python编写背单词程序 |
您所在的位置:网站首页 › python菜鸟工具运行成绩评分 › python编写背单词程序 |
python编写背单词程序
|
目录
1 功能介绍2 文件准备3 源码
一年多前初学python时写的代码,这里分享给大家。 1 功能介绍首先运行程序,进入欢迎界面。如下图,界面是一个小方框,可以选择词库,默认是六级词库。 读者想要运行该程序,必须准备相关的文件,包括两张插图(必须为gif格式)和三个词库。 下面两张是我用到的插图。 词库我当时是在百度文库里直接下载的。 然后把这些文件和源程序放在一个文件夹里,否则需要在程序中修改读写路径。 3 源码用到的库有tkinter 、random、matplotlib。tkinter 主要用来设计界面和功能按键,random用来随机选取单词,matplotlib在最后画饼图的时候要用到。详细的编程思路暂时不讲了,有问题可以评论区留言。 还有我当时编程的时候变量的命名不太合理,可能比较难看懂,各位见谅了! from tkinter import * import random from tkinter import messagebox root=Tk() root.title("欢迎使用") group=LabelFrame(root,text=' 欢迎使用,请选择词库 \n并选好后点击左上角关闭按钮',padx=10,pady=10) group.pack(padx=10,pady=10) LANGS=[ ('四级词汇',1), ('六级词汇',2), ('考研词汇',3)] v=IntVar() v.set(2) for lang,num in LANGS: b=Radiobutton(group,text=lang,variable=v,value=num) b.pack(anchor=W) mainloop() def trans(filename): f=open(filename,'r',encoding='utf-8') s=f.read() f.close() f=open("单词.txt",'w',encoding='utf-8') f.write(s) f.close() if v.get()==1: trans('四级词汇.txt') elif v.get()==2: trans('六级词汇.txt') else: trans('考研词汇.txt') #设置框架和背景 root=Tk() root.title('PYTHON背单词') root['width']=300 root['height']=400 mainframe=Frame(root) mainframe.pack() blank=Frame(root,height=50,width=50) blank.pack() photo1= PhotoImage(file = '插图一.gif') imgLabel=Label(root,image=photo1).pack(side=LEFT) photo2= PhotoImage(file = '插图二.gif') imgLabel=Label(root,image=photo2).pack(side=RIGHT) #设置变量 l=StringVar() #l是剩余未背单词数 a1=StringVar() #a1是单词 a2=StringVar() #a2是音标 a3=StringVar() #a3是词义 a4=StringVar() #a4是复习时的词义提示 a5=StringVar() #a5是复习时用户从键盘中输入的单词 a6=StringVar() #a6输出测试结果 a7=StringVar() #a7是回答错误时显示的正确结果 i=StringVar() #i是当前背到的单词数 n=StringVar() #n是本次计划背的单词数 N=StringVar() #N显示当前复习到的单词数 nd=StringVar() #nd是本次删除的单词数 ng=StringVar() #ng是本次已掌握的单词数 nng=StringVar() #nng是本次未掌握的的单词数 ng.set('0') #将已掌握的单词初值设为0 nng.set('0') #将未掌握的单词初值设为0 #定义createfile函数,首次运行时创建文件 def createfile(filename): try: f=open(filename,'r',encoding='utf-8') #读取unicode格式的文件 f.close() except: f=open(filename,'w',encoding='utf-8') #写入unicode格式的文件 f.write('') f.close() #创建文件,用途从文件名可知 createfile('选取单词.txt') createfile('复习.txt') createfile('斩.txt') createfile('已掌握单词.txt') createfile('难词.txt') #定义empty函数,清空中间文件 def empty(): f3=open('复习.txt','w',encoding='utf-8') f3.write('') f3.close() f2=open('选取单词.txt','w',encoding='utf-8') f2.write('') f2.close() #设置内部结构: #第一行设置 Label(mainframe,text='python背单词',font=('楷体',25)).grid(column=1,row=0) #第二行设置 Label(mainframe,text=' 剩余单词数:',height=2,font=('隶书',13))\ .grid(column=0,row=1,columnspan=1,sticky=('W','E')) Label(mainframe,textvariable=l,width=10,height=2,font=('隶书',13))\ .grid(row=1,column=1) f1=open('单词.txt','r',encoding='utf-8') s1=f1.read() s1=s1.strip() f1.close() words=s1.split('\n') l.set(str(len(words))) #第三行设置 Label(mainframe,text='本次共背',height=2,font=('隶书',13)).grid(row=2,column=0,sticky=('W','E')) entry1=Entry(mainframe,textvariable=n,width=18)\ .grid(row=2,column=1) n.set(' ') Label(mainframe,text='个单词',height=2,font=('隶书',13)).grid(row=2,column=2,sticky=('W','E')) #第四行设置 #定义begin函数,开始背单词 def begin(*args): #*args传入参数 empty() #调用empty函数,防止因用户随机终止背诵任务而在中间文件内残留数据 n1=int(n.get()) f1=open('单词.txt','r',encoding='utf-8-sig') #encoding='utf-8-sig',防止开头出现错误字符“\ufeff” s1=f1.read() s1=s1.strip() f1.close() words=s1.split('\n') #读取单词表 rd=random.sample(range(0,len(words)),n1) #生成n个随机数,对应n个单词的编号 i.set(1) word=words[rd[0]].split('/') #word中包含单词,音标和词义 a1.set(word[0]) #将第一个单词显示出来 a2.set(word[1]) a3.set(word[2]) f2=open('选取单词.txt','w',encoding='utf-8') #将n个单词放入名为"选取单词"的文件中 for j in range(0,n1): str1=words[rd[j]]+'\n' f2.write(str1) f2.close() bt1=Button(mainframe,text='开始',command=begin,bg='lightblue',width=15,height=2,font=('隶书',13))\ .grid(row=3,column=2) #设置“开始”按钮,调用begin函数 #第五行设置 Label(mainframe,text='当前第 ',height=2,font=('隶书',13))\ .grid(column=0,row=4,columnspan=1,sticky=('W','E')) Label(mainframe,textvariable=i,width=1)\ .grid(row=4,column=1) Label(mainframe,text='个单词',height=2,font=('隶书',13))\ .grid(column=2,row=4,columnspan=1,sticky=('W','E')) #第六行设置 Label(mainframe,text='单词 ',height=2,font=('隶书',13)).grid(row=5,column=0,sticky=('W','E')) Label(mainframe,text='音标',height=2,font=('隶书',13)).grid(row=5,column=1) Label(mainframe,text='词义 ',height=2,font=('隶书',13)).grid(row=5,column=2,sticky=('W','E')) #第七行设置 Label(mainframe,textvariable=a1,width=50,font=('宋体',13),fg='purple')\ .grid(row=6,column=0,sticky=E) Label(mainframe,textvariable=a2,width=30,font=('宋体',13),fg='purple')\ .grid(row=6,column=1,sticky=('W','E')) Label(mainframe,textvariable=a3,width=50,font=('宋体',13),fg='purple')\ .grid(row=6,column=2,sticky=W) #第八行设置 #定义Next函数,背下一个单词 def Next(*args): f2=open('选取单词.txt','r',encoding='utf-8') s2=f2.read() s2=s2.strip() #strip()方法去除文本前后的换行符 f2.close() words=s2.split('\n') #将单词放入名为words的列表中 if len(words)>0: f3=open('复习.txt','a+',encoding='utf-8') #弹出words中的第一个单词,并放入名为"复习"的文件中 str3=words.pop(0)+'\n' f3.write(str3) f3.close() f2=open('选取单词.txt','w',encoding='utf-8') #去掉"选取单词"文件中的第一个单词 str2='\n'.join(words) f2.write(str2) f2.close() if int(i.get())==int(n.get()): #表明背完了单词 messagebox.showinfo("提示","你已经背完了,快去复习吧!") #弹出小窗口 else: word=words[0].split('/') #word中包含单词,音标和词义 a1.set(word[0]) #显示下一个单词 a2.set(word[1]) a3.set(word[2]) k=int(i.get()) i.set(str(k+1)) #i的值增加1 bt2=Button(mainframe,text='记住啦!下一个!',command=Next,width=15,bg='green',height=2,font=('隶书',13))\ .grid(row=7,column=2) #设置“下一个”按钮,调用Next函数 #定义delete函数,删除过于简单的单词 def delete(*args): f2=open('选取单词.txt','r',encoding='utf-8') s2=f2.read() s2=s2.strip() #strip()方法去除文本前后的换行符 f2.close() words=s2.split('\n') #将单词放入名为words的列表中 str4=words.pop(0)+'\n' f4=open('斩.txt','a+',encoding='utf-8') #打开文件"斩",将"选取单词"文件中的第一个单词添加进去 f4.write(str4) f4.close() if int(i.get())==int(n.get()): #表明背完了单词 messagebox.showinfo("提示","你已经背完了,快去复习吧!") #弹出小窗口 else: word=words[0].split('/') #word中包含单词,音标和词义 a1.set(word[0]) #显示下一个单词 a2.set(word[1]) a3.set(word[2]) k=int(i.get()) i.set(str(k+1)) #i的值增加1 f2=open('选取单词.txt','w',encoding='utf-8') #去掉"选取单词"文件中的第一个单词 str2='\n'.join(words) f2.write(str2) f2.close() bt3=Button(mainframe,text='太简单了!斩!',command=delete,width=15,bg='red',height=2,font=('隶书',13))\ .grid(row=7,column=0) #定义dif函数,把较难的词汇加入“难词.txt” def dif(*args): string=a1.get()+'/'+a2.get()+'/'+a3.get()+'\n' f=open('难词.txt','a+',encoding='utf-8') f.write(string) f.close() Button(mainframe,text='加入难词!',command=dif,width=15,bg='gold',height=2,font=('隶书',13))\ .grid(row=7,column=1) #第九行设置 #定义check函数,建议输入的单词是否正确 def check(*args): f3=open('复习.txt','r',encoding='utf-8') s3=f3.read() s3=s3.strip() words=s3.split('\n') word=words[0].split('/') Label(mainframe,text='正确答案是:',height=2,font=('隶书',13))\ .grid(column=0,row=11,columnspan=1) a7.set(word[0]) answer=a5.get() answer=answer.strip() #去掉回车而产生的换行符 word[0]=word[0].strip() #去掉空格 if word[0]==answer: a6.set('回答正确!') f5=open('已掌握单词.txt','a+',encoding='utf-8') #将拼写正确的单词放入"已掌握单词"文件中 str5=words.pop(0)+'\n' f5.write(str5) f5.close() ng1=int(ng.get()) #掌握单词数加一 ng.set(str(ng1+1)) else: a6.set('回答错误!') nng1=int(nng.get()) #未掌握单词数加一 nng.set(str(nng1+1)) del words[0] #直接将未掌握的单词删除 str3='\n'.join(words) f3=open('复习.txt','w',encoding='utf-8') f3.write(str3) f3.close() #定义Next1函数,复习下一个单词 def Next1(*args): if int(N.get())==int(n.get())-int(nd.get()): messagebox.showinfo("提示","本次单词背诵结束!点击‘确定’后显示背诵情况") empty() #清空中间文件,避免对下次背单词产生干扰 f1=open('单词.txt','r',encoding='utf-8-sig') #把已掌握的单词和已删除的单词从单词.txt中删除 s1=f1.read() f1.close() f4=open('斩.txt','r',encoding='utf-8') s4=f4.read() s4=s4.strip() words4=s4.split('\n') f5=open('已掌握单词.txt','r',encoding='utf-8') s5=f5.read() s5=s5.strip() words5=s5.split('\n') if words4!=['']: for i in words4: if i in s1: i=i+'\n' s1=s1.replace(i,'') if words5!=['']: for j in words5: if j in s1: j=j+'\n' s1=s1.replace(j,'') if v.get()==1: f=open('四级词汇.txt','w',encoding='utf-8') f.write(s1) f.close() elif v.get()==2: f=open('六级词汇.txt','w',encoding='utf-8') f.write(s1) f.close() else : f=open('考研词汇.txt','w',encoding='utf-8') f.write(s1) f.close() f1=open('单词.txt','w',encoding='utf-8') f1.write('') f1.close() import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['SimHei'] sizes=int(nd.get()),int(ng.get()),int(nng.get()) labels1='已斩单词','已掌握单词','未掌握单词' colors1='red','blue','yellow' plt.pie(sizes,labels=labels1,colors=colors1,autopct='%2.3f%%') plt.axis('equal') plt.title("背诵情况饼图",color='green',fontsize=25) plt.show() else: a6.set('') a7.set('') #将上一个单词的相关信息去除,避免干扰答题 f3=open('复习.txt','r',encoding='utf-8') s3=f3.read() s3=s3.strip() f3.close() words=s3.split('\n') rdint=random.randint(1,len(words))-1 rdword=words[rdint] rdword1=rdword.split('/') a4.set(rdword1[2]) #打开"复习"文件,随机选出一个单词,显示其词义 words[0],words[rdint]=words[rdint],words[0] #将随机选出的单词放在words开头,方便查找 f3=open('复习.txt','w',encoding='utf-8') #将words重新写入"复习"文件 f3.write('\n'.join(words)) f3.close() k=int(N.get()) N.set(str(k+1)) #定义review函数,开始复习,并显示出接下来的几行 def review(*args): if int(i.get()) |
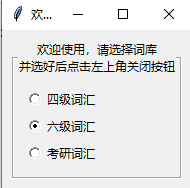 选好之后点击左上角的关闭按钮,即可进入主页面,并显示选择的词库的剩余单词数。排版并不是很美观,读者可以尝试修改程序来美化界面。
选好之后点击左上角的关闭按钮,即可进入主页面,并显示选择的词库的剩余单词数。排版并不是很美观,读者可以尝试修改程序来美化界面。 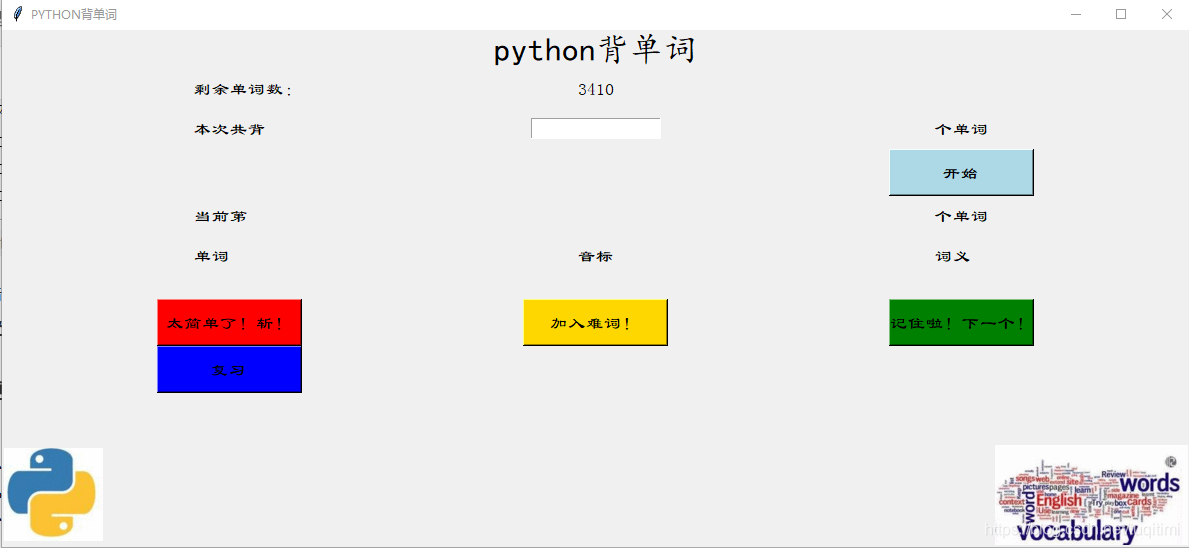 写入本次计划背诵的单词数,点击“开始”按钮即可开始背诵,界面中显示单词的拼写、音标和释义。 有三个单词处理按钮,左键“太简单了!斩!”是模仿百词斩APP的说法,可以将你觉得比较简单的单词从词库中彻底删去;中间“加入难词!”会将单词加入到一个名为“难词.txt”的文本中,便于日后复习;右键“记住啦!下一个!”会将该单词加入“复习.txt”中,用户可在本次背完后进行复习,并跳转到下一个单词。
写入本次计划背诵的单词数,点击“开始”按钮即可开始背诵,界面中显示单词的拼写、音标和释义。 有三个单词处理按钮,左键“太简单了!斩!”是模仿百词斩APP的说法,可以将你觉得比较简单的单词从词库中彻底删去;中间“加入难词!”会将单词加入到一个名为“难词.txt”的文本中,便于日后复习;右键“记住啦!下一个!”会将该单词加入“复习.txt”中,用户可在本次背完后进行复习,并跳转到下一个单词。 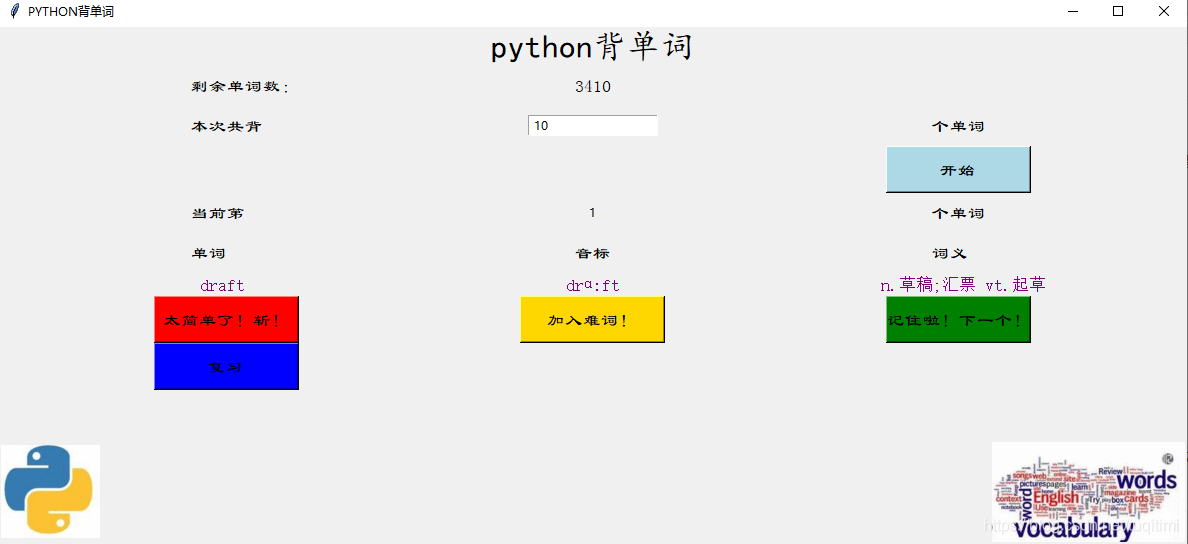 全部背完后会弹出提示框,点击确定后可以关闭。
全部背完后会弹出提示框,点击确定后可以关闭。 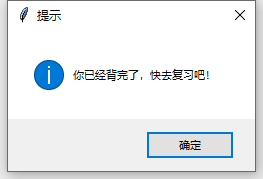 点击复习按钮后开始复习。
点击复习按钮后开始复习。 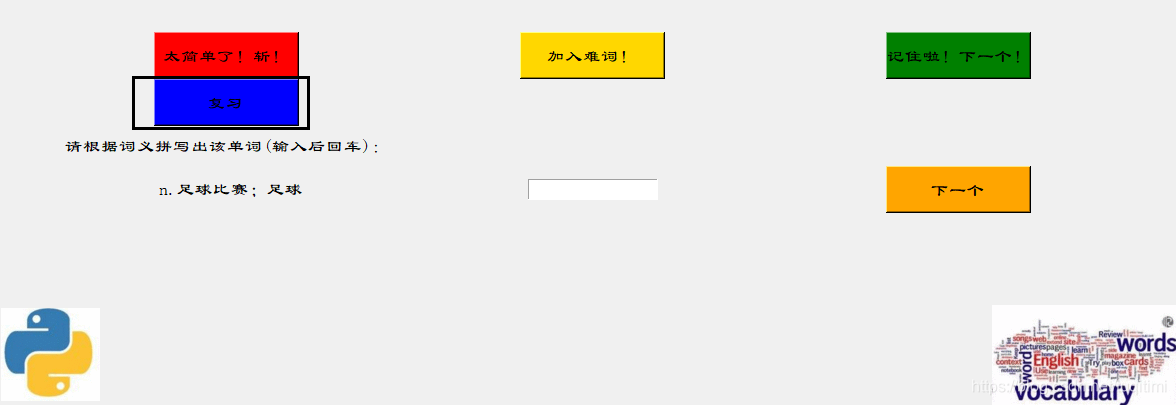 这里的复习其实也就是一个小测试,即根据释义写出单词。将单词拼写完毕后按下回车,可显示正确答案。
这里的复习其实也就是一个小测试,即根据释义写出单词。将单词拼写完毕后按下回车,可显示正确答案。 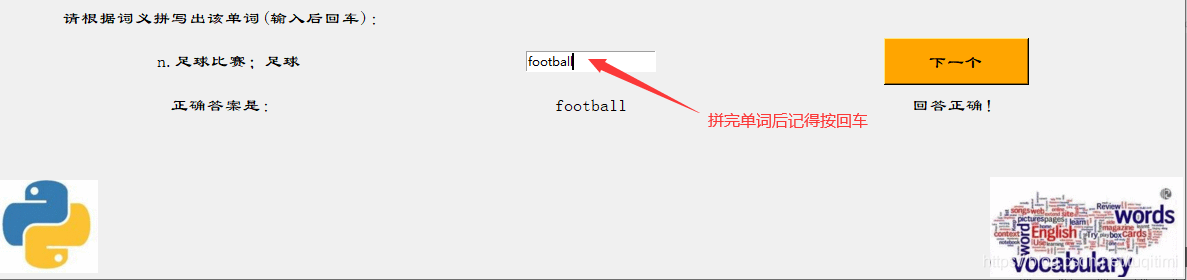 然后点击下一个。
然后点击下一个。 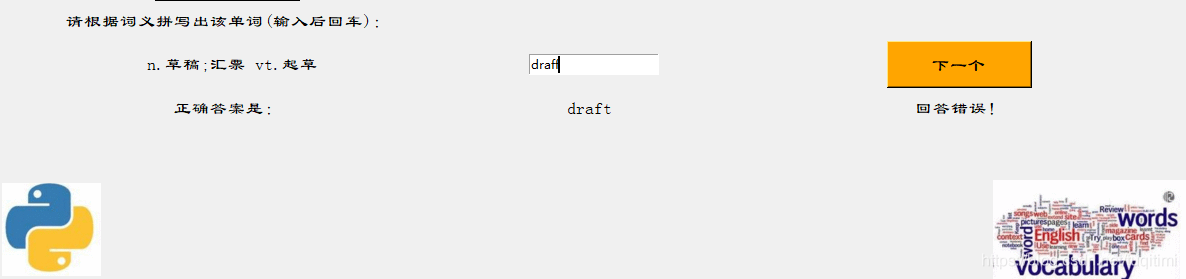 全部背完后弹出提示。
全部背完后弹出提示。 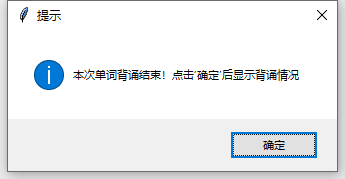 关闭提示后显示本次背诵情况。
关闭提示后显示本次背诵情况。 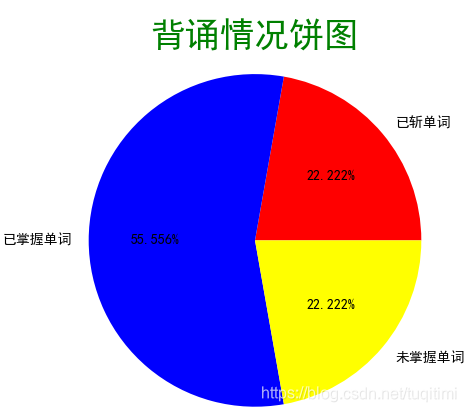 打开程序所在的文件夹,可以看到背过的单词被放在三个txt文件里。
打开程序所在的文件夹,可以看到背过的单词被放在三个txt文件里。 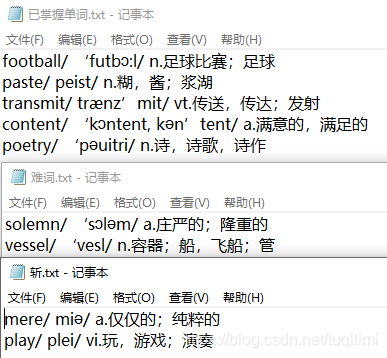 “已掌握的单词.txt”和“斩.txt”中的单词不会再次出现,其他单词在下次背诵过程还可能出现。 再次运行程序,发现单词确实少了7个。
“已掌握的单词.txt”和“斩.txt”中的单词不会再次出现,其他单词在下次背诵过程还可能出现。 再次运行程序,发现单词确实少了7个。 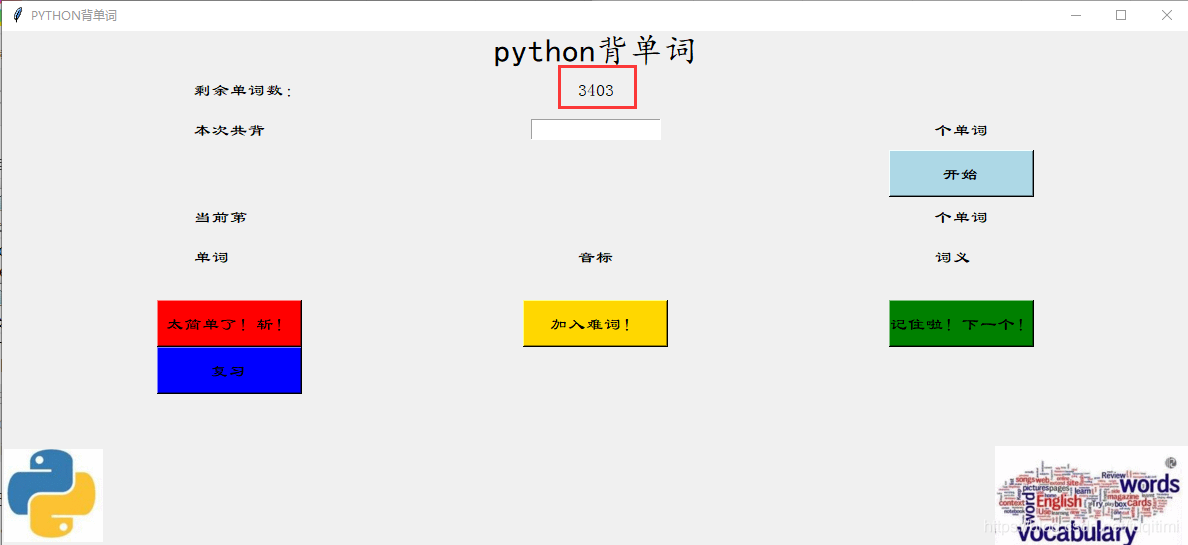

 词库必须是txt格式,txt中的文本格式为“拼写/音标/释义”,比如: abandon/ ə’bændən/ vt.丢弃;放弃,抛弃 aboard/ ə’bɔ:d/ ad.在船(车)上;上船 absolute/ ‘æbsəlu:t/ a.绝对的;纯粹的 absolutely/ ‘æbsəlu:tli/ ad.完全地;绝对地 absorb/ əb’sɔ:b/ vt.吸收;使专心 excursion/ iks’kə:ʃən/ n.远足;短途旅行 excuse/ iks’kju:z, iks’kju:s/ vt.原谅;免除 n.借口 execute/ ‘eksikju:t/ vt.将…处死;实施 executive/ ig’zekjutiv/ a.执行的 n.执行者 exercise/ ‘eksəsaiz/ n.锻炼,训练 vi.练习 exert/ ig’zə:t/ vt.尽(力),运用 fearful/ ‘fiəful/ a.害怕的,可怕的 feasible/ ‘fi:zəbl/ a.可行的;可能的 feather/ ‘feðə/ n.羽毛;翎毛;羽状物 feature/ ‘fi:tʃə/ n.特征,特色;面貌 ʃebruary/ ‘februəri/ n.二月 federal/ ‘fedərəl/ a.联邦的;联盟的 fee/ fi:/ n.费,酬金;赏金
词库必须是txt格式,txt中的文本格式为“拼写/音标/释义”,比如: abandon/ ə’bændən/ vt.丢弃;放弃,抛弃 aboard/ ə’bɔ:d/ ad.在船(车)上;上船 absolute/ ‘æbsəlu:t/ a.绝对的;纯粹的 absolutely/ ‘æbsəlu:tli/ ad.完全地;绝对地 absorb/ əb’sɔ:b/ vt.吸收;使专心 excursion/ iks’kə:ʃən/ n.远足;短途旅行 excuse/ iks’kju:z, iks’kju:s/ vt.原谅;免除 n.借口 execute/ ‘eksikju:t/ vt.将…处死;实施 executive/ ig’zekjutiv/ a.执行的 n.执行者 exercise/ ‘eksəsaiz/ n.锻炼,训练 vi.练习 exert/ ig’zə:t/ vt.尽(力),运用 fearful/ ‘fiəful/ a.害怕的,可怕的 feasible/ ‘fi:zəbl/ a.可行的;可能的 feather/ ‘feðə/ n.羽毛;翎毛;羽状物 feature/ ‘fi:tʃə/ n.特征,特色;面貌 ʃebruary/ ‘februəri/ n.二月 federal/ ‘fedərəl/ a.联邦的;联盟的 fee/ fi:/ n.费,酬金;赏金【本文地址】
今日新闻 |
推荐新闻 |