|
加粗样式在我前面的博客中,通过利用python的requests库和BeautifulSoup库对静态网站进行爬取,但如果遇到动态网站怎么办呢?接下来我们试着通过API来对动态网站进行爬取想要的数据。
目录
(一) 动态网站和静态网站的区别与robots.txt(二) 爬取QQ音乐——“雨爱”的一页评论(三) 爬取QQ音乐——“雨爱”的多页评论
(一) 动态网站和静态网站的区别与robots.txt
在爬取数据之前,我想给大家简单讲一讲动态网站和静态网站的区别,便于大家理解为什么动态网页和静态网页的爬取方法不同。 抛开那些概念来理解,静态网站相当于是提前把网站内容写好的,你看到的内容是不会变的,就像我上一篇博客爬取的豆瓣电影榜top250一样;而动态网站可以根据我们用户的需求而改变,比如评论,只要你去评论,评论就可以更新到网站上。 简单理解了动态网站和静态网站的区别,我们在爬取数据之前还需要了解一个重要的东西——robots.txt robots.txt 是一种存放于网站根目录下的文本文件,用于告诉爬虫此网站中的哪些内容是不应被爬取的,哪些是可以被爬取的,它就相当于互联网的君子协议,需要大家自觉遵守,但不能阻止你去爬取数据,希望大家以后还是好好遵守这个规则。 要想查看robots.txt,我们只要在网站域名后加上 /robots.txt 即可查看,例如今天我们要爬取的是QQ音乐(https://y.qq.com)。 它的robots.txt是:https://y.qq.com/robots.txt,用浏览器打开后如图: 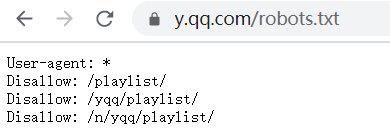 由上面我们可以知道,它禁止我们爬取playlist相关的信息,对我们今天爬取的评论没有影响。 由上面我们可以知道,它禁止我们爬取playlist相关的信息,对我们今天爬取的评论没有影响。
(二) 爬取QQ音乐——“雨爱”的一页评论
下面我们将正式开始爬取评论。首先打开QQ音乐主页(https://y.qq.com),搜索一首你喜欢的歌曲,我用的是我比较喜欢的一首老歌叫“雨爱”,然后进去歌曲主页如下图: 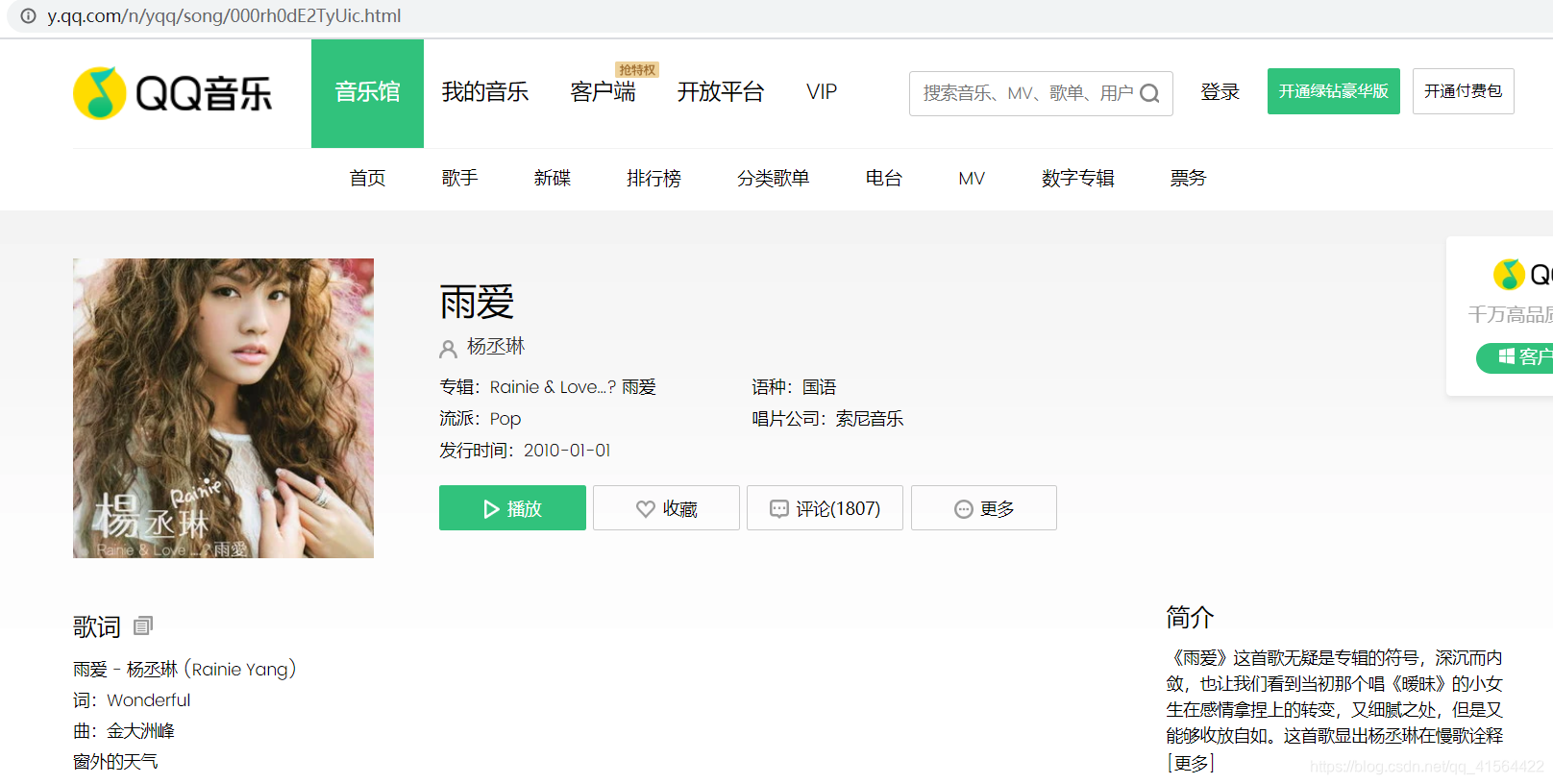 鼠标往下面翻就可以看到歌曲的评论,也就是我们今天要爬取的数据。 接着我们打开开发者工具(ctrl+shift+i),然后点击Network,再选择XHR(我们需要的评论内容就在XHR内),然后我们会看到很多请求信息,如下图: 鼠标往下面翻就可以看到歌曲的评论,也就是我们今天要爬取的数据。 接着我们打开开发者工具(ctrl+shift+i),然后点击Network,再选择XHR(我们需要的评论内容就在XHR内),然后我们会看到很多请求信息,如下图: 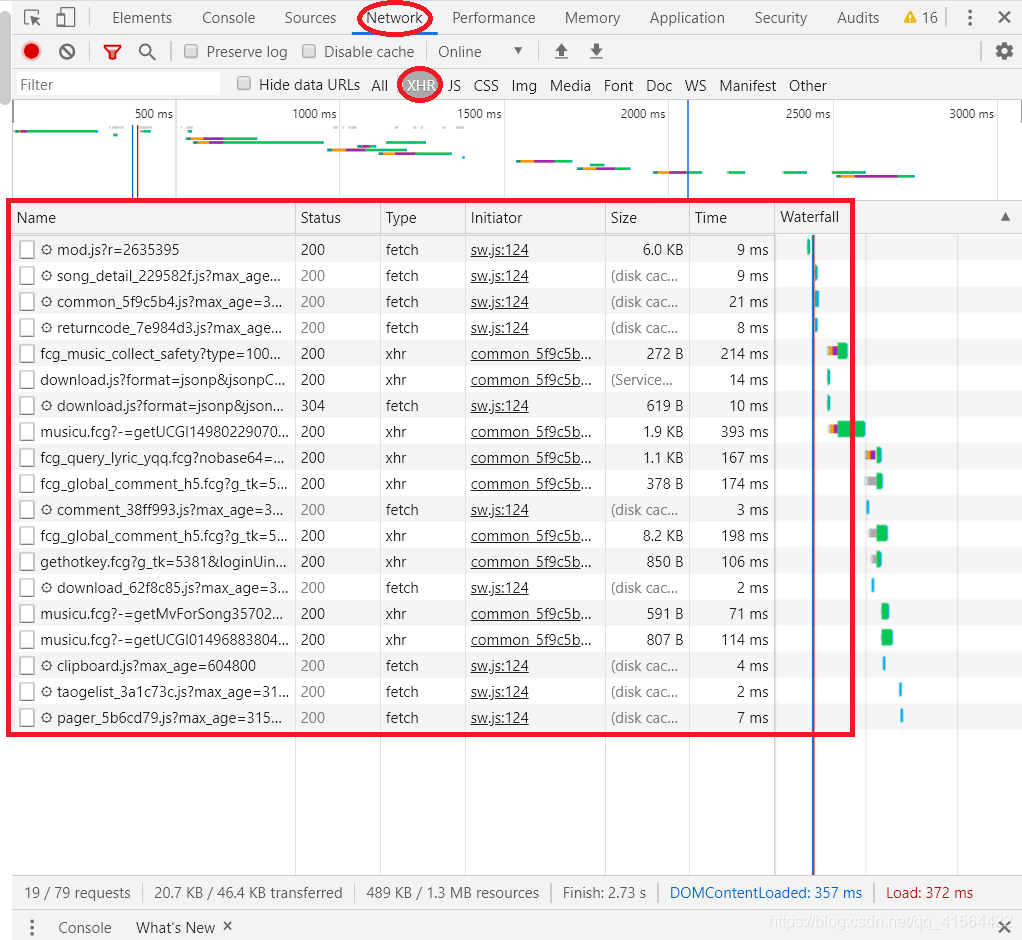 在这些请求中有很多参数,我们目前只需要关注Name和Size,这分别代表了这些请求的名字和大小,而我们爬取的评论一般参数Name中带有comment,参数Size大概超过1kb,很快我们发现满足条件的就只有下图这个。(若有多个满足,就重复下面步骤排除!) 在这些请求中有很多参数,我们目前只需要关注Name和Size,这分别代表了这些请求的名字和大小,而我们爬取的评论一般参数Name中带有comment,参数Size大概超过1kb,很快我们发现满足条件的就只有下图这个。(若有多个满足,就重复下面步骤排除!) 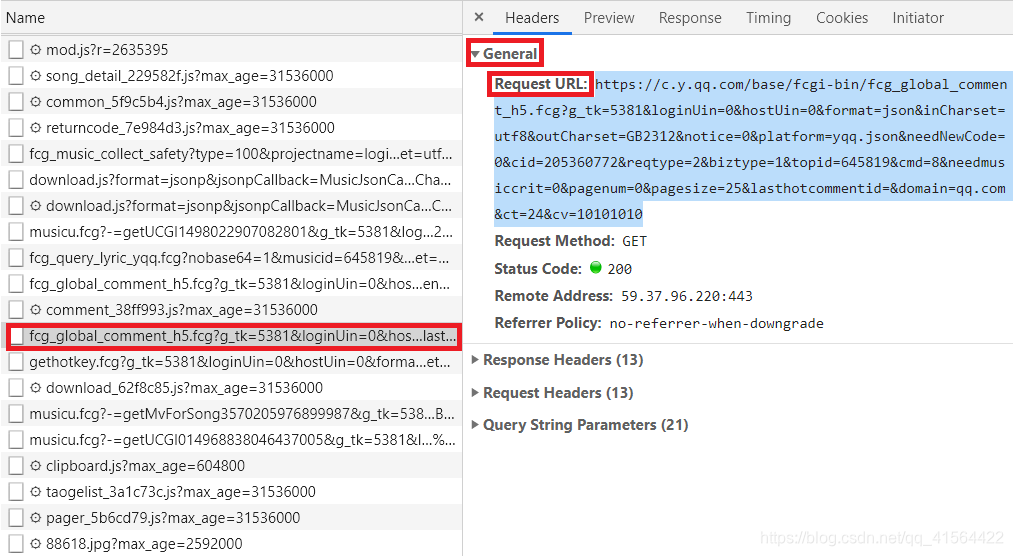 然后我们点开Genral,查看它的Request URL,并将蓝色部分的网址复制用一个新的页面打开,按ctrl+f,随意搜一条评论的内容,看看是不是我们要找的网址。下面我搜取的是第一条评论,发现这就是评论在的网页,如图: 然后我们点开Genral,查看它的Request URL,并将蓝色部分的网址复制用一个新的页面打开,按ctrl+f,随意搜一条评论的内容,看看是不是我们要找的网址。下面我搜取的是第一条评论,发现这就是评论在的网页,如图: 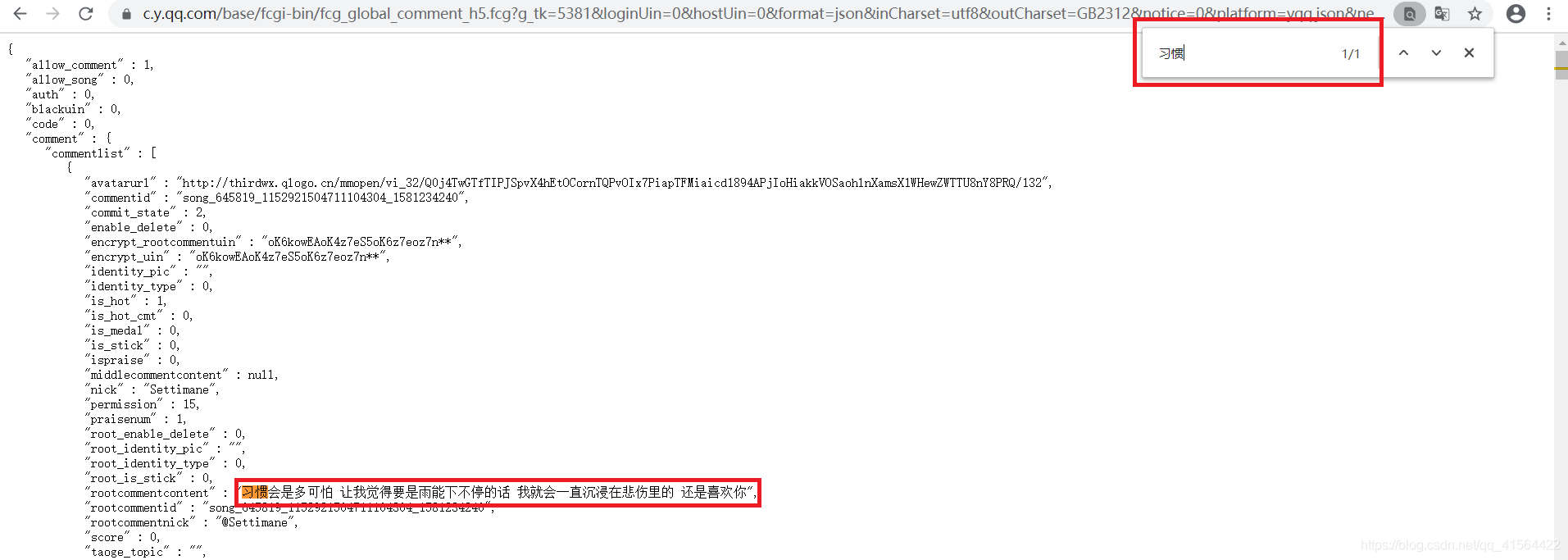 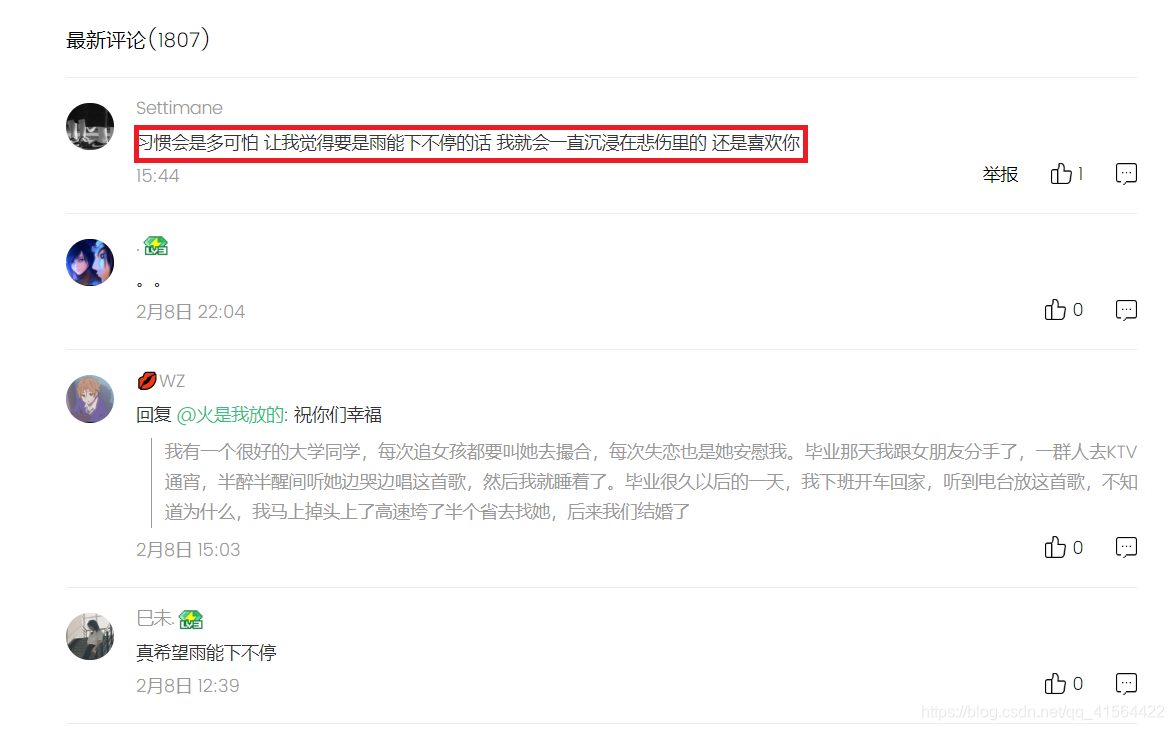 在这个页面我们可以观察得:评论数据在comment下的commentlist中,今天我们就来获取commentlist中 nick(评论者的网名) 和rootcommentcontent(评论内容) 这两个数据。 好了,前期工作做完了,我们来看下代码吧! 在这个页面我们可以观察得:评论数据在comment下的commentlist中,今天我们就来获取commentlist中 nick(评论者的网名) 和rootcommentcontent(评论内容) 这两个数据。 好了,前期工作做完了,我们来看下代码吧!
import requests
# 设置headers参数
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
# 设置params参数
params = {
'g_tk': '5381',
'loginUin': '0',
'hostUin': '0',
'format': 'json',
'inCharset': 'utf8',
'outCharset': 'GB2312',
'notice': '0',
'platform': 'yqq.json',
'needNewCode': '0',
'cid': '205360772',
'reqtype': '2',
'biztype': '1',
'topid': '645819',
'cmd': '8',
'needmusiccrit': '0',
'pagenum': '0',
'pagesize': '25',
'lasthotcommentid': '',
'domain': 'qq.com',
'ct': '24',
'cv': '10101010',
}
# 请求与网站的连接
res = requests.get('https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg', headers = headers, params = params)
# 解析JSON
data = res.json()
# 将一页的评论全部打印出来
for item in data['comment']['commentlist']:
print('{}: {}'.format(item['nick'], item['rootcommentcontent']))
运行结果如下: 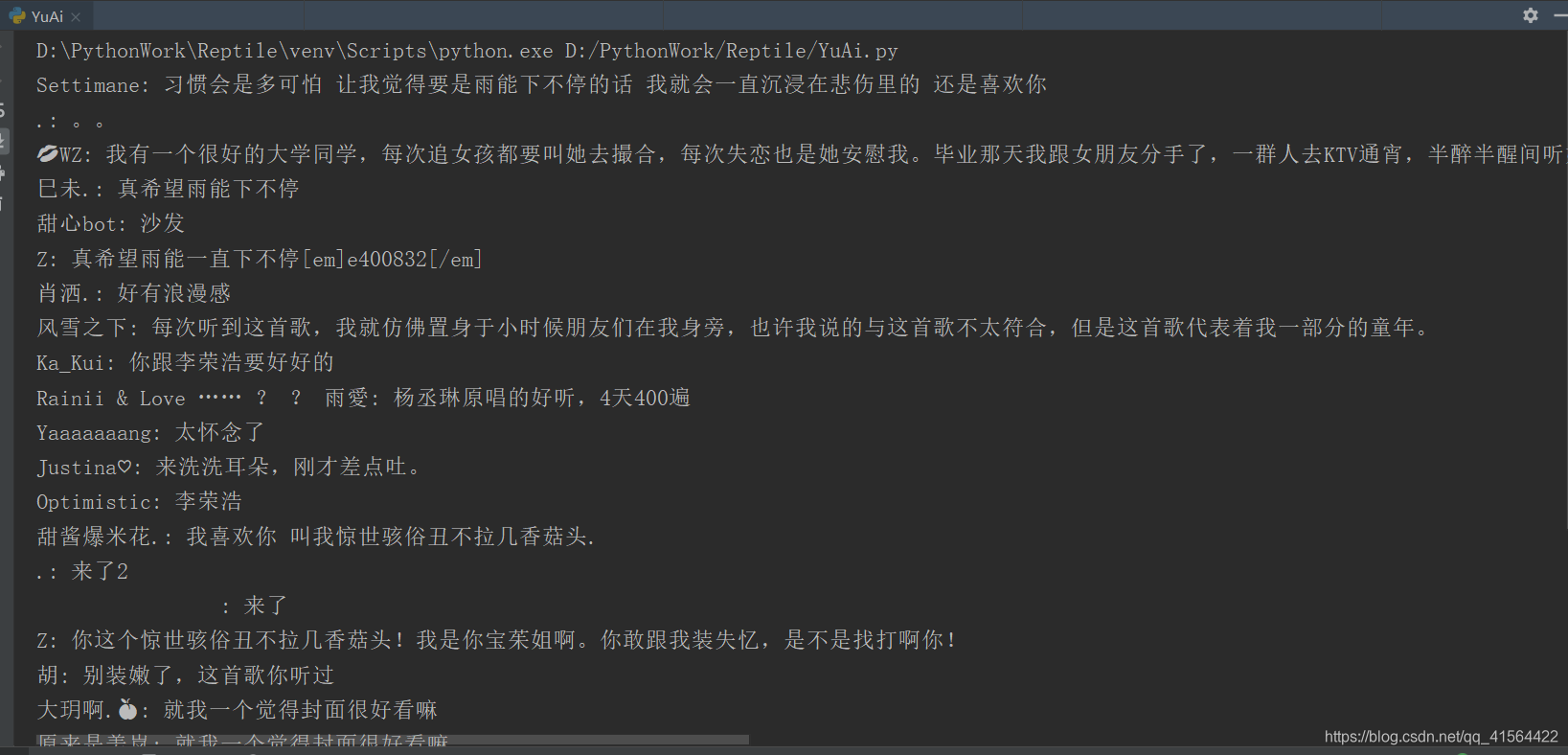 大家可能发现跟爬取静态网站代码相比有两个地方代码不同,第一个是params参数,它的作用是以字典的形式传递链接的查询字符串参数,使代码看上去更加的整洁明了,让我们上面获取的Request URL变得更简洁,有兴趣的朋友可以自己去了解下,直接用原来的Request URL也是可以的;第二个地方是多了一个解析JSON,这个的作用是将刚才获取的数据(也就是JSON),转换成字典。 大家可能发现跟爬取静态网站代码相比有两个地方代码不同,第一个是params参数,它的作用是以字典的形式传递链接的查询字符串参数,使代码看上去更加的整洁明了,让我们上面获取的Request URL变得更简洁,有兴趣的朋友可以自己去了解下,直接用原来的Request URL也是可以的;第二个地方是多了一个解析JSON,这个的作用是将刚才获取的数据(也就是JSON),转换成字典。
(三) 爬取QQ音乐——“雨爱”的多页评论
在学会怎么爬取一页评论后,我们来怎么爬取多页或者所有的评论。首先在第一页评论中打开开发者工具(ctrl+shift+i),然后点击Network,再选择XHR,再点击刚才那个请求,再点击它Headers,再点开Query String Parameters。再打开第二页评论重复上述步骤,对比它们的Query String Parameters,我们可以发现其中的pagenum和lasthotcommentid两个的值发生了变化。 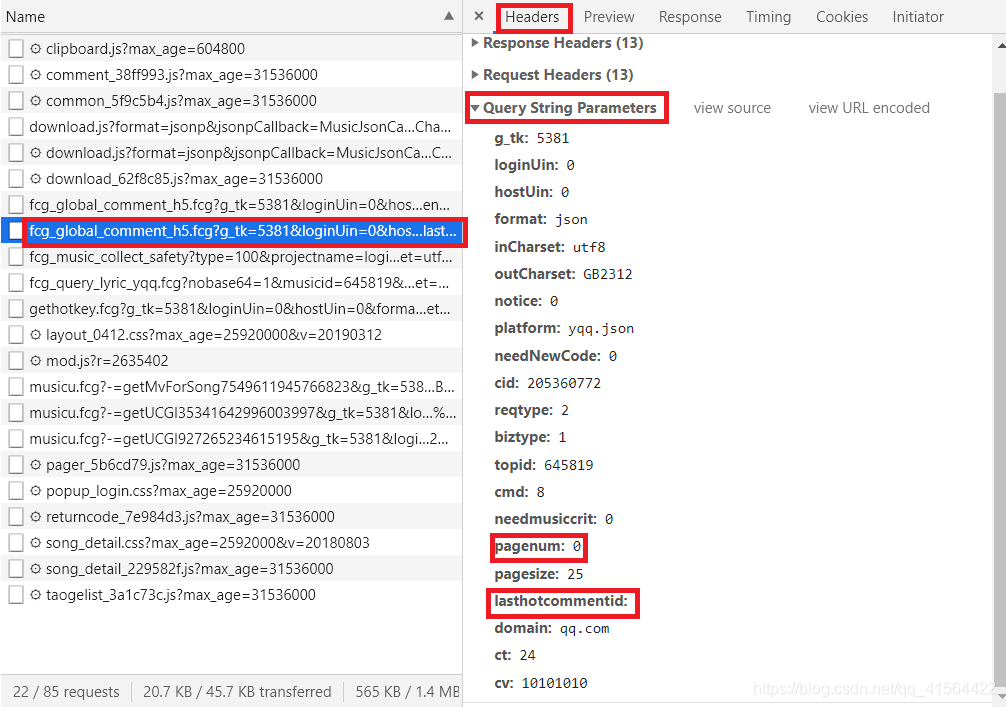 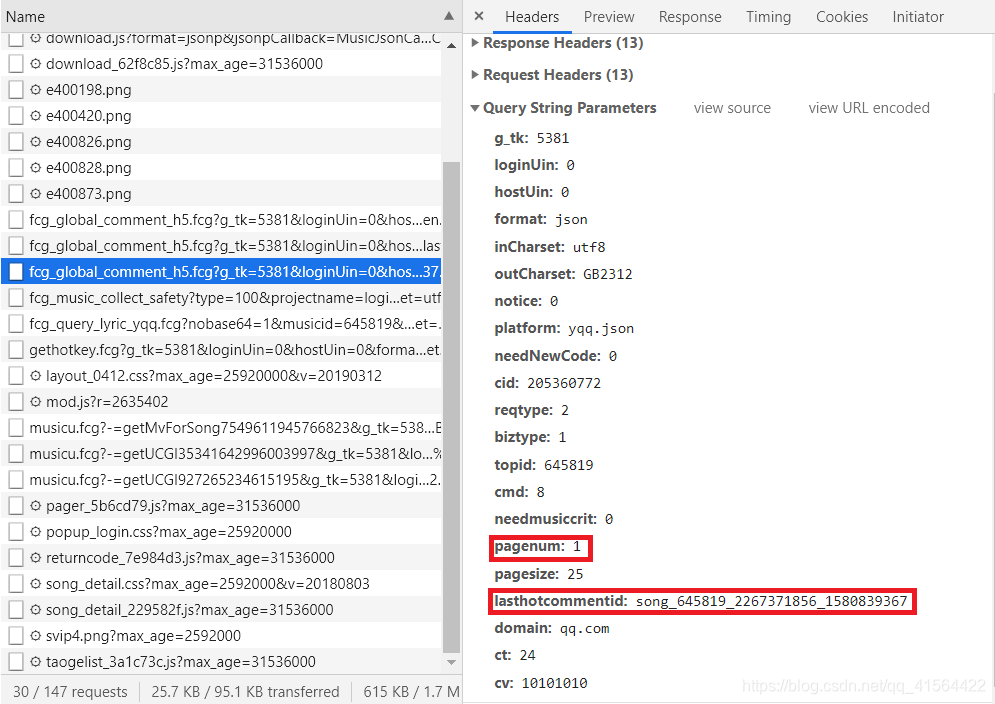 可以多打开几页的评论,我们发现pagenum每次都加1,相当于翻了一页;而 lasthotcommentid 是上一页最后一个评论的 commentid,相当于连接两页评论的标识。找到规律后我们就可以开始写我们的整个代码啦!我们先爬取前五页的评论试试。 可以多打开几页的评论,我们发现pagenum每次都加1,相当于翻了一页;而 lasthotcommentid 是上一页最后一个评论的 commentid,相当于连接两页评论的标识。找到规律后我们就可以开始写我们的整个代码啦!我们先爬取前五页的评论试试。
import requests
import time
# 设置headers参数
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
# 爬取前五页的评论
for pagenum in range(5):
# 第一次lasthotcommentid为空
lasthotcommentid = ''
params = {
'g_tk': '5381',
'loginUin': '0',
'hostUin': '0',
'format': 'json',
'inCharset': 'utf8',
'outCharset': 'GB2312',
'notice': '0',
'platform': 'yqq.json',
'needNewCode': '0',
'cid': '205360772',
'reqtype': '2',
'biztype': '1',
'topid': '645819',
'cmd': '8',
'needmusiccrit': '0',
'pagenum': pagenum,
# pagesize改为100,可以提高爬取速度
'pagesize': '25',
'lasthotcommentid': lasthotcommentid,
'domain': 'qq.com',
'ct': '24',
'cv': '10101010',
}
# 请求与网站的连接
res = requests.get('https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg', headers=headers, params=params)
# 解析JSON
data = res.json()
# 将一页的评论全部打印出来
for item in data['comment']['commentlist']:
print('{}: {}'.format(item['nick'], item['rootcommentcontent']))
# 当前页最后一个评论的 commentid 作为下一页的 lasthotcommentid
lasthotcommentid = data['comment']['commentlist'][-1]['commentid']
# 防止爬取太快被封
time.sleep(1)
部分运行结果: 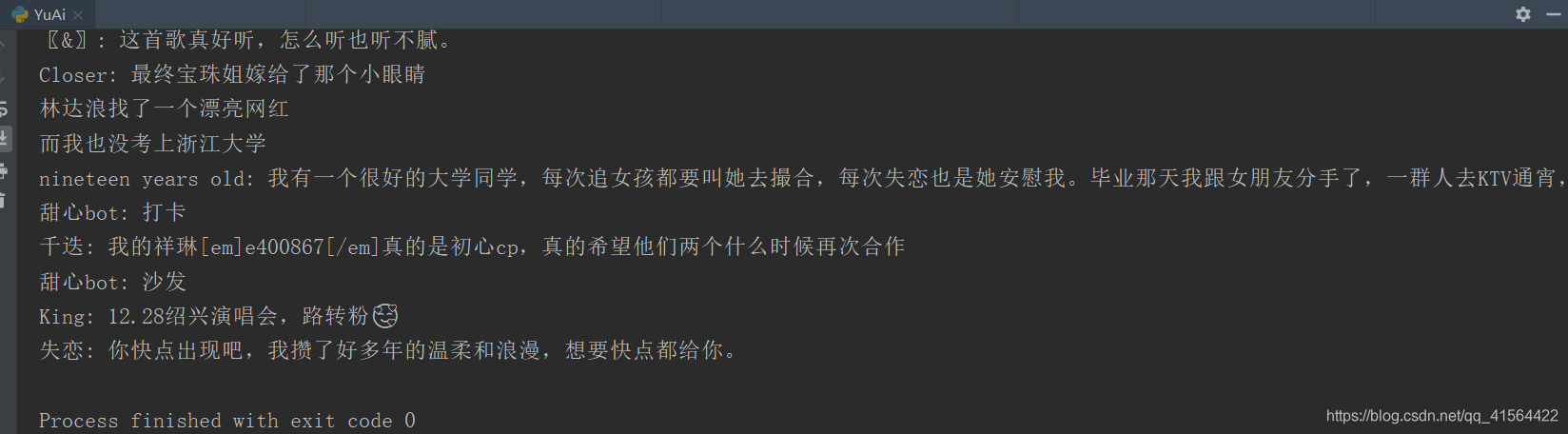 以上就是所有主要步骤和代码啦,大家可以试试去爬取所有的评论哦,还有就是将参数pagesize改为100,可以提高爬取速度,但不要太大哈。如果大家有什么问题请随时指正,互相学习,一起进步! 以上就是所有主要步骤和代码啦,大家可以试试去爬取所有的评论哦,还有就是将参数pagesize改为100,可以提高爬取速度,但不要太大哈。如果大家有什么问题请随时指正,互相学习,一起进步!
|