|
爬取静态网页的技术
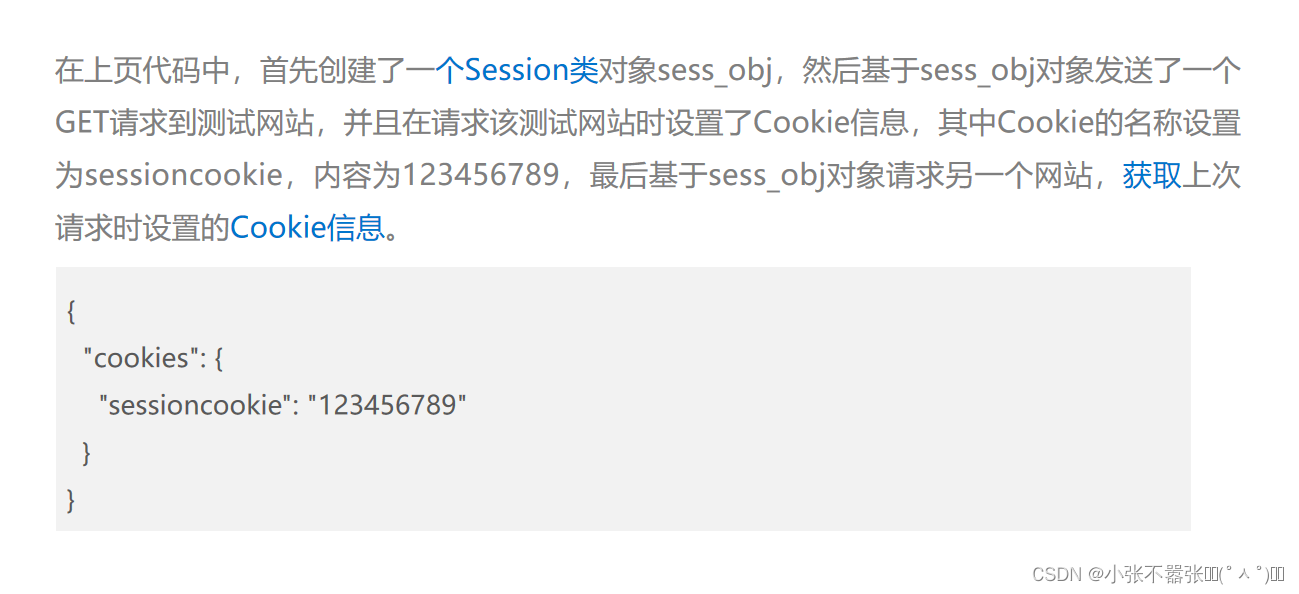
数据请求模块一、Requests库发送GET请求发送POST请求get请求和post请求两者之间的区别处理响应定制请求头验证Cookie保持会话
二、urllib库
数据解析模块正则表达式re模块的使用
XPath需要通过lxml库
Beautiful SoupJSONPath
静态网页结构都是HTML语法,所以说我们想要爬取这个静态网页我们只需要爬取这个网页的源代码就好了,而我们的网络爬虫就是模仿用户访问浏览器的过程,包括想Web服务器发送HTTP请求,服务器对HTTP请求作出响应并返回网页源代码的过程
为帮助开发人员抓取静态网页数据,减少开发人员的开发时间,Python提供了一些功能齐全的库,
包括urllib、urllib3和Requests,其中urllib是Python内置库,无须安装便可以直接在程序中使用;
urllib3和Requests都是第三方库,需要另行安装后才可以在程序中使用。
第三方库的安装参考相关文章
数据请求模块
一、Requests库
发送GET请求
在Requests库中,GET请求通过调用get()函数发送,该函数会根据传入的URL构建一个请求(每个请求都是Request类的对象),将该请求发送给服务器  
import requests
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.42"
}
url1 = 'http://www.baidu.com/s'
data={'wd':'python'}
# response =requests.get('https://xdclass.net/#/index',headers=headers)
response=requests.get(url1,params=data,headers=headers)
# print(response.status_code) 响应信息
response.encoding='utf-8'
print(response.text) #text是爬取的源代码字符串输出
# print(response.content.decode('utf-8'))
#
# print(response.headers)
# print(response.cookies)
发送POST请求
在Requests中,POST请求可以通过调用post()函数发送,post()函数会根据传入的URL构建一个请求,将该请求发送给服务器,并接收服务器成功响应后返回的响应信息。post()函数的声明如下: 
import requests
base_url = 'http://mp-meiduo-python.itheima.net/login/'
## 准备请求数据
form_data = {
'csrfmiddlewaretoken':'FDb8DNVnlcFGsjIONtwiQoi6PtmCLeBsRgyjx2o2nsZ4MXDEGDeM2dUImEkj9O7t',
'username': 'admin',
'pwd': 'admin',
'remembered': 'on'}
response = requests.post(base_url, data=form_data) # 根据URL构造请求,发送POST请求
print(response.status_code) # 查看响应信息的状态码
get请求和post请求两者之间的区别
GET请求 – 参数都显示在URL上,服务器根据该请求所包含URL中的参数来产生响应内容。 由于请求参数都暴露在外,所以安全性不高。 POST请求 – 参数在请求体当中,消息长度没有限制而且采取隐式发送,通常用来向HTTP服务器提交量比较大的数据。 POST请求的参数不在URL中,而在请求体中,所以安全性也高,使用场合也比GET多。
处理响应
在Requests库中,Response类的对象中封装了服务器返回的响应信息 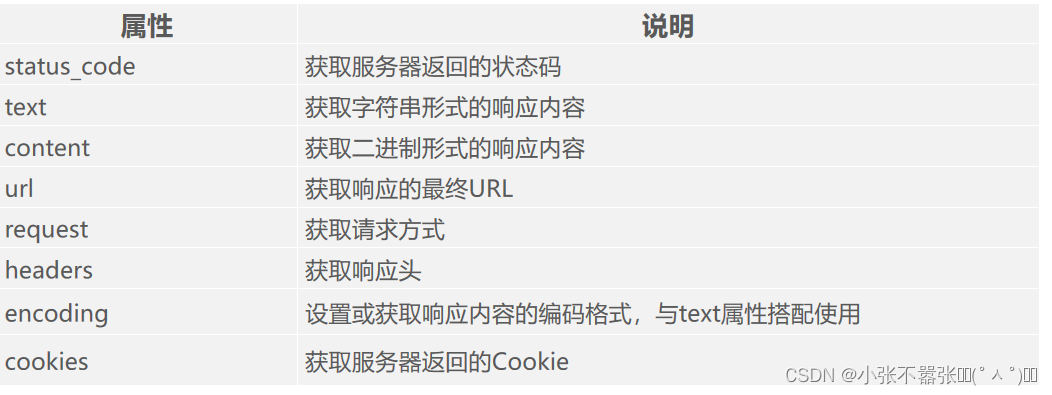
# 通过访问Response类对象的text属性可以获取字符串形式的网页源代码。
import requests
base_url = 'https://www.baidu.com/'
# 根据URL构造请求,发送GET请求,接收服务器返回的响应信息
response = requests.get(url=base_url)
# 查看响应内容
print(response.text)
#为了保证获取的源代码中能够正常显示中文,这里需要通过Response对象的encoding属性将编码格式设置为UTF-8
import requests
base_url = 'https://www.baidu.com/'
# 根据URL构造请求,发送GET请求,接收服务器返回的响应信息
response = requests.get(url=base_url)
# 设置响应内容的编码格式
response.encoding = 'utf-8'
# 查看响应内容
print(response.text)
#使用content属性获取该图片对应的二进制数据,并将数据写入到本地文件中。
import requests
base_url = 'https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png'
response = requests.get(base_url)
# 获取百度Logo图片对应的二进制数据
print(response.content)
# 将二进制数据写入程序所在目录下的baidu_logo.png文件中
with open('baidu_logo.png', 'wb') as file:
file.write(response.content)
定制请求头
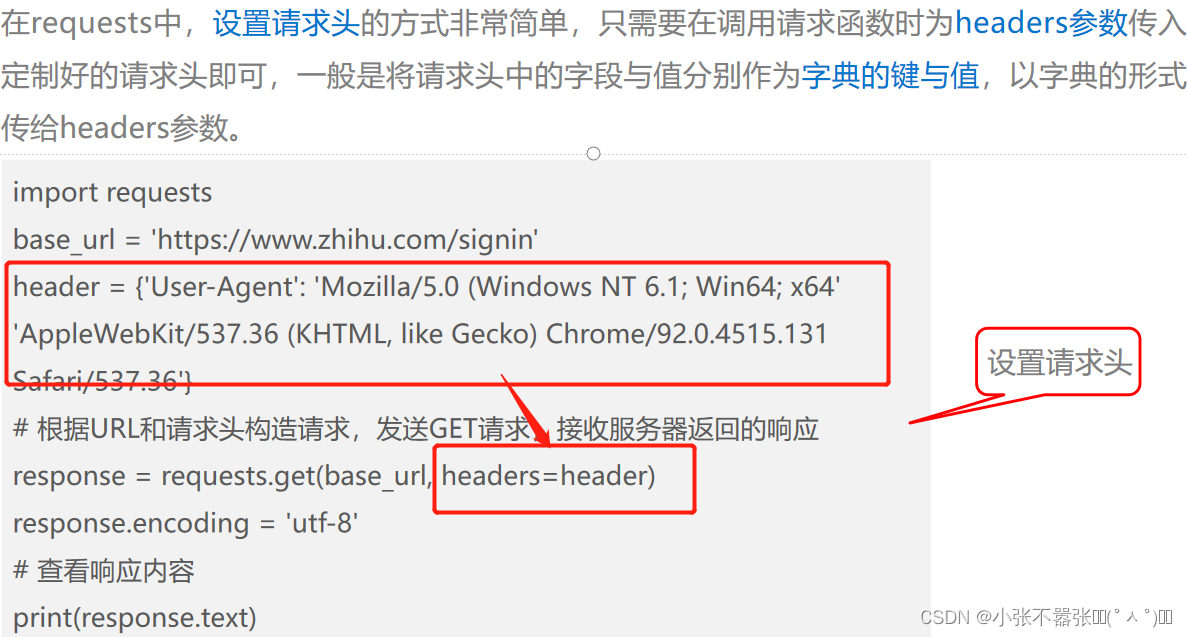
验证Cookie
 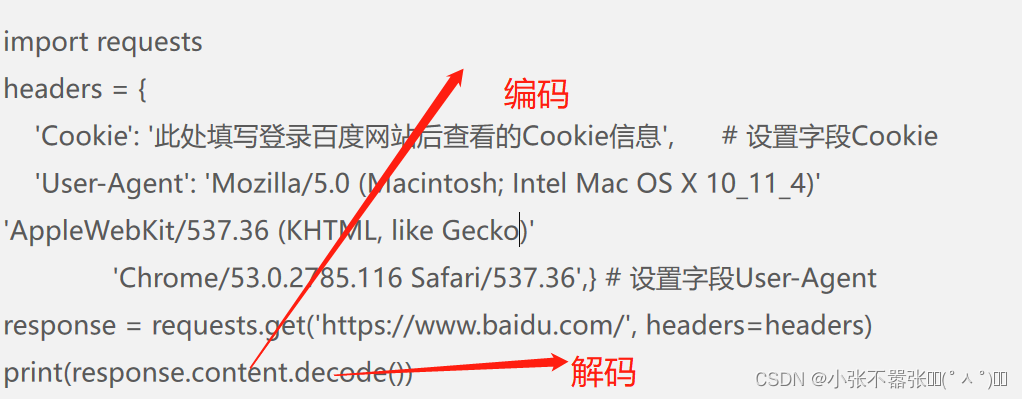
保持会话
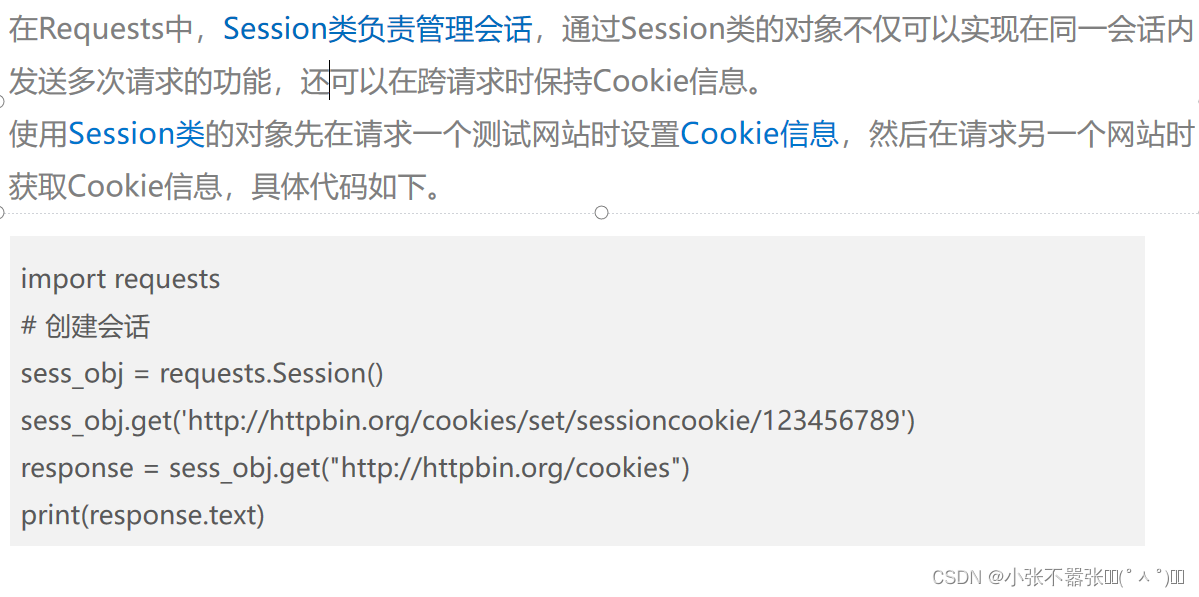 
二、urllib库
简单案例:
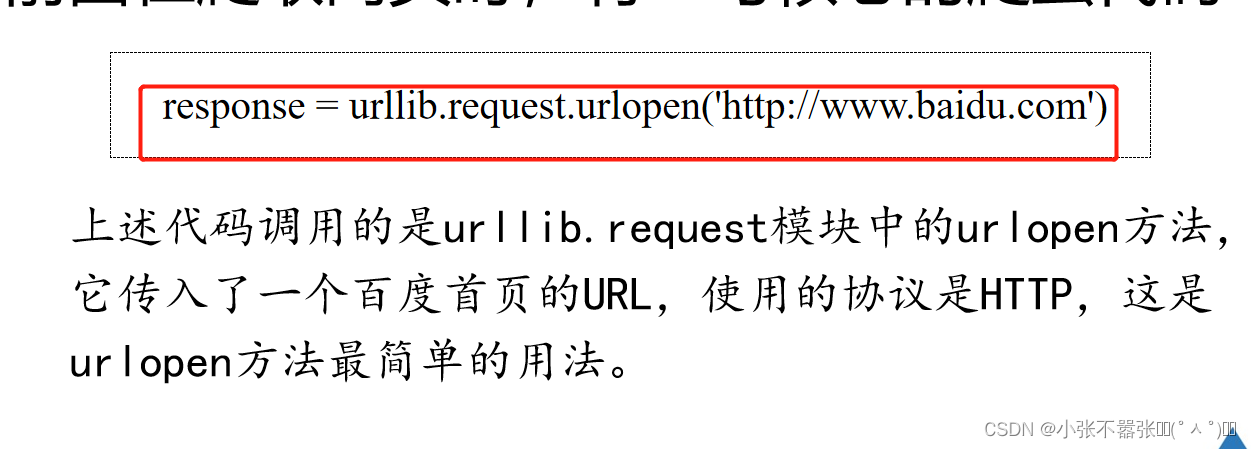
mport urllib.request
# 调用urllib.request库的urlopen方法,并传入一个url
response = urllib.request.urlopen('http://www.baidu.com')
# 使用read方法读取获取到的网页内容
html = response.read().decode('UTF-8')
# 打印网页内容
print(html)
   如果希望对请求执行复杂操作,则需要创建一个Request对象来作为urlopen方法的参数。 如果希望对请求执行复杂操作,则需要创建一个Request对象来作为urlopen方法的参数。
# 将url作为Request方法的参数,构造并返回一个Request对象
request = urllib.request.Request('http://www.baidu.com')
# 将Request对象作为urlopen方法的参数,发送给服务器并接收响应
response = urllib.request.urlopen(request)
 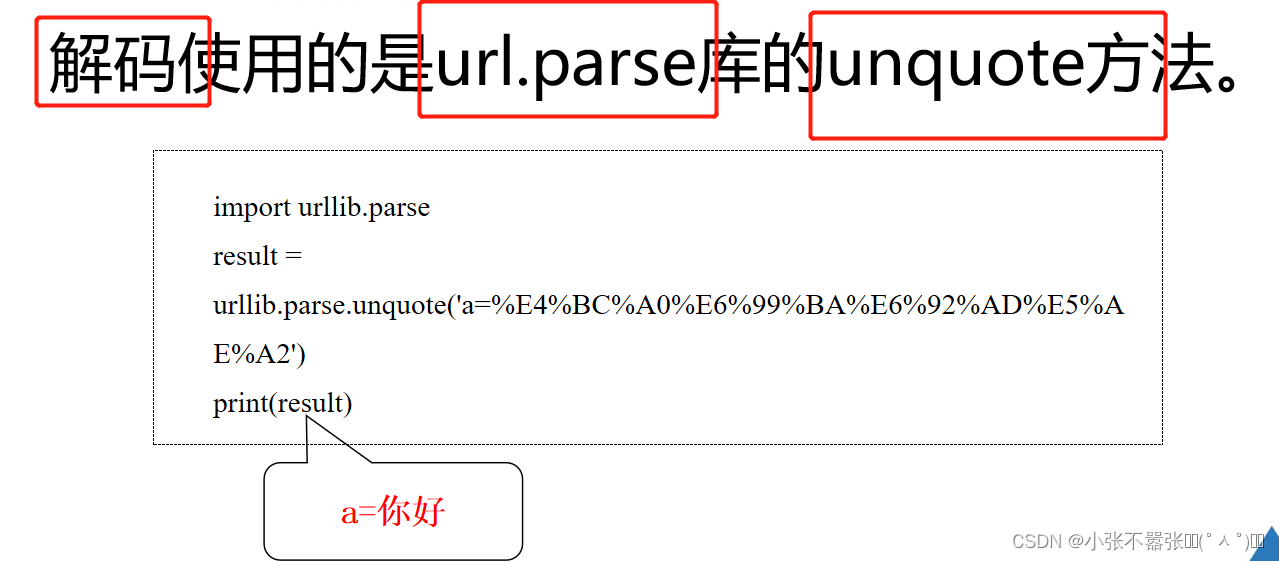
数据解析模块
 
正则表达式
正则表达式是基于文本的特征来匹配或查找指定的数据,它可以处理任何格式的字符串文档,类似于模糊匹配的效果 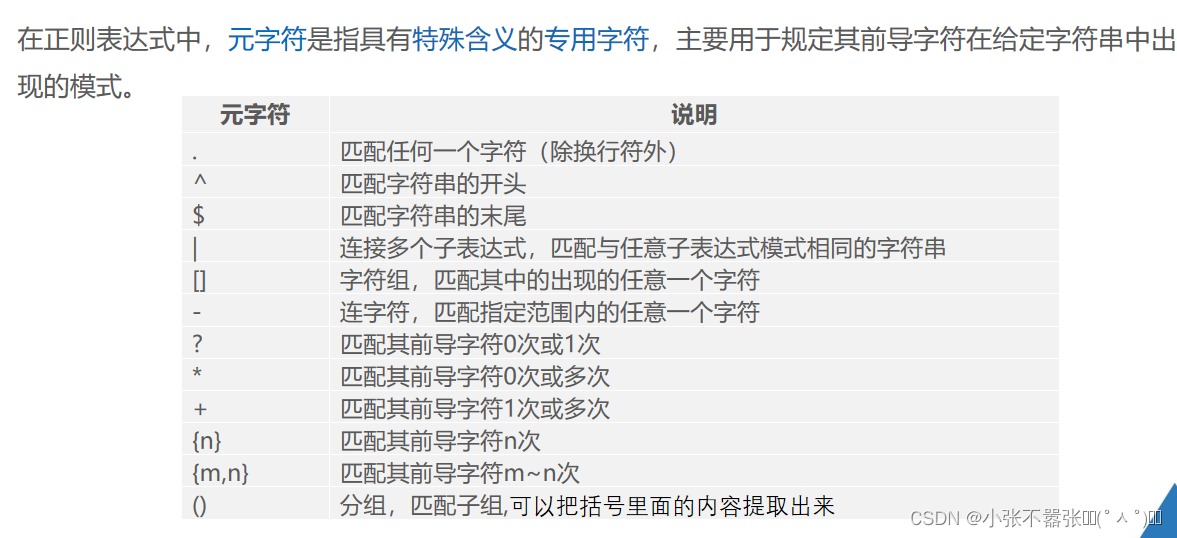 
re模块的使用
Python中提供了re模块操作正则表达式,该模块中提供了丰富的函数或方法来实现文本匹配查找、文本替换、文本分割等功能。re模块的使用一般可以分为两步,分别是创建Pattern对象和全文匹配。 使用compile()函数对正则表达式进行预编译,从而生成一个代表正则表达式的Pattern对象。 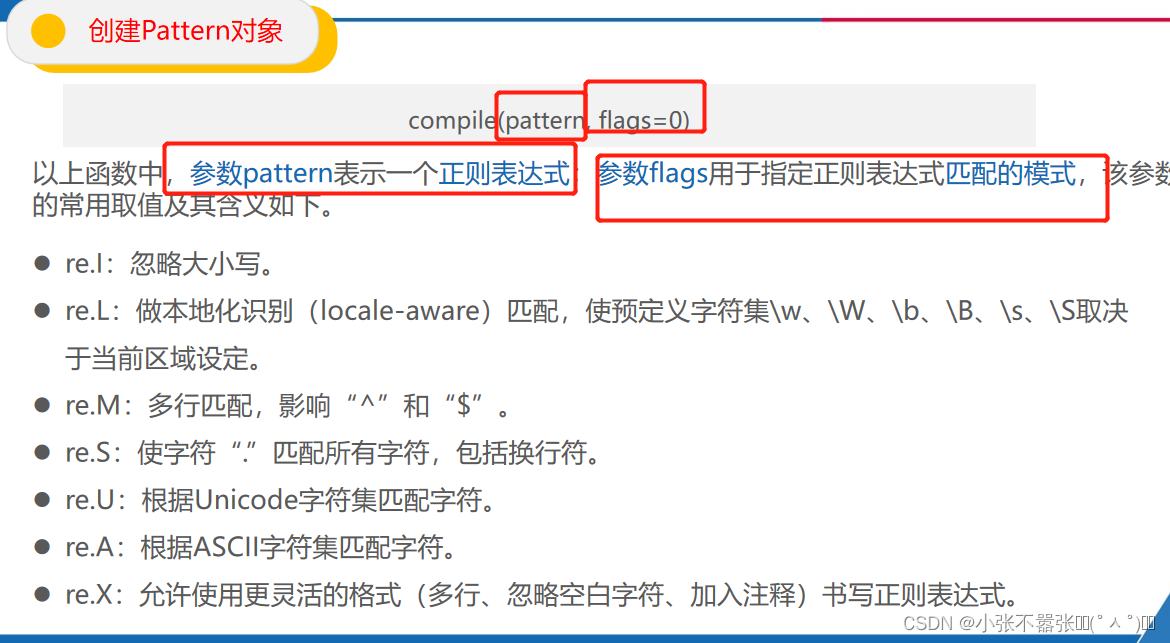 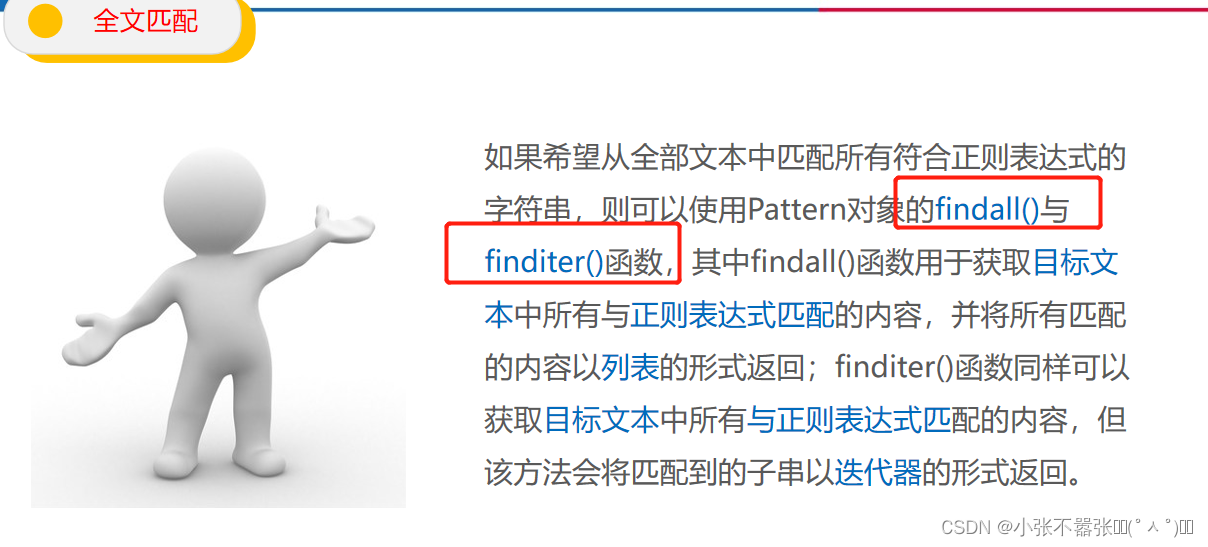
import re
string = "狗的英文:dog,猫的英文:cat。"
pattern= re.compile(r“[\u4e00-\u9fa5]+”)#中文对应的Unicode编码范围
print(re.findall(pattern, string))或者print(pattern.findall(string))
XPath
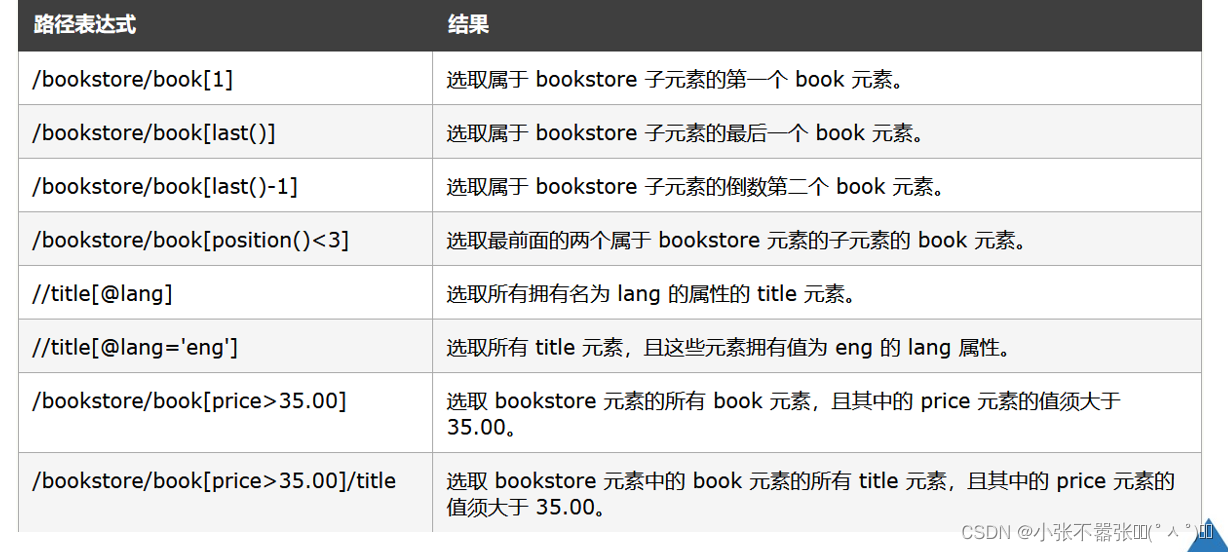
XPath和Beautiful Soup 基于HTML/XML文档的层次结构来确定到达指定节点的路径,所以它们更适合处理层级比较明显的数据。 XPath使用路径表达式选取XML文档中的节点或者节点集,这些路径表达式代表着从一个节点到另一个或者一组节点的顺序,并以“/”字符进行分隔。
需要通过lxml库

from lxml import etree
string1="""
我需要的信息1
我需要的信息2
我需要的信息3
我需要的信息4
我需要的信息5
我需要的信息6
"""
select =etree.HTML(string1)
text=select.xpath('//div[@class="useless"]/ul/li/text()')
print(text)
Beautiful Soup
XPath和Beautiful Soup 基于HTML/XML文档的层次结构来确定到达指定节点的路径,所以它们更适合处理层级比较明显的数据。 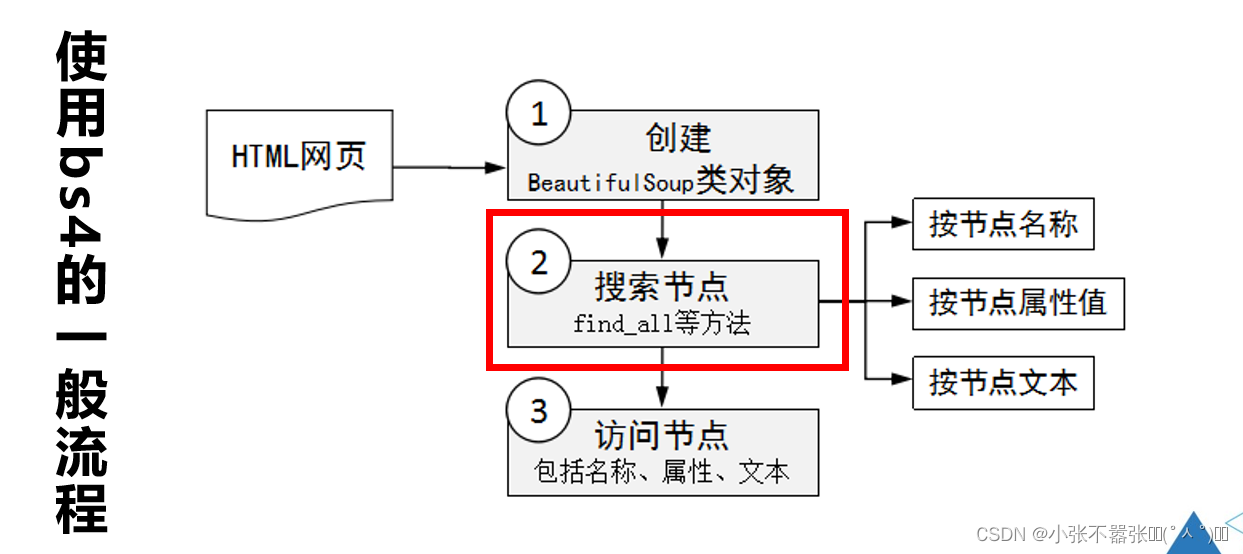 通过一个示例来演示如何创建BeautifulSoup类的对象,具体代码如下所示。 通过一个示例来演示如何创建BeautifulSoup类的对象,具体代码如下所示。
1 from bs4 import BeautifulSoup
2 html_doc = """The Dormouse's story
3
4 The Dormouse's story
5 Once upon a time there were three little sisters;
6 and their names were
7 Elsie,
8 Lacie and
9 Tillie;
10 and they lived at the bottom of a well.
11 ...
12 """
13 # 根据html_doc创建BeautifulSoup类的对象,并指定使用lxml解析器解析文档
14 soup = BeautifulSoup(html_doc, features='lxml')
15 print(soup.prettify())# prettify是格式化代码的让代码更好看
 通过操作方法进行解读搜索 通过操作方法进行解读搜索  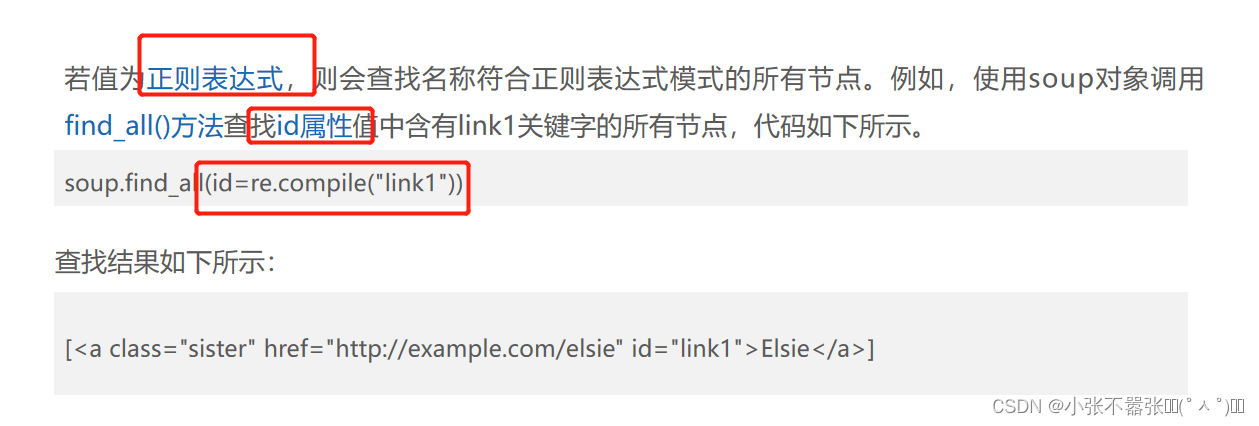    
JSONPath
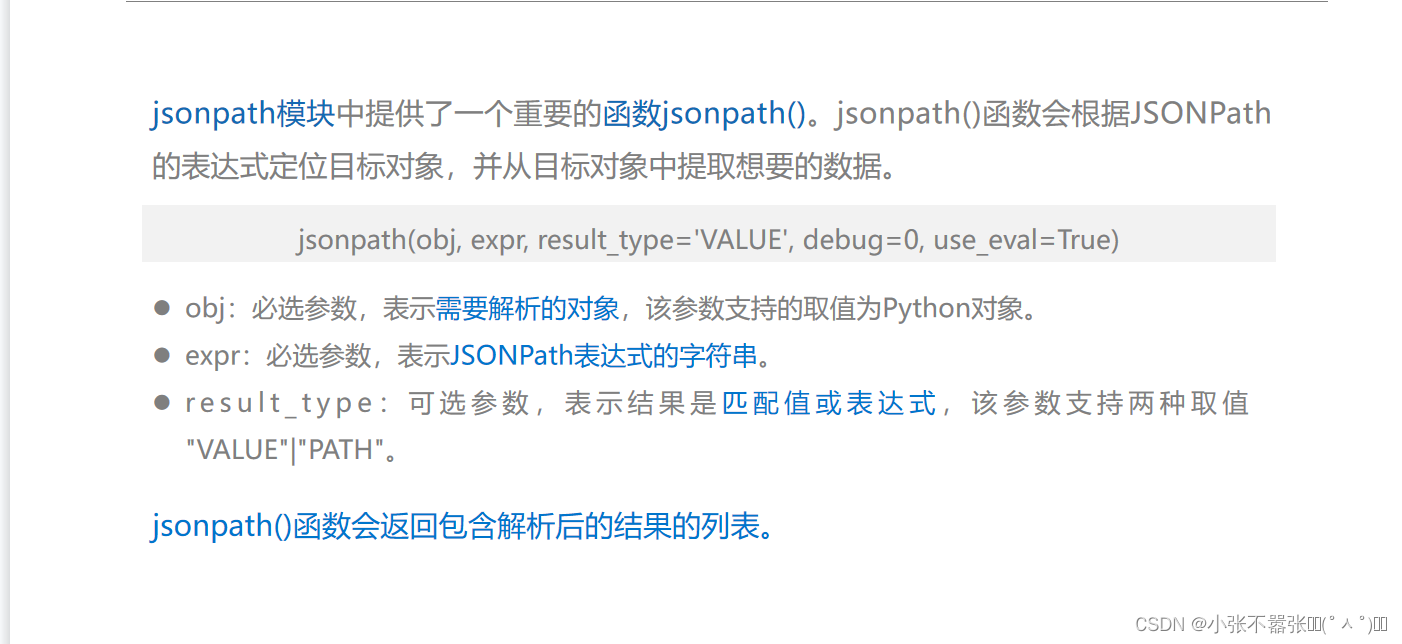
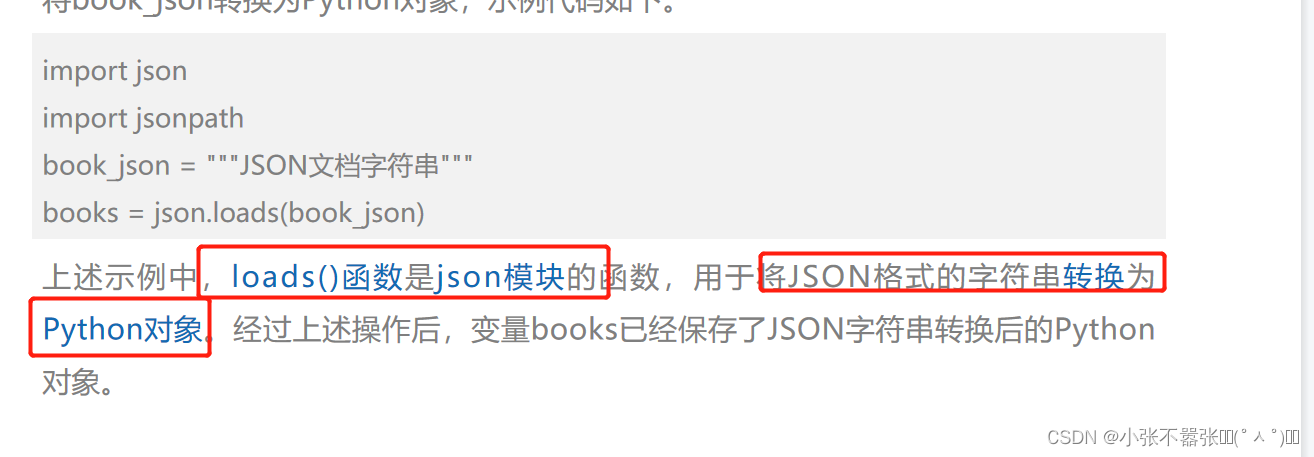
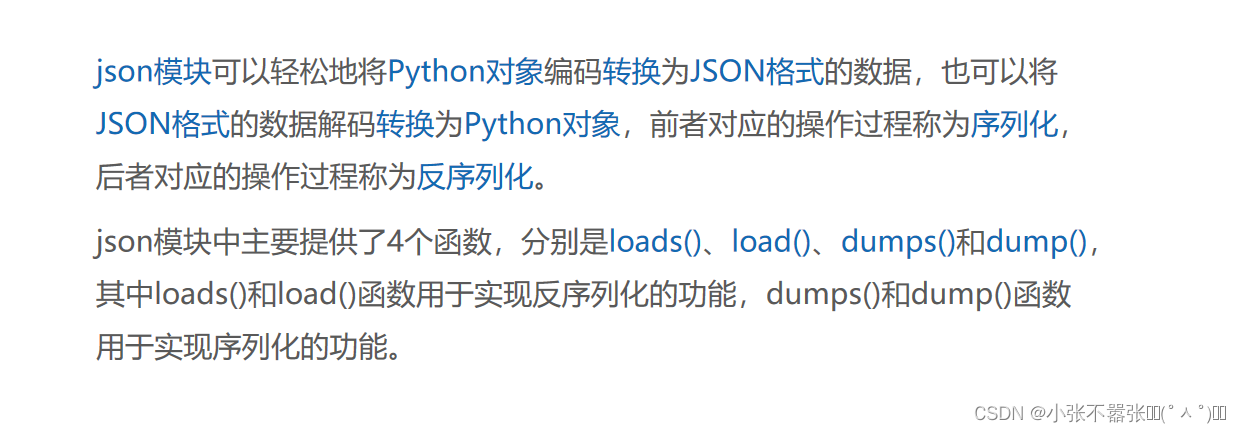
JSONPath 专门用于JSON文档的数据解析。JSONPath的作用类似XPath,它也是以表达式的方式解析数据的,但只能解析JSON格式的数据。
    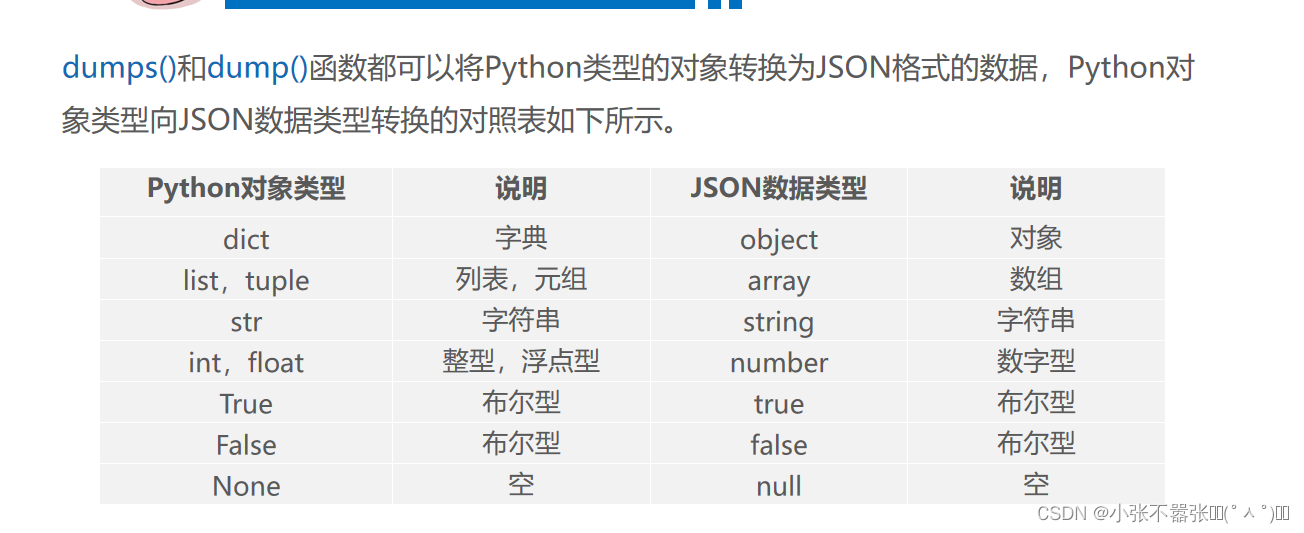
|