想自己训练自己的图片也可以也行标注但是格式必须是这个样子。 推荐一个标注的网站可以直接导出yolo格式 这里配置完改了几个超参数如下:
这里配置完改了几个超参数如下: 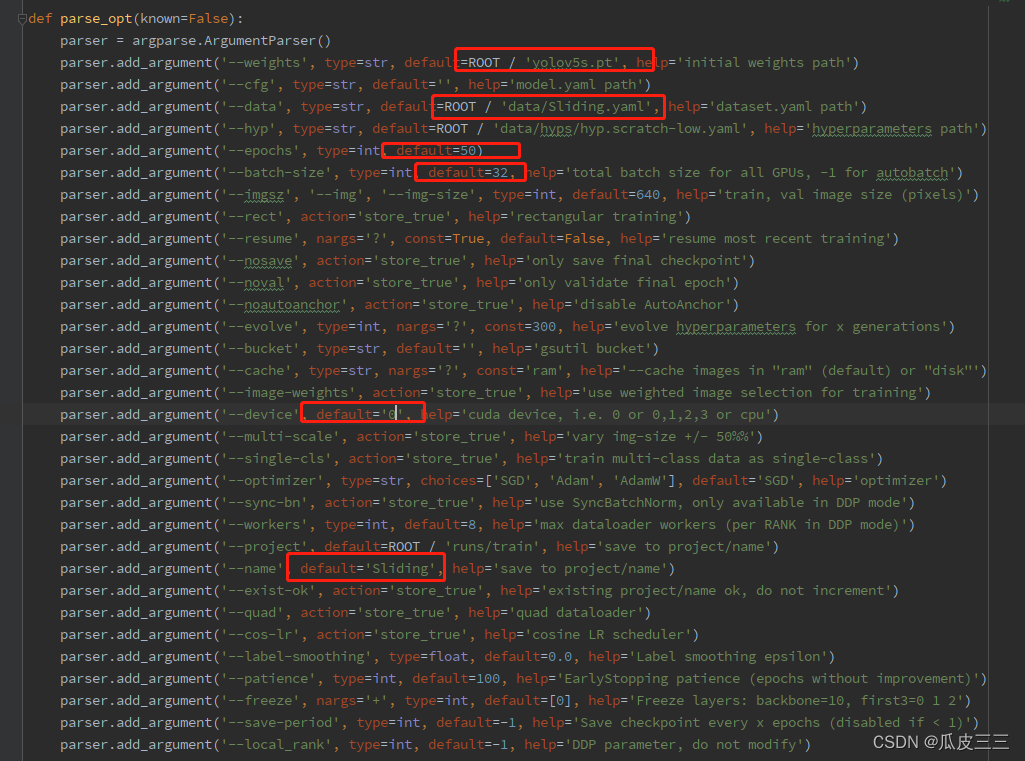 我训练模型选择yolov5s,这是不同yolo模型的对比图。
我训练模型选择yolov5s,这是不同yolo模型的对比图。 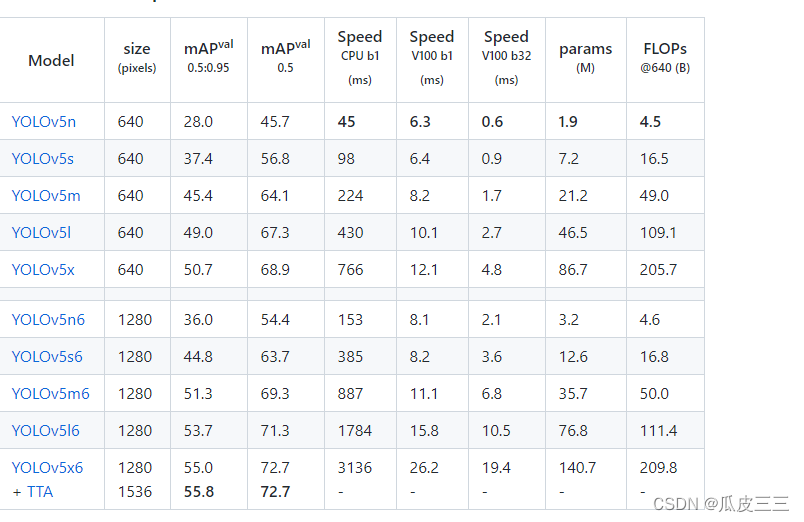
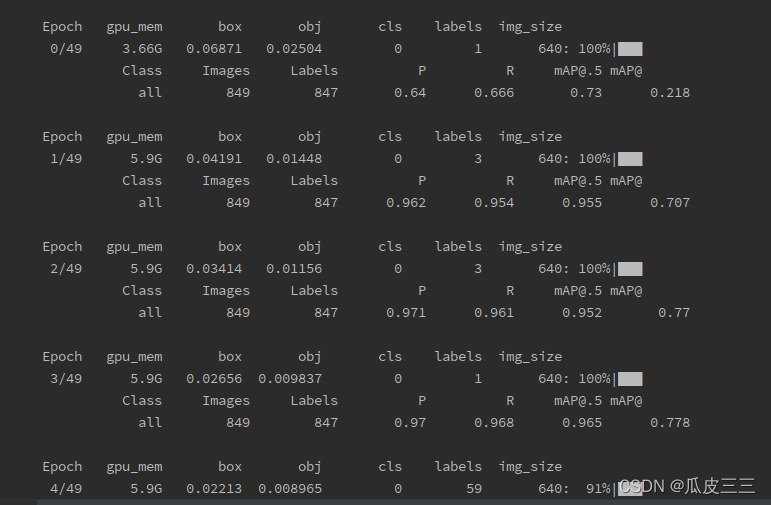
 可以看到这里精度和召回率表现都很不错 训练结束后在目录下的runs/train/Sliding下生成一些训练结果的文件(这个目录可以自己设置)
可以看到这里精度和召回率表现都很不错 训练结束后在目录下的runs/train/Sliding下生成一些训练结果的文件(这个目录可以自己设置) 看一下我们测试集的预测结果,val_batch_pred.jpg
看一下我们测试集的预测结果,val_batch_pred.jpg  Gap就是我们需要找到的地方,还有置信度 results.csv文件是训练具体的详细信息
Gap就是我们需要找到的地方,还有置信度 results.csv文件是训练具体的详细信息 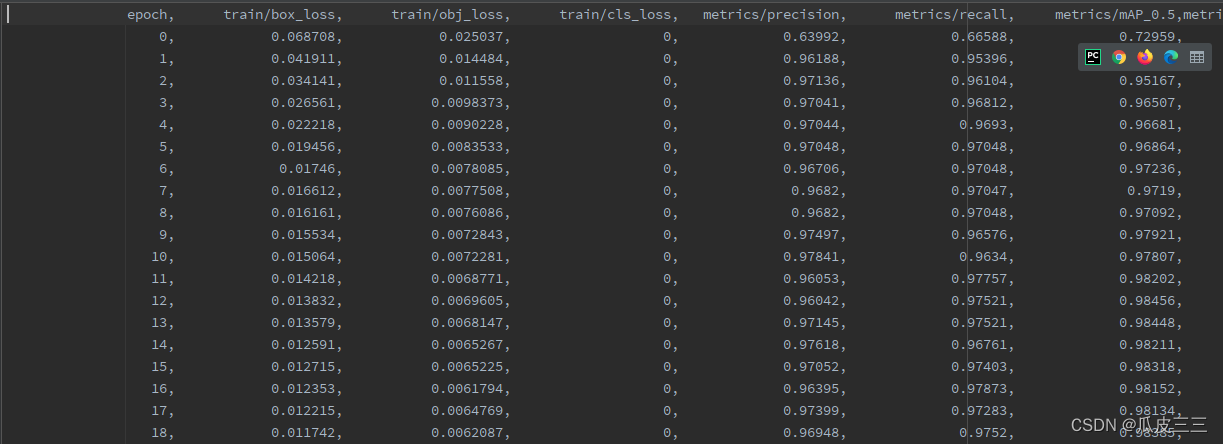 最重要的是在weights目录下有两个pt模型,
最重要的是在weights目录下有两个pt模型,  最好的模型,和最后的模型,我们之后验证就可以用着模型进行验证
最好的模型,和最后的模型,我们之后验证就可以用着模型进行验证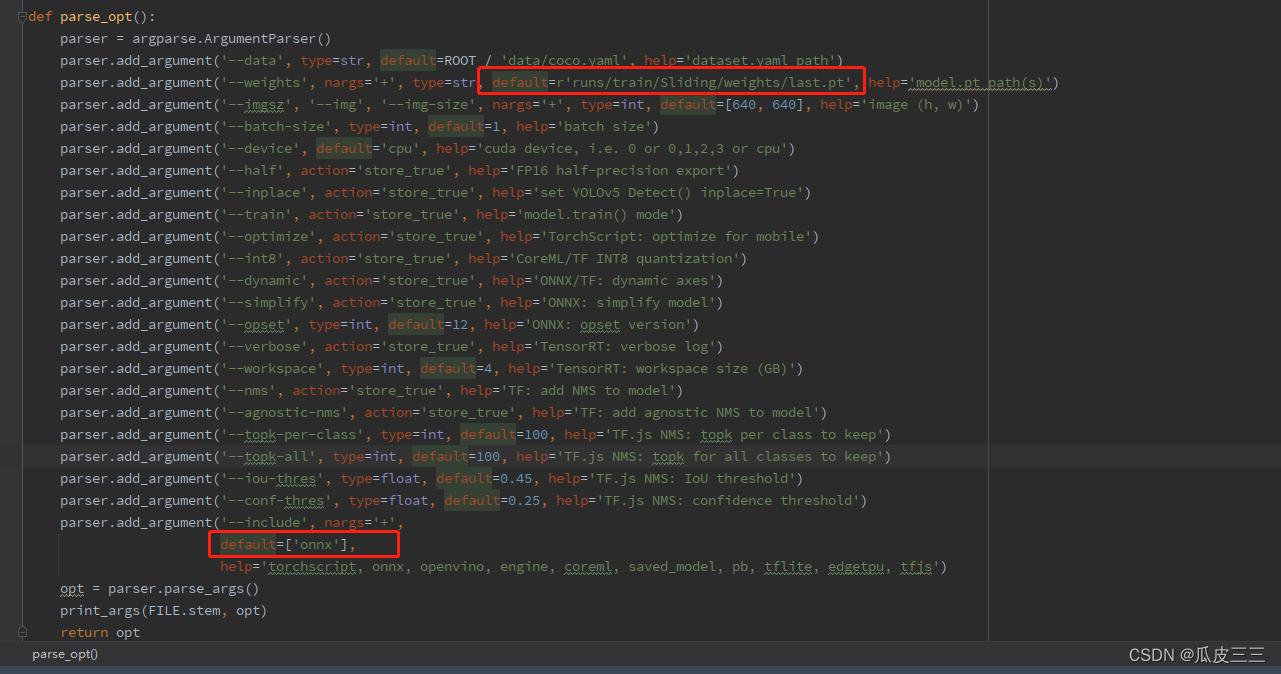 需要有onnx模块不然会报错,如果报异常 Onnx: No module named ‘onnx’ 手动安装onnx模块然后在重试即可
需要有onnx模块不然会报错,如果报异常 Onnx: No module named ‘onnx’ 手动安装onnx模块然后在重试即可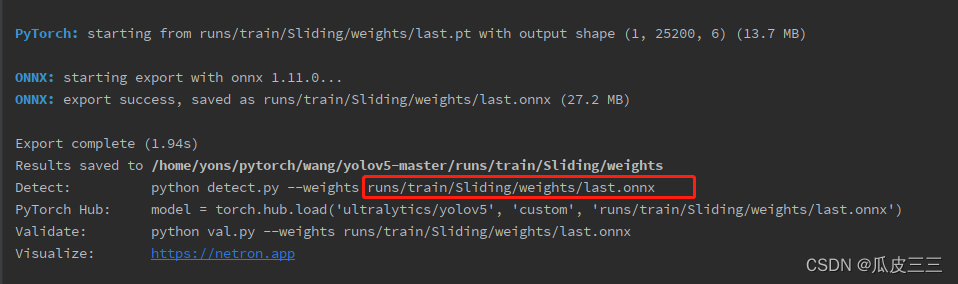 在这个目录下可以看到last.onnx模型,接下来就是模型的单独调度。
在这个目录下可以看到last.onnx模型,接下来就是模型的单独调度。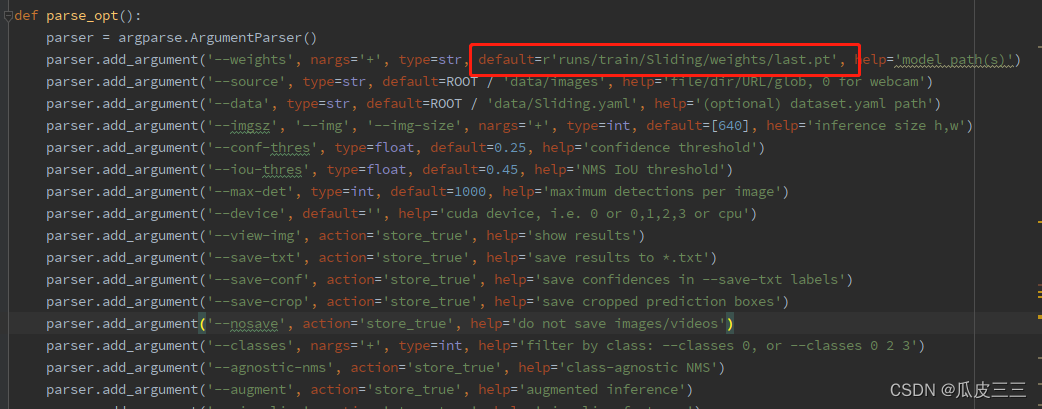
 这里看到我保存在了runs/detect/Sliding目录下
这里看到我保存在了runs/detect/Sliding目录下  这里的图片文件名称和data/images的文件名称一样可以看到,
这里的图片文件名称和data/images的文件名称一样可以看到,  成功看到返回缺口位置和置信度,这里已经预测成功,说明我们的模型已经训练成功了。 我将所有图片全部组合起来看起来方便。 图片合成代码
成功看到返回缺口位置和置信度,这里已经预测成功,说明我们的模型已经训练成功了。 我将所有图片全部组合起来看起来方便。 图片合成代码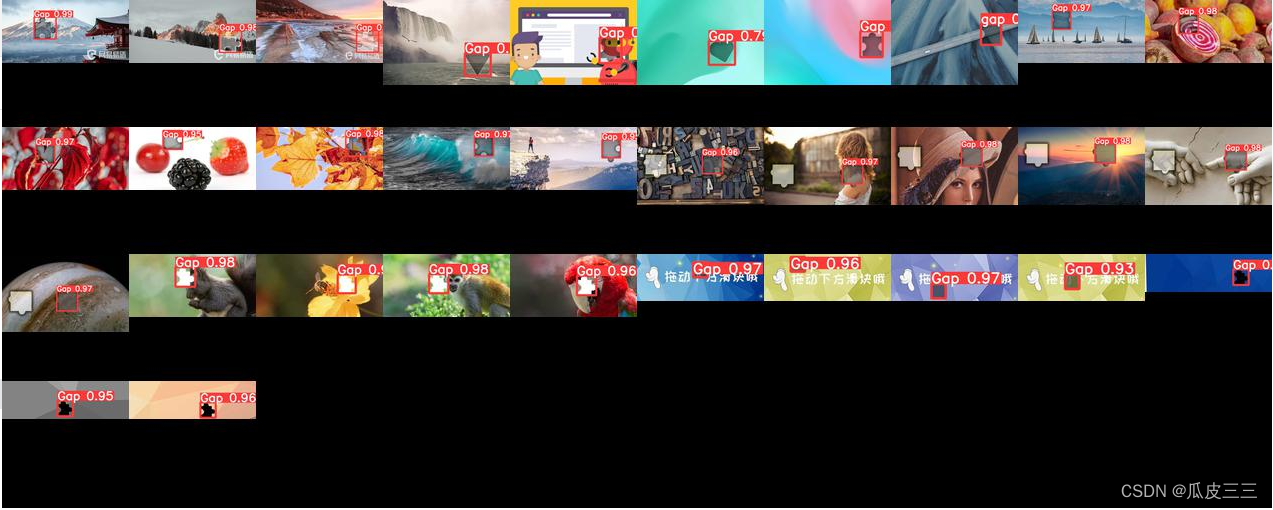 可以看到测试结果还是非常不错的这是我32张的表现。
可以看到测试结果还是非常不错的这是我32张的表现。【本文地址】
今日新闻 |
推荐新闻 |