Python在HTML内提取元素 |
您所在的位置:网站首页 › python获取字符串中特定内容 › Python在HTML内提取元素 |
Python在HTML内提取元素
|
使用Beautiful Soup 提取HTML里面的内容
(1)基本用法(2)提取HTML里面的内容1)获取名称2)获取属性3)获取内容4)嵌套选择5)关联选择(Ⅰ)子节点和子孙节点(Ⅱ)父节点和祖先节点(Ⅲ)兄弟节点
6)方法选择器7)CSS选择器8)总结:
Beautiful Soup:简单来说,Beautiful Soup就是Python的一个HTML或XML的解析库,可以用它来方便地从网页中提取数据。Beautiful Soup在解析时实际上依赖解析器,它除了支持Python标准库中的HTML解析器外,还支持一些第三方解析器(比如lxml)。下面是一些常见的解析器: Once upon a time there were three little sisters; and their names were , Lacie and Tillie; and they lived at the bottom of a well. ... """ soup = BeautifulSoup(html, 'lxml') #print(soup) print(soup.prettify()) # 使用prettify()格式化显示输出运行结果如下: The Dormouse's story Once upon a time there were three little sisters; and their names were Elsie Lacie and Tillie and they lived at the bottom of a well. ... 得到一个BeautifulSoup对象后,一般通过BeautifulSoup类的基本元素来提取html中的内容:
可以利用name属性获取节点的名称。这里还是以上面的文本为例,选取title节点,然后调用name属性就可以得到节点名称: print(soup.title) print(type(soup.title)) print(soup.title.name) #获取title的名字 print(soup.title.string) #获取title字符串里面的内容 print(soup.title.get_text()) #获取title字符串里面的内容对应结果如下: The Dormouse's story title The Dormouse's story The Dormouse's story首先打印输出title节点的选择结果,输出结果正是title节点加里面的文字内容。接下来,输出它的类型,是bs4.element.Tag类型,这是Beautiful Soup中一个重要的数据结构。经过选择器选择后,选择结果都是这种Tag类型。Tag具有一些属性,比如string属性,调用该属性,可以得到节点的文本内容,所以接下来的输出结果正是节点的文本内容。 当有多个节点时,这种选择方式只会选择到第一个匹配的节点,其他的后面节点都会忽略。 print(soup.p)结果如下: The Dormouse's story我们发现结果是第一个p节点的内容,后面的几个p节点并没有选到。 2)获取属性每个节点可能有多个属性,比如id和class等,选择这个节点元素后,可以调用attrs获取所有属性: print(soup.p) print(soup.p.attrs) print(soup.p.attrs["name"])结果如下: The Dormouse's story {'class': ['title'], 'name': 'dromouse'} dromouse可以看到,attrs的返回结果是字典形式,它把选择的节点的所有属性和属性值组合成一个字典。接下来,如果要获取name属性,就相当于从字典中获取某个键值,只需要用中括号加属性名就可以了。比如,要获取name属性,就可以通过attrs['name']来得到。 3)获取内容可以利用string属性或get_text()获取节点元素包含的文本内容,比如要获取第一个p节点的文本: print(soup.p) print(soup.p.string) print(soup.p.get_text())结果如下: The Dormouse's story The Dormouse's story The Dormouse's story 4)嵌套选择在上面的例子中,我们知道每一个返回结果都是bs4.element.Tag类型,它同样可以继续调用节点进行下一步的选择。比如,我们获取了head节点元素,我们可以继续调用head来选取其内部的title节点元素: print(soup.head.title) print(type(soup.head.title)) print(soup.head.title.string)运行结果如下: The Dormouse's story The Dormouse's story第一行结果是调用head之后再次调用title而选择的title节点元素。然后打印输出了它的类型,可以看到,它仍然是bs4.element.Tag类型。也就是说,我们在Tag类型的基础上再次选择得到的依然还是Tag类型,每次返回的结果都相同,所以这样就可以做嵌套选择了。(判断是否是bs4.element.Tag类型:if isinstance(soup,bs4.element.Tag))。 5)关联选择在做选择的时候,有时候不能做到一步就选到想要的节点元素,需要先选中某一个节点元素,然后以它为基准再选择它的子节点、父节点、兄弟节点等,这里就来介绍如何选择这些节点元素。 (Ⅰ)子节点和子孙节点选取节点元素之后,如果想要获取它的直接子节点,可以调用contents属性,示例如下: print(soup.p.contents)运行结果如下: ['\n Once upon a time there were three little sisters; and their names were\n ', Elsie , '\n', Lacie, ' \n and\n ', Tillie, '\n and they lived at the bottom of a well.\n ']可以看到,返回结果是列表形式。p节点里既包含文本,又包含节点,最后会将它们以列表形式统一返回。 需要注意的是,列表中的每个元素都是p节点的直接子节点。比如第一个a节点里面包含一层span节点,这相当于孙子节点了,但是返回结果并没有单独把span节点选出来。所以说,contents属性得到的结果是直接子节点的列表。 同样,我们可以调用children属性得到相应的结果: for i, child in enumerate(soup.p.children): print(i, child)运行结果如下: 0 Once upon a time there were three little sisters; and their names were 1 Elsie 2 3 Lacie 4 and 5 Tillie 6 and they lived at the bottom of a well. (Ⅱ)父节点和祖先节点如果要获取某个节点元素的父节点,可以调用parent属性: soup = BeautifulSoup(html, 'lxml') print(soup.a.parent)运行结果如下: Once upon a time there were three little sisters; and their names were , Lacie and Tillie; and they lived at the bottom of a well.这里我们选择的是第一个a节点的父节点元素。很明显,它的父节点是p节点,输出结果便是p节点及其内部的内容。 需要注意的是,这里输出的仅仅是a节点的直接父节点,而没有再向外寻找父节点的祖先节点。如果想获取所有的祖先节点,可以调用parents属性。 (Ⅲ)兄弟节点可以用next_sibling和previous_sibling分别获取节点的下一个和上一个兄弟元素,next_siblings和previous_siblings则分别返回所有前面和后面的兄弟节点的生成器。 6)方法选择器Beautiful Soup还为我们提供了一些查询方法,比如find_all()和find()等,调用它们,然后传入相应的参数,就可以灵活查询了。 '''它的API如下:''' find_all(name , attrs , recursive , text , **kwargs)调用了find_all()方法,传入name , attrs , recursive , text , **kwargs参数,返回结果是列表类型,每个元素依然如果都是bs4.element.Tag类型,所以依然可以进行嵌套查询。 例如: html=''' Hello Foo Bar Jay Foo Bar ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'lxml') for ul in soup.find_all(name='ul'): print(ul.find_all(name='li'))运行结果如下: [Foo, Bar, Jay] [Foo, Bar]返回结果是列表类型,列表中的每个元素依然还是Tag类型。接下来,就可以遍历每个li,获取它的文本了: 除了find_all()方法,还有find()方法,只不过后者返回的是单个元素,也就是第一个匹配的元素,而前者返回的是所有匹配的元素组成的列表。find()返回结果不再是列表形式,而是第一个匹配的节点元素,类型依然是Tag类型。 7)CSS选择器使用CSS选择器时,只需要调用select()方法,传入相应的CSS选择器即可,示例如下: html=''' Hello Foo Bar Jay Foo Bar ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'lxml') print(soup.select('.panel .panel-heading')) print(soup.select('ul li')) print(soup.select('#list-2 .element')) print(type(soup.select('ul')[0]))运行结果如下: [ Hello ] [Foo, Bar, Jay, Foo, Bar] [Foo, Bar]这里我们用了3次CSS选择器,返回的结果均是符合CSS选择器的节点组成的列表。例如,select('ul li')则是选择所有ul节点下面的所有li节点,结果便是所有的li节点组成的列表。 最后一句打印输出了列表中元素的类型。可以看到,类型依然是Tag类型。 嵌套选择 select()方法同样支持嵌套选择。例如,先选择所有ul节点,再遍历每个ul节点,选择其li节点,样例如下: from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'lxml') for ul in soup.select('ul'): print(ul.select('li'))运行结果如下: [Foo, Bar, Jay] [Foo, Bar]可以看到,这里正常输出了所有ul节点下所有li节点组成的列表。 8)总结:① 到此,Beautiful Soup的用法基本就介绍完了,最后做一下简单的总结。 ② 推荐使用lxml解析库,必要时使用html.parser。 ③ 节点选择筛选功能弱但是速度快。 ④ 建议使用find()或者find_all()查询匹配单个结果或者多个结果。 ⑤ 如果对CSS选择器熟悉的话,可以使用select()方法选择。 |
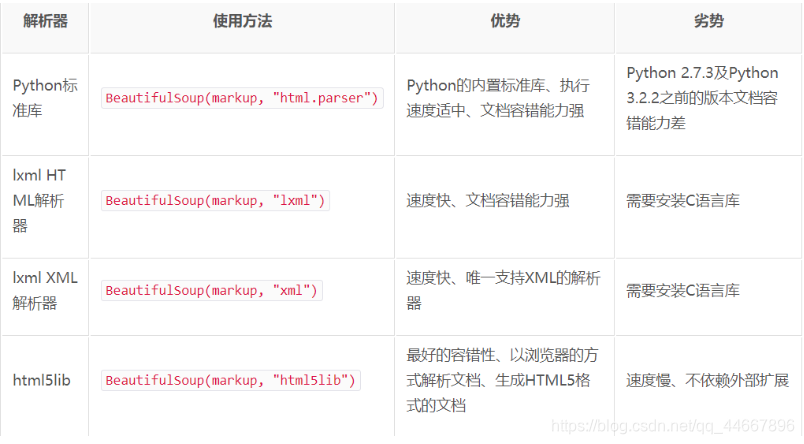 ** 通过以上对比可以看出,lxml解析器有解析HTML和XML的功能,而且速度快,容错能力强,所以推荐使用它。**
** 通过以上对比可以看出,lxml解析器有解析HTML和XML的功能,而且速度快,容错能力强,所以推荐使用它。**
【本文地址】
今日新闻 |
推荐新闻 |